

ЛР3
.docxГУАП
КАФЕДРА № 41
ОТЧЕТ ЗАЩИЩЕН С ОЦЕНКОЙ
ПРЕПОДАВАТЕЛЬ
старший преподаватель |
|
|
|
В.В. Боженко |
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
ОТЧЕТ О ЛАБОРАТОРНОЙ РАБОТЕ №3 |
СВЁРТОЧНЫЕ НЕЙРОННЫЕ СЕТИ |
по курсу: МАШИННОЕ ОБУЧЕНИЕ |
|
РАБОТУ ВЫПОЛНИЛ
СТУДЕНТ ГР. № |
4116 |
|
|
|
|
|
|
|
подпись, дата |
|
инициалы, фамилия |
Санкт-Петербург 2024
Цель работы: обучить свёрточную сеть распознавать изображения.
Ход работы
Загрузка данных из набора MNIST и визуализация
Произведена загрузка данных из набора MNIST с помощью библиотеки Keras и метода mnist.load_data() . Набор данных состоит из обучающей выборки, которая содержит 60 000 изображений размером 28x28 пикселей и тестовой выбороки, содержащей 10 000 изображений размером 28x28 пикселей. (Рисунок 1).

Рисунок 1 – Загрузка данных
Визуализированы 4 случайных изображения из тренировочного набора (Рисунок 2).

Рисунок 2 – Визуализация 4 случайных изображений из тренировочного набора
Также выполнена визуализация 4 случайных изображения из валидационного набора (Рисунок 3).

Рисунок 3 – Визуализация 4 случайных изображений из валидационного набора
Предобработка данных
Произведена предобработка даных. X_train и X_test преобразованы в одномерные массивы (Рисунок 4).

Рисунок 4 – Преобразование в одномерные массивы
Так как каждый пиксель может принимать значения от 0 до 255, выполнена нормализация входных значений, данные приведены к диапазону от 0 до 1 (Рисунок 5)

Рисунок 5 – Нормализация входных значений
Y_train и y_test преобразованы в двоичную матрицу, где цифра 1 указывает на принадлежность к классу (Рисунок 6).
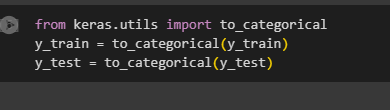
Рисунок 6 – Преобразование в двоичную матрицу
1 DNN
Создана и обучена полносвязная модель с двумя слоями, количество эпох обучения =20. Функция активации – линейная (Рисунок 7).
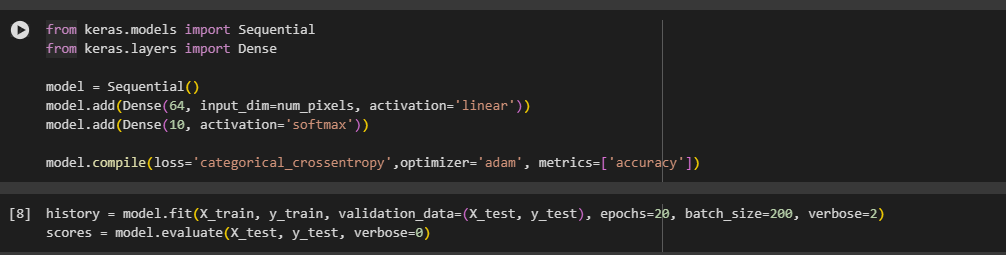
Рисунок 7 – Создание и обучение первой модели
Результаты обучения записаны в созданный датафейм (Рисунок 8).

Рисунок 8 – Создание и вывод датафрейма
Показатель точности модели высокий. Значение функции потерь довольно низкое.
Произведено предсказание модели на тестовых данных, метод argmax() выбирает класс с наивысшей предсказанной вероятностью для каждого образца (Рисунок 9).

Рисунок 9 – Предсказание модели
Создан отчет о классификации с помощью classification_report() (Рисунок 10).

