

Понятие информационной системы. Виды информационных систем. Банк данных и его основные компоненты.
Информационные системы – системы, помогающие производить обработку данных какой-либо опред. области. Информация становится данными в момент ее регистрации.
Данные – это информация представленная в формализованном виде, позволяющем передавать или обрабатывать ее при помощи некоторых процессов и технических средств.
Информационные системы:
по средству выполнения: ручные, механизированные или автоматизированные;
Выполняемые функции: инфор-но - поисковые, управляющие, моделирующие, обучающие;
Области применения: медицинские, финансовые и т.д….
Банк данных (БнД) - это одна из форм информационных систем. Банком данных называют систему специальным образом организованных баз данных, программных, технических, языковых и организационно - методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
В этом определении обозначены характерные основные черты БнД: Базы данных создаются обычно для решения не одной, нескольких связанных задач, не одним, а группой пользователей. В БнД имеются специальные средства, облегчающие для пользователей работу с данными (СУБД).
Основные требования, предъявляемые к БнД:
- адекватность отображения предметной области (полнота, целостность и непротиворечивость данных, актуальность информации;
- возможность взаимодействия пользователей разных категорий, высокая эффективность доступа к данным;
- дружелюбность интерфейсов, малое время на обучение;
- обеспечение секретности и разграничение доступа к данным для разных пользователей;
- надежность хранения и защита данных.
Ядром БнД является база данных (БД). База данных – это поименованная совокупность взаимосвязанных данных, находящихся под управлением СУБД. Метаинформация включает в себя описание структуры БД (схемы и подсхемы), модель предметной области, информацию о пользователях и их правах, описание формы входных и выходных документов.
Централизованное хранилище метаинформации называется словарем данных. Особенно большое значение имеют словари данных в системах автоматизированного проектирования ИС. Администратором БД являются лицо или группа лиц, отвечающих за выработку требований к БД, ее созданию, проектированию, сопровождению и эффективному использованию. Вычислительная система- совокупность взаимосвязанных и согласованно действующих Эвм или процессоров и других устройств, обеспечивающих автоматизацию процессов приема, обработки и выдачи информации потребителям. Программные средства СУБД подразделяют на:
ядро СУБД, которое обеспечивает ввод, вывод , обработку и хранение данных в БД;
трансляторы, обеспечивающие перевод языка СУБД на некоторый внутренний язык, используемый ядром;
утилиты, которые служат для настройки системы, отладки программ, архивирования и восстановления БД, сбора статистики;
прикладные программы, которые служат для обработки запросов к БД. Операционную систему иногда включают в состав банка данных, так как СУБД тесно взаимодействует с ОС в процессе работы.
Языковые средства обеспечивают взаимодействие пользователей с БД. Язык обычно включает в себя средства спецификации данных, отчетов; экранных форм, запросов и процедурные средства для описания последовательности решения задач. Язык СУБД может быть универсальным языком программирования с включением специфического подъязыка для работы с БД, например, языки универсальных систем программирования DELPHI, Visual Basic 5,Visual C++ включают язык SQL. Другие СУБД имеют специализированные языки,например, dBASE, FoxPro, Clipper, Paradox, Access. Некоторые СУБД используют только язык SQL (SQL- серверы).
Технические средства включают в себя универсальную ЭВМ, периферийные средства ввода- вывода информации, средства работы в сети.
Организационно - методические средства – это инструкции, методические и регламентные материалы для пользователей.
Персонал - это специалисты, которые обеспечивают создание, работу и развитие БнД.
Модели представления данных.
Хранимые в базе данные имеют определенную логическую структуру, те описываются моделью представления данных, поддерживаемой СУБД: иерархические, сетевые и реляционные. Кроме того появились также постреляционная, многомерная, объектно-ориентированная.
Иерархические базы данных
И ерархические
базы данныхприменялись
в начале 60-х годов. Они построены в виде
обычного дерева. Данные здесь делятся
на две категории: главные
и
подчиненные.
Таким
образом, один тип объекта является
главным, а остальные, находящиеся на
более низких ступенях иерархии, —
подчиненными (рис. 1.1).
ерархические
базы данныхприменялись
в начале 60-х годов. Они построены в виде
обычного дерева. Данные здесь делятся
на две категории: главные
и
подчиненные.
Таким
образом, один тип объекта является
главным, а остальные, находящиеся на
более низких ступенях иерархии, —
подчиненными (рис. 1.1).
Наивысший в иерархии объект называется корневым, остальные объекты носят название зависимых объектов. БД, организованная по иерархическому принципу, удобна для работы с информацией, которая соответственным образом упорядочена. В остальных случаях работа с такой моделью будет достаточно сложной.
Достоинствами иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархическая модель данных удобна для работы с иерархически упорядоченной информацией.
Недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя. Примеры: зарубежные системы IMS, PC/Focus, Team-Up и Data Edge, а также отечественные системы Ока, ИНЭС и МИРИС;
Сетевые базы данных
С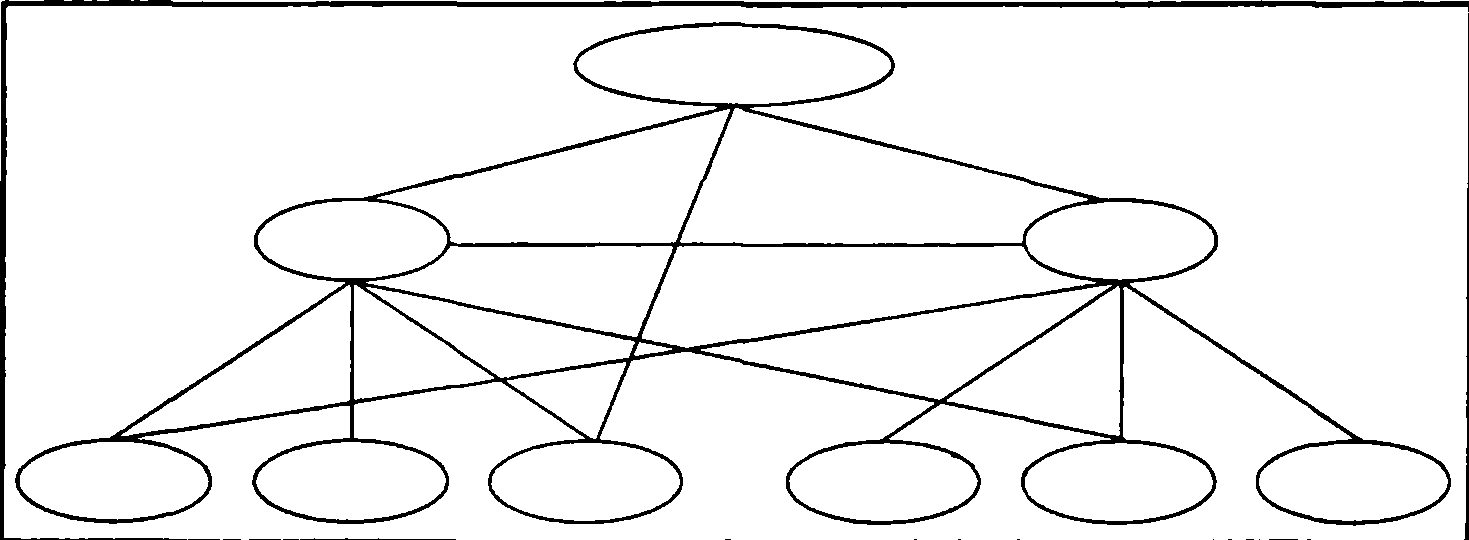 етевые
базы данныхначали
применяться практически одновременно
с иерархическими. В этих базах данных
любой объект может быть как главным,
так и подчиненным (рис. 1.2).
етевые
базы данныхначали
применяться практически одновременно
с иерархическими. В этих базах данных
любой объект может быть как главным,
так и подчиненным (рис. 1.2).
Таким образом, в сетевой модели базы данных каждый объект может иметь сколько угодно связей с другими объектами. Из-за сложности представления данных в таком виде от сетевой модели базы данных в большинстве случаев также пришлось отказаться.
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей.
Недостатком сетевой модели данных является высокая сложность и жесткость схемы БД, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в БД обычным пользователем. Кроме того, в сетевой модели данных ослаблен контроль целостности связей вследствие допустимости установления произвольных связей между записями. Системы на основе сетевой модели не получили широкого распространения на практике. Наиболее известными сетевыми СУБД являются следующие: IDMS, db_VistaIII, СЕТЬ, СЕТОР и КОМПАС;
Реляционные базы данных
Именно реляционные базы данных (от англ. relation — отношение) стали широко использоваться в программировании начиная с 70-х годов. В таких базах данных объекты и взаимосвязи между ними представляются в виде прямоугольных таблиц, состоящих из строк и столбцов (рис. 1.3).
К аждая
таблица здесь представляет собой объект
базы данных. Такую базу данных легче
всего можно реализовать на компьютере.
В дальнейшем мы будем рассматривать
именно реляционные базы данных.
аждая
таблица здесь представляет собой объект
базы данных. Такую базу данных легче
всего можно реализовать на компьютере.
В дальнейшем мы будем рассматривать
именно реляционные базы данных.
Итак, таблицы, которые составляют базу данных, находятся на магнитном диске в отдельной папке. Папка в целом является базой данных, а входящие в нее таблицы хранятся в виде отдельных файлов. С этими файлами можно производить произвольные операции, которые допускаются операционной системой. Большинство приложений Windows при попытке обращения к одному файлу сразу несколькими приложениями выдают сообщение об ошибке совместного доступа. Для таблиц базы данных такое ограничение крайне неудобно, поэтому им свойственна особенность, которая заключается в том, что несколько приложений могут получить доступ к файлу таблицы одновременно. Такой режим доступа называется многопользовательским.
Столбцы таблицы обычно называют полями, а строки — записями. К полям таблицы предъявляются следующие требования:
■ поле должно иметь уникальное имя в пределах одной таблицы;
■ поле должно содержать данные только одного заранее определенного типа;
■ любая таблица должна иметь как минимум одно поле.
Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования. Проблемы же эффективности обработки данных этого типа оказались технически вполне разрешимыми.
Основными недостатками реляционной модели являются следующие: отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
Примерами зарубежных реляционных СУБД для ПЭВМ являются следующие: dBaseIII Plus и dBase IV (фирма Ashton-Tate), DB2 (IBM), R:BASE (Microrim), FoxPro ранних версий и FoxBase (Fox Software), Paradox и dBASE for Windows (Borland), FoxPro более поздних версий, Visual FoxPro и Access (Microsoft), Clarion (Clarion Software), Ingres (ASK Computer Systems) и Oracle (Oracle).
Постреляционная модель.
Представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в записях таблиц. Постреляционная модель данных допускает многозначные поля — поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу. На длину и количество полей не накладывается требование постоянства, те таблица имеет большую гибкость. Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки.
Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных. Примерами: uniVers, Bubba и Dasdb;
Многомерная.
