

34. Метод линеаризации
Имеется последовательность k-мерных случайных векторов Xn = (X1n, X2n, … , Xkn), n = 1, 2, … , такая, что Xn → a = (a1, a2, … , ak) при n → ∞, и последовательность функций fn: Rk → R1. Требуется найти распределение случайной величины fn(Xn).
Основная идея – рассмотреть главный линейный член функции fn в окрестности точки а. Из математического анализа известно, что
 ,
,
где остаточный член является бесконечно малой величиной более высокого порядка малости, чем линейный член. Таким образом, произвольная функция может быть заменена на линейную функцию от координат случайного вектора. Эта замена проводится с точностью до бесконечно малых более высокого порядка. Конечно, должны быть выполнены некоторые математические условия регулярности. Например, функции fn должны быть дважды непрерывно дифференцируемы в окрестности точки а.
Если вектор Xn является асимптотически нормальным с математическим ожиданием а и ковариационной матрицей ∑/n, где ∑ = ||σij||, причем σij = nM(Xi – ai)(Xj – aj), то линейная функция от его координат также асимптотически нормальна. Следовательно, при очевидных условиях регулярности fn(Xn) – асимптотически нормальная случайная величина с математическим ожиданиемfn(а) и дисперсией
 .
.
Для практического использования асимптотической нормальности fn(Xn) остается заменить неизвестные моменты а и ∑ на их оценки. Например, если Xn – это среднее арифметическое независимых одинаково распределенных случайных векторов, то а можно заменить на Xn, а ∑ - на выборочную ковариационную матрицу.
Пример. Пусть Y1, Y2, … , Yn – независимые одинаково распределенные случайные величины с математическим ожиданием а и дисперсией σ2. В качестве Xn (k = 1) рассмотрим выборочное среднее арифметическое
![]() .
.
Как известно, в
силу закона больших чисел ![]() → а = М(У).
Следовательно, для получения распределений
функций от выборочного среднего
арифметического можно использовать
метод линеаризации. В качестве примера
рассмотрим fn(y)
= f(y)
= y2.
Тогда
→ а = М(У).
Следовательно, для получения распределений
функций от выборочного среднего
арифметического можно использовать
метод линеаризации. В качестве примера
рассмотрим fn(y)
= f(y)
= y2.
Тогда
 .
.
Из этого соотношения следует, что с точностью до бесконечно малых более высокого порядка
![]() .
.
Поскольку в
соответствии с Центральной Предельной
Теоремой выборочное среднее арифметическое
является асимптотически нормальной
случайной величиной с математическим
ожиданием а и
дисперсией σ2/n, то квадрат
этой статистики является асимптотически
нормальной случайной величиной с
математическим ожиданием а2 и
дисперсией 4а2σ2/n.
Для практического использования может
оказаться полезной замена параметров
(асимптотического нормального
распределения) на их оценки, а именно,
математического ожидания – на ![]() ,
а дисперсии – на
,
а дисперсии – на ![]() ,
где s2 –
выборочная дисперсия.
,
где s2 –
выборочная дисперсия.
35. Коэффициент детерминации. Коэффициент конкордации
Коэффициент детерминации
Подбор функции линейной регрессии осуществляется на основе соображений профессионально-теоретического характера, а вычисленные оценки параметров, входящие в уравнения регрессии, наиболее хорошо согласовывались с опытными данными. Критерий соответствия регрессии опытным данным заложен в требовании наименьших квадратов:
![]() (1)
(1)
Результаты различных выборок имеют различное рассеяние. Поэтому может случиться, что построение регрессионной зависимости одного и того же экономического смысла по данным двух выборок из одной и той же генеральной совокупности приведет к различным уравнениям. Степень соответствия этих уравнений опытным данным, несмотря на одинаковый тип зависимости, может быть различна. Однако критерий (1) имеет недостаток: хотя его нижняя граница равна нулю, верхняя граница не может быть указана. Поэтому для оценки степени соответствия регрессии имеющимся эмпирическим данным он не используется. Желательно иметь в распоряжении показатель, отражающий, в какой мере функция регрессии определяется объясняющими переменными, содержащимися в ней. В качестве такого показателя можно выбрать коэффициент детерминации.
Рассмотрим вначале коэффициент детерминации для простой линейной регрессии, называемый также коэффициентом парной детерминации.
На
основе соображений, изложенных в разделе
1, теперь относительно легко найти
меру точности оценки регрессии. Было
показано, что общую дисперсию ![]() можно разложить на две составляющие —
на «необъясненную» дисперсию
можно разложить на две составляющие —
на «необъясненную» дисперсию![]() и дисперсию
и дисперсию![]() ,
обусловленную регрессией. Чем больше
,
обусловленную регрессией. Чем больше![]() по сравнению с
по сравнению с![]() ,
тем больше общая дисперсия формируется
за счет влияния объясняющей переменнойx и, следовательно,
связь между двумя переменнымиyиx более интенсивная.
