

10.9. Производительность мультипроцессорных систем
Эта глава посвящена архитектуре систем, в которых время выполнения больших приложений сокращается за счет использования более чем одного процессора. Самой важной характеристикой производительности такой системы является параметр, определяющий повышение быстродействия работы приложений по сравнению с однопроцессорной системой. Коэффициент ускорения определяется как
![]()
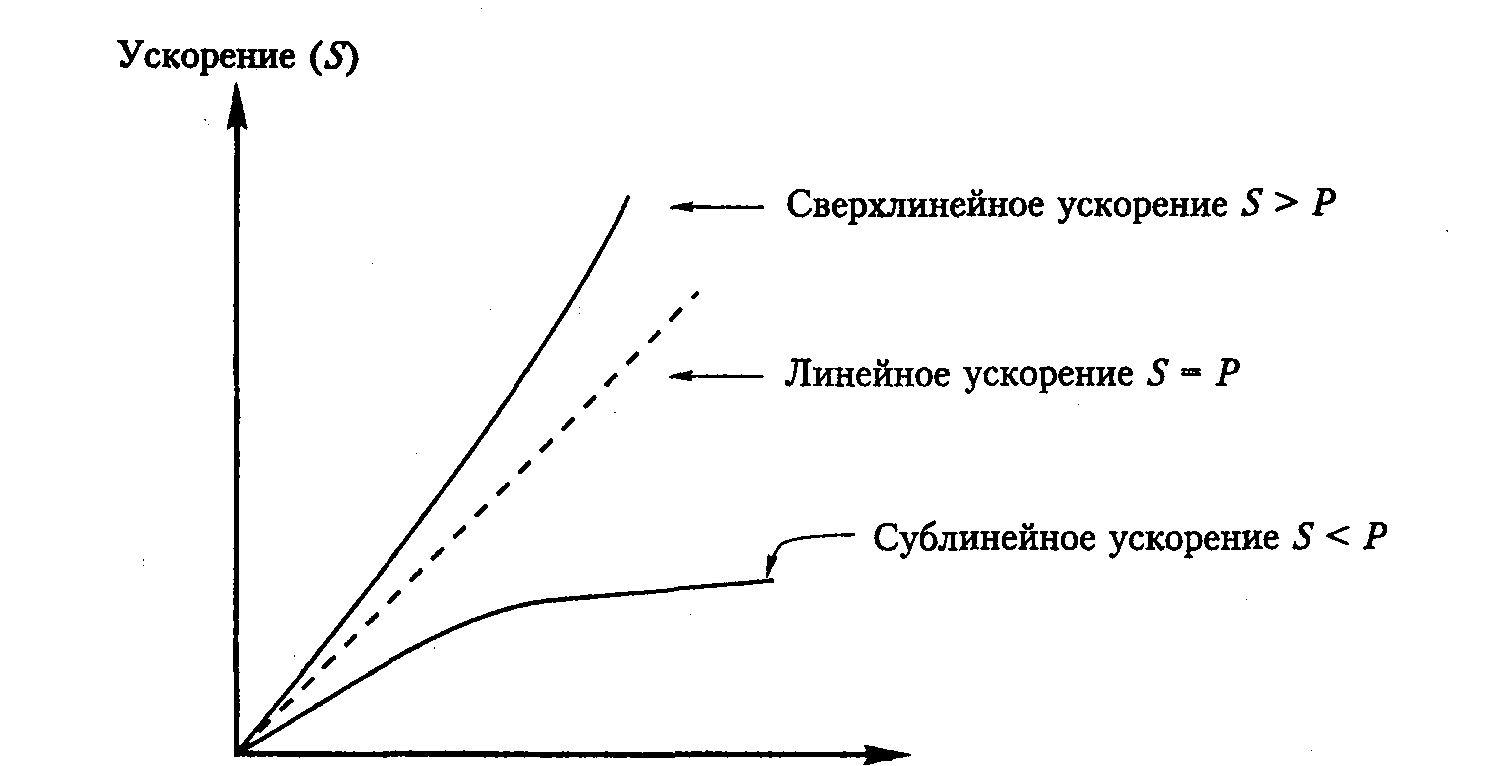
где T1[ и Тp — время, необходимое для выполнения конкретного приложения при использовании одного и Р процессоров соответственно. На рис. 10.19 показаны три возможных варианта коэффициента ускорения в виде функций от количества процессоров в системе. Естественно предположить, что время выполнения программы должно сокращаться пропорционально увеличению числа процессоров. Такой коэффициент линейного ускорения, выражаемый равенством S = Р, является идеальным для масштабируемых систем, однако его очень трудно достичь на практике.