Узкоспециализированная, предназначена для интерактивной аналитической обработки информации. Агрегатируемость данных означает рассмотрение информации на различных уровнях ее сообщения. Историчность – обеспечение высокого уровня статичности (неизменности) собственно данных и их взаимосвязей, и обязательность привязки ко времени. Прогнозируемость – задание функции прогнозирования и применение ее к различным временным интервалам. Измерение – множество однотипных данных, играют роль индексов, служащих для идентификации конкретных значений в ячейках. Ячейка – показатель, это поле, значение которого однозначно определяется фиксированным набором измерений. Существуют схемы гиперкуб, поликубическая ( несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней) и гиперкубическая ( все показатели определяются одним и тем же набором измерений). Достоинства: удобство и эффективность аналитической обработки больших объемов данных, связывание со временем. Недостатки: громоздкость для простейших задач обычной оперативной обработки информации. Примерами являются media multi-matrix (speed ware), oracle express serveк (oracle), cache (intersystem).
Объектно-ориентированная модель.
Структура модели графически представима в виде дерева, узлами которого являются объекты. Логическая структура схожа с иерархической, кроме методов манипулирования данными. Инкапсуляция – ограничивает область видимости имени свойства пределами того объекта, в котором оно определено. Наследование - распространяет область видимости свойства на всех потомков объекта. Полиморфизм – способность 1 и того же программного кода работать с разнотипными данными. Достоинства : возможность отображения информации о сложных связях объекта, идентификация отдельной записи и определение для нее функции ее обработки. Недостатки: высокая понятийная сложность, неудобство обработки данных и низкая скорость выполнения запросов. Примеры: poet (poet software), odb-jupiter (научно- исследовательский центр «Интеллект Плюс»), oris, orion.
СУБД, назначение и виды. Основные классификационные признаки и классификация СУБД.
Система управления базами данных (СУБД) — это комплекс языковых и программных средств, предназначенный для создания, ведения и совместного использования БД многими пользователями.
Функции СУБД (назначение и возможности)
1. Хранение, извлечение и обновление данных. СУБД должна предоставлять пользователям возможность сохранять, извлекать и обновлять данные в базе данных. Это самая фундаментальная функция СУБД. Причем, способ реализации этой функции должен быть скрыт от конечного пользователя.
2. Каталог, доступный конечным пользователям. СУБД должна иметь доступный конечным пользователям каталог, в котором хранится описание элементов данных. Ключевой особенностью архитектуры ANSI/SPARC является наличие интегрированного системного каталога с данными о схемах, пользователях, приложениях и т. д. Предполагается, что каталог доступен как пользователям, так и функциям СУБД. Системный каталог или словарь данных является хранилищем информации, описывающей данные в базе данных (метаданные). В зависимости от типа используемой СУБД количество информации и способ ее применения могут варьироваться. Обычно в системном каталоге хранятся следующие сведения:
- имена, типы и размеры элементов данных;
- имена связей;
- накладываемые на данные ограничения поддержки целостности;
- имена санкционированных пользователей;
- внешняя, концептуальная и внутренняя схемы и отображения между ними;
- статистические данные (частота транзакций, счетчик обращения к объектам базы данных).
Системный каталог позволяет достичь определенных преимуществ:
- информация о данных может быть централизованно собрана и сохранена, что позволит контролировать доступ к этим данным, как и к любому другому ресурсу;
- можно определить смысл данных, что поможет другим пользователям понять их назначение;
- упрощается сообщение, так как сохраняются точные определения смысла данных. В системном каталоге также могут быть указаны один или несколько пользователей, которые являются владельцами данных или обладают правом доступа к ним;
- благодаря централизованному хранению избыточность и противоречивость описания отдельных элементов данных могут быть легко обнаружены;
- внесенные в базу данных изменения могут быть запротоколированы;
- последствия любых изменений могут быть определены еще до их внесения, поскольку в системном каталоге зафиксированы все существующие элементы данных, установленные между ними связи, а также все их пользователи;
- меры обеспечения безопасности могут быть дополнительно усилены;
- появляются новые возможности организации поддержки целостности данных;
- может выполняться аудит сохраняемой информации.
3. Поддержка транзакций. СУБД должна иметь механизм, который гарантирует выполнение либо всех операций обновления данной транзакции, либо ни одной из них. Транзакция представляет собой набор действий, выполняемых отдельным пользователем или прикладной программой с целью доступа или изменения содержимого базы данных (например, удаление сведений о сотруднике из база данных и передача ответственности за всю курируемую им работу другому сотруднику). Если во время выполнения транзакции произойдет сбой, например, из-за выхода из строя компьютера, база данных попадет в противоречивое состояние, поскольку некоторые изменения уже будут внесены, а остальные – нет. В этом случае все частичные изменения должны быть отменены для возвращения базы данных в исходное непротиворечивое состояние.
4. Сервисы управления параллельностью. СУБД должны иметь механизм, который гарантирует корректное обновление базы данных при параллельном выполнении операций обновления многими пользователями. Одна из основных целей создания и использования СУБД заключается в том, чтобы множество пользователей могло осуществлять доступ к совместно обрабатываемым данным. Параллельный доступ сравнительно просто организовать, если все пользователи выполняют только чтение данных. Конфликтные ситуации с нежелательными последствиями легко могут возникнуть, когда два и более пользователей пытаются обновить данные. СУБД должна гарантировать, что при одновременном доступе к базе данных многих пользователей таких конфликтов не произойдет.
5. Сервисы восстановления. СУБД должна предоставлять средства восстановления базы данных на случай какого-либо ее повреждения или разрушения. Сбой может произойти в результате выхода из строя системы или запоминающего устройства, возможны ошибки аппаратного и программного обеспечения, которые могут привести к останову СУБД. К тому же пользователь может потребовать отмены операции. Во всех подобных случаях СУБД должна предоставить механизм восстановления базы данных и возврата к ее непротиворечивому состоянию. Сервисы восстановления тесно связаны с управлением транзакциями.