Очевидно, удобно в качестве показателя
интенсивности связи, или оценки доли
влияния переменнойxнаy,
использовать отношение
,
тем больше общая дисперсия формируется
за счет влияния объясняющей переменнойx и, следовательно,
связь между двумя переменнымиyиx более интенсивная.
Очевидно, удобно в качестве показателя
интенсивности связи, или оценки доли
влияния переменнойxнаy,
использовать отношение
![]() (7)
(7)
Это
отношение указывает, какая часть общего
(полного) рассеяния значений уобусловлена изменчивостью переменнойx. Чем большую долю в
общей дисперсии составляет![]() ,
тем лучше выбранная функция регрессии
соответствует эмпирическим данным. Чем
меньше эмпири-ческие значения зависимой
переменной отклоняются от прямой
регрес-сии, тем лучше определена функция
регрессии. Отсюда происходит и название
отношения (7) — коэффициент детерминации
,
тем лучше выбранная функция регрессии
соответствует эмпирическим данным. Чем
меньше эмпири-ческие значения зависимой
переменной отклоняются от прямой
регрес-сии, тем лучше определена функция
регрессии. Отсюда происходит и название
отношения (7) — коэффициент детерминации![]() .
Индекс при коэффициенте указывает на
переменные, связь между которыми
изучается. При этом вначале в индексе
стоит обозначение зависимой переменной,
а затем объясняющей.
.
Индекс при коэффициенте указывает на
переменные, связь между которыми
изучается. При этом вначале в индексе
стоит обозначение зависимой переменной,
а затем объясняющей.
Из определения коэффициента детерминации как относительной доли очевидно, что он всегда заключен в пределах от 0 до 1:
![]() (8)
(8)
Если
![]() ,
то все эмпирические значения
,
то все эмпирические значения![]() (все точки поля корреляции) лежат на
регрессионной прямой. Это означает, что
(все точки поля корреляции) лежат на
регрессионной прямой. Это означает, что![]() дляi=1, ..., n,
т. е.
дляi=1, ..., n,
т. е.![]() .
В этом случае говорят о строгом линейном
соотношении (линейной функции) между
переменнымиуих. Если
.
В этом случае говорят о строгом линейном
соотношении (линейной функции) между
переменнымиуих. Если![]() ,
дисперсия, обусловленная регрессией,
равна нулю, а «необъясненная» дисперсия
равна общей дисперсии. В этом случае
,
дисперсия, обусловленная регрессией,
равна нулю, а «необъясненная» дисперсия
равна общей дисперсии. В этом случае![]() .
Линия регрессии тогда параллельна оси
абсцисс. Ни о какой численной линейной
зависимости переменнойуотхв статистическом ее понимании не может
быть и речи. Коэффициент регрессии при
этом незначимо отличается от нуля.
.
Линия регрессии тогда параллельна оси
абсцисс. Ни о какой численной линейной
зависимости переменнойуотхв статистическом ее понимании не может
быть и речи. Коэффициент регрессии при
этом незначимо отличается от нуля.
Итак,
чем больше ![]() приближается к единице, тем лучше
опре-делена регрессия.
приближается к единице, тем лучше
опре-делена регрессия.
Коэффициент
детерминации есть величина безразмерная
и поэтому он не зависит от изменения
единиц измерения переменных уиx(в отличие от параметров регрессии).
Коэффициент![]() не реагирует на преобразование переменных.
не реагирует на преобразование переменных.
Приведем
некоторые модификации формулы (7),
которые, с одной стороны, будут
способствовать пониманию сущности
коэффициента де-терминации, а с другой
стороны, окажутся полезными для
практических вычислений. Подставляя
выражение для ![]() (
(![]() )
в (7) и принимая во внимание (
)
в (7) и принимая во внимание (![]() )
и (2), получим:
)
и (2), получим:
![]() (9)
(9)
Эта формула еще раз подтверждает, что «объясненная» дисперсия, стоящая в числителе (7), пропорциональна дисперсии переменной х, так какb1является оценкой параметра регрессии.
Подставив
вместо ![]() его выражение (
его выражение (![]() )
и учитывая определения дисперсий
)
и учитывая определения дисперсий![]() и
и![]() ,
а также средних
,
а также средних![]() и
и![]() ,
получим формулу коэффициента детерминации,
удобную для вычисления:
,
получим формулу коэффициента детерминации,
удобную для вычисления:
![]()
или
![]() (10)
(10)
Из
(10) следует, что всегда ![]() .
С помощью (10) можно относительно легко
определить коэффициент детерминации.
В этой формуле содержатся только те
величины, которые используются для
вычисления оценок параметров регрессии
и, следовательно, имеются в рабочей
таблице. Формула (10) обладает тем
преимуществом, что вычисление коэффициента
детерминации по ней производится
непосредственно по эмпирическим данным.
Не нужно заранее находить оценки
параметров и значения регрессии. Это
обстоятельство играет немаловажную
роль для последующих исследований, так
как перед проведением регрессионного
анализа мы можем проверить, в какой
степени определена исследуемая регрессия
включенными в нее объясняющими
переменными. Если коэффициент детерминации
слишком мал, то нужно искать другие
факторы-переменные, причинно обусловливающие
зависимую переменную. Следует отметить,
что коэффициент детерминации
удовлетворительно отвечает своему
назначению при достаточно большом числе
наблюдений. Но в любом случае необходимо
проверить значимость коэффициента
детерминации.