Как следует из предыдущего раздела, не все части программы можно распараллелить для выполнения на нескольких процессорах. Поэтому в ней останутся последовательные фрагменты, время выполнения которых не будет зависеть от количества используемых процессоров. Наличие таких фрагментов и их число в сравнении с общей длиной кода программы ограничивают реально достижимое ускорение.
Немаловажными причинами, по которым так трудно достичь линейного ускорения, являются затраты на инициализацию, синхронизацию, взаимодействие между процессами и согласование кэш-памяти, а также несбалансированность нагрузки. С увеличением размера системы эти затраты также повышаются. Все указанные факторы, за исключением несбалансированности нагрузки, мы обсуждали в предыдущих разделах. Как правило, перед переходом к выполнению очередной группы задач параллельной системе приходится ждать, пока последний процессор завершит текущую задачу. Поэтому при выполнении задачи с большим количеством процессоров важно, чтобы все они достигали точки синхронизации одновременно — тогда нагрузка на процессоры будет сбалансирована.
Количество процессоров (F)
Рис. 10.19. Диаграмма изменения ускорения в мультипроцессорных системах
Коэффициент ускорения для большинства реальных приложений является сублинейной величиной, и начиная с определенного количества процессоров дальнейшего повышения производительности не происходит. Но иногда встречаются приложения, для которых возможно даже сверхлинейное ускорение. В следующем разделе мы приведем пример одного из таких приложений.
10.9.1. Закон Амдала
Рассмотрим параметры, влияющие на производительность мультипроцессорной системы. При усовершенствовании компьютерной системы всегда улучшается какая-то ее часть, но не вся система. Достигаемая при этом степень повышения производительности зависит от влияния «улучшенной» части на работу системы в целом. Данная идея сформулирована Джином Амдалом (Gene Amdahl) и известна как закон Амдала:
![]()
где
Snew — коэффициент ускорения в новой системе с внесенным усовершенствованием;
Senhanced - коэффициент ускорения при использовании только измененной части системы;
fenhanced - часть времени вычислений в старой системе, которая сокращается благодаря усовершенствованию.
Для мультипроцессорных систем приведенный закон можно сформулировать иначе. Пусть f— это та часть вычислений (в терминах времени), которую можно выполнять в параллельном режиме, Р — количество процессоров в системе, а Sp — коэффициент ускорения по сравнению с последовательным выполнением. Тогда формулу для вычисления коэффициента ускорения можно записать так:
![]()
В этой формуле предполагается, что параллельная часть программы выполняется всеми процессорами при идеально сбалансированной нагрузке.
Предположим, что некое приложение запускается в 64-процессорной системе и 70 % его кода может выполняться в параллельном режиме. Тогда величину ожидаемого улучшения можно рассчитать следующим образом:
![]()
Если то же приложение запускается в 16-процессорной системе, ожидаемый коэффициент ускорения становится равным 2,91. Очевидно, что коэффициент ускорения получается много меньшим, чем можно было ожидать при увеличении количества процессоров. Так что нет никакого смысла использовать мощные мультипроцессоры для выполнения приложений, в которых имеются большие последовательные (не поддающиеся распараллеливанию) части. Добиться значительного ускорения можно лишь в том случае, когда последовательные части являются очень маленькими. Например, для приложения, в котором f = 0,95, коэффициент ускорения в описанных выше системах составляет 15,42 и 9,14 соответственно. Закон Амдала, по сути, утверждает, что линейное ускорение недостижимо, поскольку почти во всех приложениях имеются последовательные фрагменты.
До сих пор мы предполагали, что каждый процессор выполняет равную часть параллельных вычислений. Однако нагрузка не обязательно будет так идеально сбалансирована. Если перед переходом к следующему шагу приходится ждать, пока самый медленный процессор закончит свою часть работы, то результаты будут еще хуже, чем в приведенной выше формуле. Однако существуют и такие приложения, где задачи, выполняемые всеми процессорами, могут быть прекращены, как только один из процессоров завершит свою работу. Например, такое необычное поведение свойственно приложениям, основанным на алгоритме модельной «закалки» (улучшающей свойства модели). Предположим, что при разработке СБИС нужно так разместить на ней логические вентили, чтобы общая длина проводников в результирующей схеме получилась минимальной. Для этого необходимо сравнить большое количество разных вариантов размещения. С этой целью наиболее удачное из известных на данный момент размещений назначается всем процессорам в качестве начальной точки для следующей итерации. Далее каждый процессор может использовать свой случайный подход для изменения расположения вентилей в поисках наиболее удачной конфигурации. Как только один из процессоров определит конфигурацию, которая окажется лучше начальной, все вычисления будут остановлены и информация о ней будет передана всем остальным процессорам в качестве начального приближения для следующей итерации. Приложения подобного типа могут показать сверхлинейное ускорение, поскольку в случае их выполнения одним процессором последний может исследовать множество бесперспективных вариантов, пока не найдет хоть один подходящий.