6. Сервисы контроля доступа к данным. СУБД должна иметь механизм, гарантирующий возможность только санкционированного доступа к базе данных. Иногда требуется скрыть некоторые хранимые в базе данных сведения от других пользователей. Кроме того, базу данных следует защитить от любого несанкционированного доступа. Термин безопасность относится к защите базы данных от преднамеренного или случайного несанкционированного доступа.
7. Поддержка обмена данными. СУБД должна обладать способностью к интеграции с коммуникационным программным обеспечением. Большинство пользователей осуществляют доступ к базе данных с помощью терминалов. Иногда эти терминалы подсоединены непосредственно к компьютеру с СУБД. В других случаях терминалы могут находиться на значительном удалении и обмениваться данными с компьютером, на котором располагается СУБД, через сеть. В любом случае СУБД получает запросы в виде сообщений обмена данными (communications messages) и аналогичным образом отвечает на них. Такая передача данных управляется менеджером обмена данными. Хотя этот менеджер не является частью собственно СУБД, тем не менее, чтобы быть коммерчески жизнеспособной, любая СУБД должна обладать способностью интеграции с разнообразными существующими менеджерами обмена данными. Даже СУБД для персональных компьютеров должны поддерживать работу в локальной сети, чтобы вместо нескольких баз данных для каждого пользователя можно было установить одну централизованную базу данных и использовать ее как общий ресурс для всех пользователей. При этом предполагается, что не база данных должна быть распределена в сети, а удаленные пользователи должны иметь возможность доступа к централизованной базе данных. Такая топология называется распределенной обработкой.
8. Службы поддержки целостности данных. СУБД должна обладать инструментами контроля за тем, чтобы данные и их изменения соответствовали заданным правилам. Целостность базы данных означает корректность и непротиворечивость хранимых данных. Она может рассматриваться как еще один тип защиты базы данных, но в более широком смысле целостность связана с качеством самих данных. Целостность обычно выражается в виде ограничений или правил сохранения непротиворечивости данных (например, сотрудник не имеет права работать больше, чем на полторы ставки в данной организации).
9. Службы поддержки независимости от данных. СУБД должна обладать инструментами поддержки независимости программ от фактической структуры базы данных. Обычно она достигается за счет реализации механизма поддержки представлений или подсхем. Физическая независимость от данных достигается достаточно просто, что нельзя сказать о логической независимости от данных. Как правило, система легко адаптируется к добавлению нового объекта, атрибута или связи, но не к их удалению. В некоторых системах вообще запрещается вносить любые изменения в уже существующие компоненты логической схемы.
10. Вспомогательные службы. СУБД должна предоставлять некоторый набор различных вспомогательных служб. Вспомогательные утилиты обычно предназначены для оказания помощи администратор БД (АБД) в эффективном администрировании базы данных. Приведем примеры таких утилит:
- утилиты импортирования, предназначенные для загрузки данных из плоских файлов или других СУБД, а также утилиты экспортирования, которые служат для выгрузки базы данных в плоские файлы или другие СУБД;
- средства мониторинга, предназначенные для отслеживания характеристик функционирования и использования базы данных;
- программы статистического анализа, позволяющие оценить производительность или степень использования базы данных;
- инструменты реорганизации индексов, предназначенные для перестройки индексов и обработки случаев их переполнения;
- инструменты сборки мусора и перераспределения памяти для физического устранения удаленных записей с запоминающих устройств, объединения освобожденного пространства и перераспределения памяти в случае необходимости.
В качестве основных классификационных признаков СУБД можно использовать следующие: вид программы, характер использования, модель данных.
К СУБД относятся следующие основные виды программ.
- Полнофункциональные СУБД (ПФСУБД). К ПФСУБД относятся, например, такие пакеты как: Clarion Database Developer, DataBase, Dataplex, dBase IV, Microsoft Access, Microsoft FoxPro и Paradox R:BASE. ПФСУБД имеют развитый интерфейс, позволяющий с помощью команд меню выполнять основные действия с БД: создавать и модифицировать структуры таблиц, вводить данные, формировать запросы, разрабатывать отчеты, выводить их на печать и т. п. Для создания запросов и отчетов не обязательно программирование, а удобно пользоваться языком QBE (Query By Example — формулировки запросов по образцу). Для обеспечения доступа к другим БД или к данным SQL-серверов полнофункциональные СУБД имеют факультативные модули.
- Серверы БД. Предназначены для организации центров обработки данных в сетях ЭВМ. Серверы БД реализуют функции управления базами данных, запрашиваемые другими (клиентскими) программами обычно с помощью операторов SQL. Примерами серверов БД являются следующие программы: NetWare SQL (Novell), MS SQL Server (Microsoft), InterBase (Borland), SQLBase Server (Gupta), Intelligent Database (Ingress).
- Клиенты БД. В роли клиентских программ для серверов БД в общем случае могут использоваться различные программы: ПФСУБД, электронные таблицы, текстовые процессоры, программы электронной почты и т. д. При этом элементы пары «клиент — сервер» могут принадлежать одному или разным производителям программного обеспечения. Примером такого соединения является случай, когда одна из полнофункциональных СУБД играет роль сервера, а вторая СУБД (другого производителя) — роль клиента. Так, для сервера БД SQL Server (Microsoft) в роли клиентских (фронтальных) программ могут выступать многие СУБД, такие как: dBASE IV, Blyth Software, Paradox, DataBase, Focus, 1-2-3, MDBS III, Revelation и др.