.
С помощью (10) можно относительно легко
определить коэффициент детерминации.
В этой формуле содержатся только те
величины, которые используются для
вычисления оценок параметров регрессии
и, следовательно, имеются в рабочей
таблице. Формула (10) обладает тем
преимуществом, что вычисление коэффициента
детерминации по ней производится
непосредственно по эмпирическим данным.
Не нужно заранее находить оценки
параметров и значения регрессии. Это
обстоятельство играет немаловажную
роль для последующих исследований, так
как перед проведением регрессионного
анализа мы можем проверить, в какой
степени определена исследуемая регрессия
включенными в нее объясняющими
переменными. Если коэффициент детерминации
слишком мал, то нужно искать другие
факторы-переменные, причинно обусловливающие
зависимую переменную. Следует отметить,
что коэффициент детерминации
удовлетворительно отвечает своему
назначению при достаточно большом числе
наблюдений. Но в любом случае необходимо
проверить значимость коэффициента
детерминации.
Для
решения системы нормальных уравнений
очень важно знать соотношения между
объясняющими переменными xk.
Используя понятие коэффициента
детерминации, введем меру зависимости
этих переменных между собой. Обозначим
через![]() коэффициент детерминации, характеризующий
степень обусловленностиk-й
объясняющей переменной остальными
объясняющими переменными, входящими в
данную регрессию.
коэффициент детерминации, характеризующий
степень обусловленностиk-й
объясняющей переменной остальными
объясняющими переменными, входящими в
данную регрессию.
Укажем
формулу для вычисления коэффициента
детерминации между объясняющими
переменными. Для ее вывода исходят из
матрицы дисперсий и ковариаций объясняющих
переменных ![]() :
:
 (31)
(31)
где
![]() - дисперсия объясняющей переменнойxk,а
- дисперсия объясняющей переменнойxk,а![]() при
при![]() - ковариация объясняющих переменныхxk
и xl. Умножив
каждый элемент (31) наn-1,
получим матрицу
- ковариация объясняющих переменныхxk
и xl. Умножив
каждый элемент (31) наn-1,
получим матрицу![]() сумм квадратов отклонений и произведений
отклонений:
сумм квадратов отклонений и произведений
отклонений:
 (32)
(32)
где
![]() ,
а
,
а![]() .
Матрицу, обратную к
.
Матрицу, обратную к![]() ,
обозначим через
,
обозначим через![]() :
:
 (33)
(33)
Коэффициент детерминации между объясняющими переменными вычисляется по формуле
![]() (34)
(34)
где
![]() и
и![]() — элементыk-й строки иk-гo столбца
матриц
— элементыk-й строки иk-гo столбца
матриц![]() и
и![]() соответственно.
соответственно.
КОЭФФИЦИЕНТ КОНКОРДАЦИИ
В экономике существует большое число причинно обусловленных явлений, признаки которых не поддаются точной количественной оценке. Это так называемые атрибутивные признаки. Например, профессия, форма собственности, качество изделия, технологические операции и т. д. Специалист или эксперт ранжирует элементы изучаемой совокупности, приписывая каждому из них порядковый номер, соответствующий итогам сравнения по данному признаку с остальными элементами. Если количество признаков-переменных больше двух, то в результате ранжировок n элементов (предприятий или учреждений) имеют дело с m последовательностями рангов. Для проверки, хорошо ли согласуются эти m ранжировок друг с другом, используется коэффициент согласованности W, называемый также коэффициентом конкордации Кендэла:
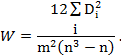
При наличии связанных рангoв коэффициент кенкордации W вычисляется по формуле

где
![]() i= 1, 2, ....,n;j= 1, 2, ....,m- суммарангов, приписанных
всеми экспертами t-му
элементу выборки, минус среднее значение
этих сумм рангов; m
— число экспертов или признаков,
связь между которыми оценивается; n
— объем выборки (числопредприятий
или учреждений), другими словами, это
количество членов последовательности
рангов;
i= 1, 2, ....,n;j= 1, 2, ....,m- суммарангов, приписанных
всеми экспертами t-му
элементу выборки, минус среднее значение
этих сумм рангов; m
— число экспертов или признаков,
связь между которыми оценивается; n
— объем выборки (числопредприятий
или учреждений), другими словами, это
количество членов последовательности
рангов; ![]() ,
где
,
где ![]() -
число связанных рангов, к = 1, ... z.
Например, если связываются элементы от
восьмого до одиннадцатого включительно,
то
-
число связанных рангов, к = 1, ... z.
Например, если связываются элементы от
восьмого до одиннадцатого включительно,
то ![]() =
4. Коэффициент W
принимает значения в
интервале 0 ≤ W
≤ 1.
=
4. Коэффициент W
принимает значения в
интервале 0 ≤ W
≤ 1.