Рисунок 10 –Создание отчета о классификации
Из отчета видно, что модель имеет хорошую общую точность 0.93. Большинство классов имеют высокие показатели точности и полноты. Класс с меткой 8 имеет более низкие показатели по сравнению с другими классами. В целом, на основании этих метрик можно сказать, что модель обладает достаточной способностью различать классы.
Визуализирована матрица ошибок. Для нормализации матрицы ошибок выполняется деление каждого элемента на общее количество примеров в соответствующем классе (Рисунок 11).

Рисунок 11 – Матрица ошибок для первой модели
Диагональные ячейки показывают долю верных предсказаний для каждого класса, они близки к 1, что говорит о хорошем предсказании класса. Недиагональные элементы показывают ошибки классификации.
Построены графики потерь и точности обучения по эпохам (Рисунок 12)
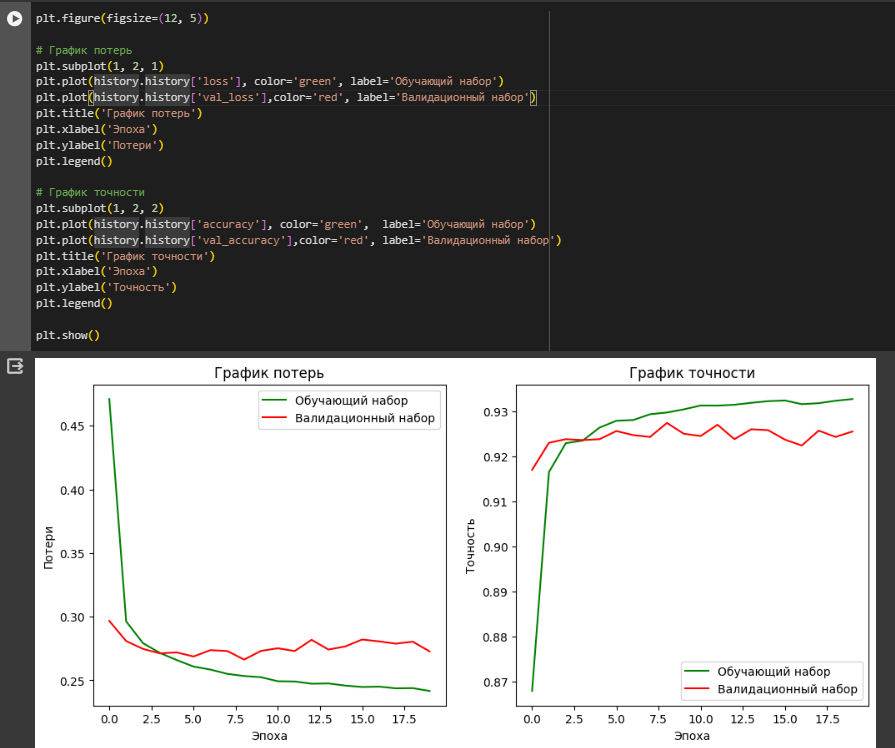
Рисунок 12 – График потерь и график точности для первой модели
Значения потерь на обучающем наборе данных начинаются с высокого уровня и быстро снижаются, что указывает на то, что модель эффективно учится на обучающем наборе данных. Потери на валидационном наборе начинаются на уровне, с обучающим набором, и снижаются, но затем опять увеличиваются. Точность модели на обучающем наборе данных растёт быстро и достигает высокого уровня.
Наблюдается увеличение разрыва между обучающим и валидационным набором, что является признаком переобучения.
2 DNN
Далее создана и обучена модель с функцией активации relu на входном слое (Рисунок 13).

Рисунок 13 – Создание и обучение второй модели
Результаты обучения добавлены в датафрейм (Рисунок 14).

Рисунок 14 – Добавление записи в датафрейм
По сравнению с первой моделью, вторая модель имеет большую точность, и меньшие потери.
Также выполнено предсказание и выведен отчет о классификации (Рисунок 15).

Рисунок 15 –Создание отчета о классификации для второй модели
Показатель точности лучше, чем у первой модели.
Выведена матрица ошибок (Рисунок 16).