- Средства разработки программ работы с БД. Используются для создания пользовательских приложений по работе с БД, серверов БД и их отдельных компонентов, клиентских программ. К средствам разработки программ для работы с БД относятся системы программирования (Clipper, Delphi, Power Builder (Borland), Visual Basic (Microsoft) и пр.); библиотеки программ для различных языков программирования; пакеты автоматизации разработок (SILVERRUN (Computer Advisers Inc.), S-Designor (SDP и Powersoft), ERwin (LogicWorks), Rational Rose и пр.).
- Дополнительные средства. Используются для управления данными и организации обслуживания БД (например, мониторы транзакций).
Классификация СУБД по характеру использования.
- Персональные СУБД обеспечивают возможность создания персональных БД и недорогих приложений, работающих с ними. Персональные СУБД или разработанные с их помощью приложения зачастую могут выступать в роли клиентской части многопользовательской СУБД. К персональным СУБД относятся Visual FoxPro, Paradox, Clipper, dBase, Access и др.
- Многопользовательские СУБД включают в себя сервер БД и клиентскую часть и, как правило, могут работать в неоднородной вычислительной среде (с разными типами ЭВМ и операционными системами). К многопользовательским СУБД относятся, например, СУБД Oracle и Informix.
Классификация СУБД по используемой модели данных: иерархические, сетевые, реляционные, постреляционные, многомерные, объектно-ориентированные. Некоторые СУБД могут одновременно поддерживать несколько моделей данных.
Реляционная и постреляционная модели данных. Сравнительная характеристика. Реляционная модель
Реляционная модель данных предложена сотрудником фирмы IBM Эдгаром Коддом и основывается на понятии отношение (relation). Отношение представляет собой множество элементов, называемых кортежами. Подробно теоретическая основа реляционной модели данных рассматривается в следующем разделе. Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица. Таблица имеет строки (записи) и столбцы (колонки). Каждая строка таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы соответствуют кортежи, а столбцам - атрибуты отношения. С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно: деление одного объекта (явления, сущности, системы и проч.), информация о котором хранится в таблице, на множество подобъектов, каждому из которых соответствует строка или запись таблицы. При этом каждый из подобъектов имеет одинаковую структуру или свойства, описываемые соответствующими значениями полей записей. Например, таблица может содержать сведения о группе обучаемых, о каждом из которых известны следующие характеристики: фамилия, имя и отчество, пол, возраст и образование. Поскольку в рамках одной таблицы не удается описать более сложные логические структуры данных из предметной области, применяют связывание таблиц. Физическое размещение данных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов. Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования. Проблемы же эффективности обработки данных этого типа оказались технически вполне разрешимыми. Основными недостатками реляционной модели являются следующие: отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей. Примерами зарубежных реляционных СУБД для ПЭВМ являются следующие: dBaseIII Plus и dBase IY (фирма Ashton-Tate), DB2 (IBM), R:BASE (Microrim)… К отечественным СУБД реляционного типа относятся системы: ПАЛЬМА (ИК АН УССР), а также система HyTech (МИФИ). Заметим, что последние версии реляционных СУБД имеют некоторые свойства объектно-ориентированных систем. Такие СУБД часто называют объектно-реляционными. Примером такой системы можно считать продукты Oracle 8.x. Системы предыдущих версий вплоть до Oracle 7.x считаются "чисто" реляционными.
Постреляционная модель
Классическая реляционная модель предполагает неделимость данных, хранящихся в полях записей таблиц. Это означает, что информация в таблице представляется в первой нормальной форме. Существует ряд случаев, когда это ограничение мешает эффективной реализации приложений. Постреляционная модель данных представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в записях таблиц. Постреляционная модель данных допускает многозначные поля - поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу. На рис. 2.6 на примере информации о накладных и товарах для сравнения приведено представление одних и тех же данных с помощью реляционной (а) и постреляционной (б) моделей. Таблица INVOICES (накладные) содержит данные о номерах накладных (INVNO) и номерах покупателей (CUSTNO). В таблице INVOICE.ITEMS (накладные-товары) содержатся данные о каждой из накладных: номер накладной (INVNO), название товара (GOODS) и количество товара (QTY). Таблица INVOICES связана с таблицей INVOICE.ITEMS по полю INVNO.
|
|

Рис. 2.6. Структуры данных реляционной и постреляционной моделей
Как видно из рисунка, по сравнению с реляционной моделью в постреляционной модели данные хранятся более эффективно, а при обработке не требуется выполнять операцию соединения данных из двух таблиц. Для доказательства на рис. 2.7 приводятся примеры операторов SELECT выбора данных из всех полей базы на языке SQL для реляционной (а) и постреляционной (б) моделей. Помимо обеспечения вложенности полей постреляционная модель поддерживает ассоциированные многозначные поля (множественные группы). Совокупность ассоциированных полей называется ассоциацией. При этом в строке первое значение одного столбца ассоциации соответствует первым значениям всех других столбцов ассоциации. Аналогичным образом связаны все вторые значения столбцов и т. д.
|
а) SELECT INVOICES.INVNO, CUSTNO, GOODS, QTY FROM INVOICES, INVOICE.ITEMS WHERE INVOICES.INVNO=INVOICE.1TEMS.INVNO; б) SELECT INVNO, CUSTNO, GOODS, QTY FROM INVOICES; |
Рис. 2.7. Операторы SQL для реляционной и постреляционной моделей
На длину полей и количество полей в записях таблицы не накладывается требование постоянства. Это означает, что структура данных и таблиц имеют большую гибкость. Поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД механизмов, подобных хранимым процедурам в клиент-серверных системах. Для описания функций контроля значений в полях имеется возможность создавать процедуры (коды конверсии и коды корреляции), автоматически вызываемые до или после обращения к данным. Коды корреляции выполняются сразу после чтения данных, перед их обработкой. Коды конверсии, наоборот, выполняются после обработки данных. Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки. Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных. Рассмотренная нами постреляционная модель данных поддерживается СУБД uniVers. К числу других СУБД, основанных на постреляционной модели данных, относятся также системы Bubba и Dasdb.
Обзор средств Delphi, используемых для создания, разработки и эксплуатации приложений БД.
BDE Administrator – утилита для установки псевдонимов (имен) баз данных, параметров БД и драйверов баз данных на конкретном компьютере. При работе с БД из приложения, созданного с помощью Delphi, доступ к базе данных производится по ее псевдониму. Параметры определяемой псевдонимом БД, действуют только для этой БД; параметры, установленные для драйвера БД, действуют для всех баз данных, использующих драйвер. Кроме того, можно произвести установку таких общих для всех БД параметров, как формат даты и времени, форматы представления числовых значений, используемый языковый драйвер и т.д.
Database Desktop (DBD) – средство для создания, изменения и просмотра БД. Эта утилита прежде всего ориентирована на работу с таблицами локальных СУБД, например Paradox. Можно с некоторыми ограничениями создавать и просматривать таблицы баз данных, работающих под управлением серверов: InterBase, MS SQL Server, Oracle. DBD позволяет программисту возможность сформировать запрос к БД методом QBE (Query By Example – запрос по образцу).
SQL Explorer – универсальная утилита, совмещающая многие функции BDE Administrator и DBD. С ее помощью можно создавать и просматривать псевдонимы БД, просматривать структуры и содержимое таблиц БД, формировать запросы к БД на языке SQL, создавать словари данных (шаблоны полей таблиц).
SQL Monitor – средство для трассировки выполнения SQL-запросов.
Невизуальные компоненты для работы с БД – служат для соединения приложения с таблицами БД в локальных и распределенных системах. Они расположены на странице Data Access палитры компонентов. С помощью невизуальных компонентов осуществляется подключение к базам данных, формирование запросов к ним, манипулирование таблицами.
Визуальные компоненты для работы с БД – предназначены для визуализации записей наборов данных или их отдельных полей. Эти компоненты расположены на странице Data Controls палитры компонентов. Они служат основным инструментом разработки пользовательского интерфейса доступа к данным.
Особенности программ для работы с БД.
Характерной особенностью созданных с помощью Delphi программ для работы с БД является непременное использование в них BDE (процессор реляционной базы данных Borland Database Engine, включенный в состав Delphi), которая осуществляет роль связующего моста между программой и БД.
|
|
|
|
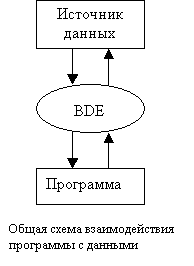
BDE берет на себя всю низкоуровневую работы по обеспечению клиентской программы нужными ей данными, поэтому в общем случае взаимодействие программы с данными происходит следующим образом:
BDE не является частью программы. В зависимости от типа СУБД она может размещаться на машине клиента или сервера. Обычно между программой и BDE располагается слой компонентов, существенно упрощающих разработку программ.
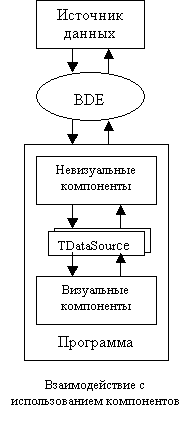
Невизуальные компоненты осуществляют непосредственную работу с BDE, и три из них (TTable, TQuery, TStoredProc) служат наборами данных, в то время как визуальные компоненты отображают поставляемые им данные и служат для создания удобного интерфейса пользователя. Между наборами данных и визуальными компонентами обязательно располагаются компоненты TDataSource, играющие роль клапанов, открывающих или закрывающих потоки данных, которыми обмениваются источники с визуальными компонентами (см рис.).
Понятие ключа (первичный, составной, внешний) и индексирования. Назначения ключа.
Поля таблицы могут определять так называемые ключи и индексы. Ключ — это комбинация нескольких полей, данные в которых однозначно определяют запись таблицы.
Ключи бывают простыми и сложными (составными). Простой ключ — это ключ, состоящий из одного поля. Сложный или составной ключ включает в себя данные нескольких полей. Данные простого ключа должны быть уникальными. Составной ключ может иметь повторы в отдельных полях, но не во всех одновременно.
Соответственно поля, по которым строится ключ, называются ключевыми полями. В каждой таблице может быть только один ключ. Ключ иногда называют первичным ключом или главным индексом.
Первичный ключ (ключ отношений, ключевой атрибут) называется атрибут отношения, однозначно идентифицирующий каждый из его кортежей. Кроме того, ключ предназначен для более быстрого выполнения запросов к базе данных. По ключевым полям организуется связь между таблицами базы данных. Сведения о ключе таблицы могут храниться как вместе с данными таблицы, так и в отдельном файле. Этот файл имеет такое же имя, что и файл таблицы, но другое расширение. Ключевой файл содержит значения ключа, которые располагаются в определенном порядке. Для каждого из значений ключа имеется уникальная ссылка, которая указывает местоположение соответствующей записи в файле таблицы.
Возможны случаи, когда отношение имеет несколько комбинаций атрибутов, однозначно определяющейся, все эти комбинации являются возможным ключом отношения, любой из них мб выбран как первичный.
Ключи используют для: исключения дублирования значений в ключевых атрибутах, упорядочения кортежей ( возрастание или убывание, либо смешанный), ускорения работы с кортежами отношения, организации связывания таблиц.
Пусть в отношении а имеется не ключевой атрибут а1, значения которого являются значением ключевого атрибута б1 в другом отношении б, тогда атрибут а1 отношения а есть внешний ключ, с помощью него устанавливается связь между отношениями.
Индекс — это комбинация нескольких полей, которые служат для быстрого доступа к необходимой информации.