Рисунок 16–Матрица ошибок для второй модели
Диагональные ячейки также близки к 1.
Выведен график потерь и график точности для второй модели (Рисунок 17).
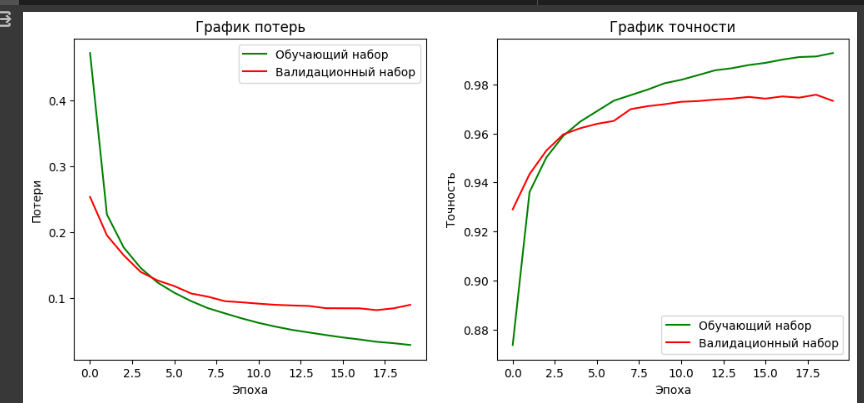
Рисунок 17– График потерь и график точности для второй модели
Разрыв между наборами также наблюдается, однако он стал меньше, и графики стали более сглаженными
Также созданы и обучены модели DNN с большим количеством слоев (Рисунок 18-20).

Рисунок 18– DNN модель с 2 скрытыми слоями, количество эпох = 40
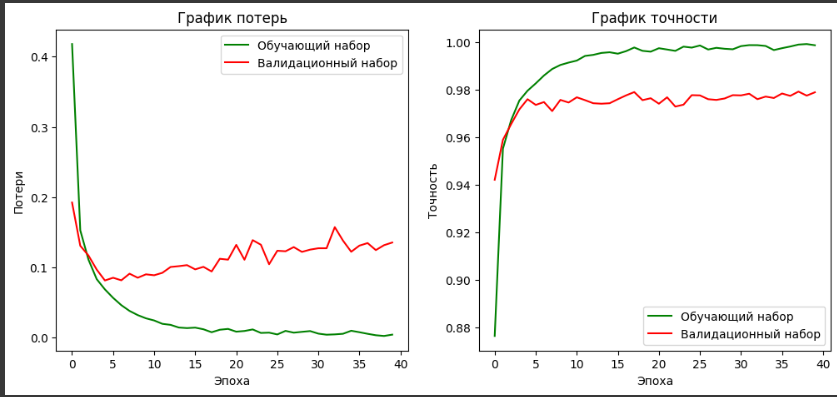
Рисунок 19– DNN модель с 3 скрытыми слоями, количество эпох = 40
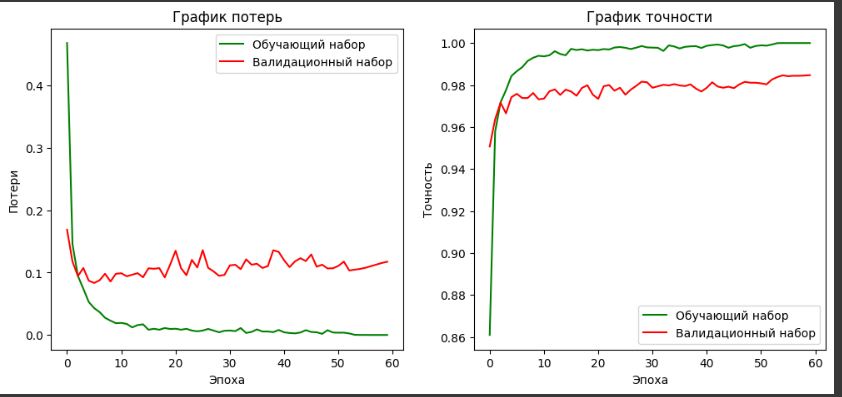
Рисунок 20– DNN модель с 5 скрытыми слоями, количество эпох = 60
Присутствует разрыв между обучающим и валидационным набором, что указывает на переобучение.
CNN
Для работы со свёрточной нейронной сетью импортированы данные и выполнена их предобработка (Рисунок 21).