Основным отличием индекса от ключа является то, что поля индекса могут определять не одну, а несколько записей. Таким образом, индекс не всегда однозначно определяет запись в таблице базы данных.
Индексы так же, как и ключи, могут быть простыми и составными. Простой индекс состоит из одного поля, а составной — из нескольких полей. Поля, по которым строится индекс, называют индексными полями. Процесс создания индекса называется индексированием таблицы.
В зависимости от используемого типа базы данных, индексы могут храниться как вместе с данными, так в отдельных файлах. Индекс используется для увеличения скорости доступа к данным, для быстрой сортировки данных таблицы, а также для поддержки других функций, которые будут рассмотрены далее.
В отличие от ключа, который является уникальным в каждой таблице, индексов в ней может быть несколько. Это в первую очередь необходимо для быстрой сортировки по нужному полю или полям. Если эти поля проиндексированы, то сортировка по ним будет выполнена значительно быстрее, чем по обычным полям. В любой момент времени можно активировать любой из индексов таблицы. Именно по активному (текущему) индексу обычно будет выполняться сортировка записей таблицы. Следует, однако, заметить, что, несмотря на наличие нескольких индексов, таблица может не иметь текущего индекса. Вообще говоря, поведение индексов и ключей зависит от типа используемой базы данных. Так, например, в таблицах Paradox ключ автоматически является главным индексом, который не имеет имени. В то же время в таблицах dBase ключ в принципе не создается, вместо него используется один из индексов. Но в общем случае ключевые поля обычно автоматически индексируются. Индексные файлы, создаваемые по ключевым полям таблицы часто называются файлами первичных индексов, для неключевых полей – вторичными ( пользовательскими).
Операция связывания таблиц БД. Назначение связывания и виды связи.
Связывание таблиц на уровне приложений:
Необходимо к свойству master source подчинить таблицу. Выбираем значение data source принадлежащее главной таблице в этой связи.
Раскрыть редактор полей, в правой части, свойство ms откроем редактор связей, выбрать available Indexes. Data fields появится имя поля связи, а на панели master fields необходимо получить тоже самое поле.
При проектировании реальных БД информацию обычно размещают в нескольких таблицах. В реляционных СУБД для указания связей таблиц производят операцию их связывания. Многие СУБД при связывании таблиц автоматически выполняют контроль целостности вводимых в базу данных в соответствии с установленными связями. В конечном итоге это повышает достоверность хранимой в БД информации. Кроме того, установление связи между таблицами облегчает доступ к данным. Связывание таблиц при выполнении таких операций как поиск просмотр, редактирование, выборка и подготовка отчетов обычно обеспечивает возможность обращения к произвольным полям связанных записей. Это уменьшает количество явных обращений к таблицам данных и число манипуляций в каждой из них.
Основные виды связывания таблиц:
Между таблицами могут устанавливаться бинарные (между двумя таблицами) тернарные (между тремя таблицами) и, в общем случае, n-арные связи. Наиболее часто встречающиеся бинарные связи. При связывании двух таблиц выделяют основную и дополнительную (подчиненную) таблицы. Логическое связывание таблиц производится с помощью ключа связи Ключ связи, по аналогии с обычным ключом таблицы, состоит из одного или нескольких полей, которые в данном случае называют полями связи (ПС). Суть связывания состоит в установлении соответствия полей связи основной и дополнительной таблиц. Поля связи основной таблицы могут быть обычными и ключевыми. В качестве полей связи подчиненной таблицы чаще всего используют ключевые поля. В зависимости от того, как определены поля связи основной и дополнительной таблиц (как соотносятся ключевые поля с полями связи), между двумя таблицами в общем случае могут устанавливаться следующие четыре основные вида связи (табл. 3,2):
один — один (1:1);
один — много (1:М);
 много
— один (М:1);
много
— один (М:1);много — много (М:М или M:N).
8. Типы структур ис. Их характеристики, достоиства, недостатки.
П о
способу организации ИС могут быть:
о
способу организации ИС могут быть:
-системы на основе архитектуры файл-сервер (клиент сервер)
-на основе многоуровневой архитектуры
-на основе Internet технологий
-локальные системы
1. Локальная БД. Машина и сама база размещаются на одном компьютере. Используется на маленьких предприятиях.

2 Файл серверная архитектура.
В качестве русурсов компьютерной сети могут быть БД, файловые системы, службы печати, почтовые службы. А тип сервера определяется видом ресурса, которым он управляет. В таких системах по запросу пользователя файлы БД передаются на компьютер пользователя для обработки как локальная копия в полном объеме.Сама Бд хранится на компьютере сервере в 1м экземпляре. Т.о управление данными полностью ложиться на клиента. Машина БД хранится на ПК клиента и образует СУБД, систему управления базами данных.При выполнении запроса к БД происходит запрос к локальной копии. недостатотки Перед запросом данные обновляются в полном объеме из реальной БД, что означает, что копия или вся БД передается по сети в полном объеме, что приводит к перегрузке сети и снижает быстродействие. Клиентская программа это источник ошибок, тк проблематично контролировать целостность БД, причиной Мб разный подход к контролю или его отсутствие вообще.
3. Клиент серверная архитектура.
Б ыла
добавлена программа сервер БД,
расположенная между БД и машиной. Сервер
используетSQL
с помощью которого формируются запросы
к серверу. По клиент серверной архитектуре
пользователь передает не всю БД, а часть
по запросу SQL.
Ресурсы клиентского ПК в физическом
выполнении не участвуют. Подход позволяет
повысить быстродействие и обеспечивает
сохранность и целостность данных.
ыла
добавлена программа сервер БД,
расположенная между БД и машиной. Сервер
используетSQL
с помощью которого формируются запросы
к серверу. По клиент серверной архитектуре
пользователь передает не всю БД, а часть
по запросу SQL.
Ресурсы клиентского ПК в физическом
выполнении не участвуют. Подход позволяет
повысить быстродействие и обеспечивает
сохранность и целостность данных.
4. Многозвенная архитектура.
3х звенная модель распределения функций позволяет управлять данными, обрабатывать их и представлять посредством реализации этих функций на отдельных ПК.
9. Определение реляционной модели данных, характеристика ее основных элементов.
Эта модель была предложена Эдгаром Коддом. Основана она на понятии отношения. Отношения -это множества элементов, называемых картежами (т.е. двумерная таблица). Таблица имеет строки (записи) и столбцы (колонки). Строкам таблицы соответствуют картежи, а столбцам атрибуты отношений. С помощью одной таблицы удобно описывать простейший вид связи- деление одного объекта, информация о котором хранится в таблице на множество подобъектов, каждому из которых соответствует строка или запись таблицы. При этом каждый подобъект имеет одинаковую структуру или свойства, описываемые соответствующими значениями полей записей.
Физическое размещение данных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов.
Достоинства: простота и удобство физического размещения на ЭВМ.
Недостаток: отсутствие стандартных средств идентификации отдельных записей. Сложность описание иерархических и сетевых связей.
О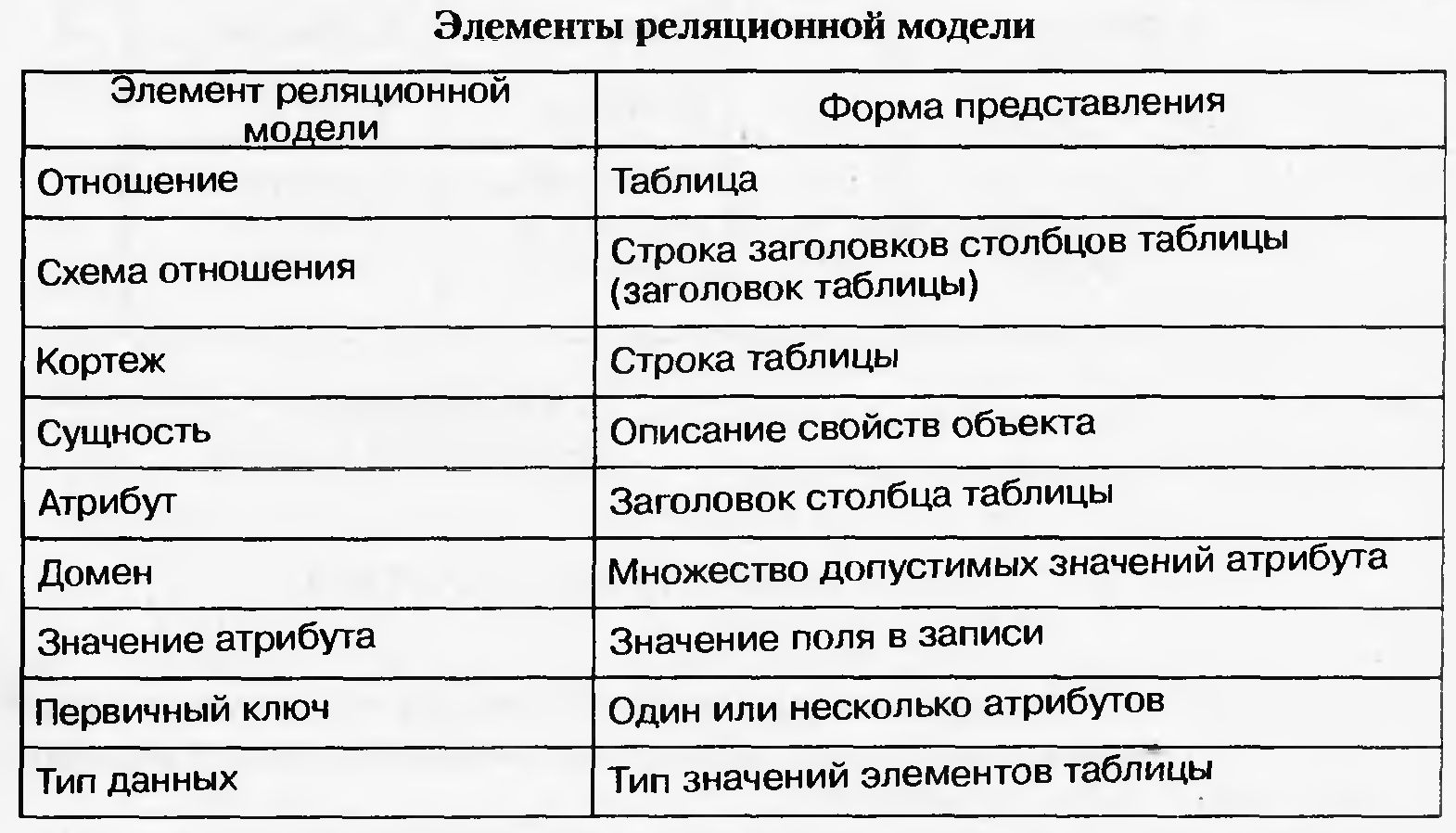 тношение
-двумерная таблица, содержащая некоторые
данные.
тношение
-двумерная таблица, содержащая некоторые
данные.
Сущность-объект природы, информация о котором содержится в базе данных. Данные о сущности хранятся в отношении.
Атрибуты- свойства, характеризующие сущность.
Домен-это множество всех возможных значений определенного атрибута отношения.
Первичный ключ-атрибут отношения однозначно идентифицирующий каждый из его картежей. (ключ может быть составным и внешним)