Рисунок 21– Импортирование данных и предобработка
Далее создана модель с 1 сверточным блоком (Рисунок 22).
 э
э
Рисунок 22– Создание модели с 1 сверточным блоком
Произведена компиляция и обучение модели (Рисунок 23).

Рисунок 23– Компиляция и обучение модели
Построен график точности и график потерь для CNN модели.

Рисунок 24-CNN модель с 1 сверточным блоком
Создана и обучена модель с тремя блоками свертки (Рисунок 25).

Рисунок 25-Создание CNN модели с 3 сверточнымим блоками
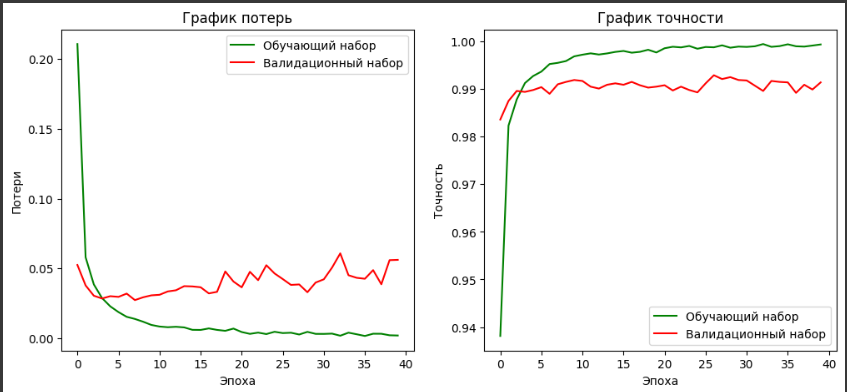
Рисунок 26- CNN модель с 3 сверточными блоками
Потери на обучающем наборе быстро снижаются с первых эпох и остаются относительно низкими. Потери на валидационном наборе также уменьшаются, но имеют выраженные колебания, что может указывать на нестабильность модели на новых данных.
Выведен датафрейм с результатами всех экспериментов (Рисунок 27).

Рисунок 27- Датафрейм с результатами экспериментов
В результате проведенных экспериментов можно сказать, что с увеличением количества слоев увеличивается точность предсказания модели. CNN показывают лучшую точность и меньшие потери по сравнению с DNN. Модель с функцией активации Relu имеет большую точность и меньшие потери, чем модель с линейной функцией активации.
Эксперимент №7 показывает самую высокую точность и самые низкие потери, что делает эту модель наиболее перспективной.
Проверка лучшей модели
Взяты два собственных изобаржения рукописных цифр проведена предобработка. И проверено предсказание лучшей модели на них (Рисунок 28-29).

Рисунок 28- Предобработка изображений и выполнение предсказаний

Рисунок 29- Результат предсказания
Предсказанный класс совпал с фактическим.
Набор данных fashion-mnist
Загружен датасет, в котором содержатся изображения одежды, каждое из которых принадлежит к одному из 10 классов (Рисунок 30).
![]()
Рисунок 30 -Загрузка датасета

Рисунок 31- Визуализация 4 случайных изображений из тренировочного набора
Рисунок 32- Визуализация 4 случайных изображений из валидационного набора
Создана и обучена модель с одним блоком свертки.

Рисунок 33- Визуализация 4 случайных изображений из валидационного набора
Реализованы графики потерь и точности (Рисунок 34).

Рисунок 34- График потерь и график точности для модели CNN
Ссылка на Google Colab: https://colab.research.google.com/drive/1S-Bh9WXczlqqP7scxvUCULANTipU0UNA?usp=sharing
Вывод:
В ходе выполнения лабораторной работы проведено 7 экспериментов по обучению полносвязных и свёрточных нейронных сетей. Обучение производилось на наборе изображений рукописных чисел MNIST.
С увеличением количества слоев качество предсказания модели увеличивается. CNN показывают лучшую точность и меньшие потери по сравнению с DNN.
Также произведено обучении CNN модели на датасете fashion_mnist, который содержит предметы одежды.