

МО2
.docxГУАП
КАФЕДРА № 41
ОТЧЕТ ЗАЩИЩЕН С ОЦЕНКОЙ
ПРЕПОДАВАТЕЛЬ
старший преподаватель |
|
|
|
В.В. Боженко |
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
ОТЧЕТ О ЛАБОРАТОРНОЙ РАБОТЕ №1 |
ПОЛНОСВЯЗНЫЕ НЕЙРОННЫЕ СЕТИ |
по курсу: МАШИННОЕ ОБУЧЕНИЕ |
|
|
РАБОТУ ВЫПОЛНИЛ
СТУДЕНТ ГР. № |
4116 |
|
|
|
|
|
|
|
подпись, дата |
|
инициалы, фамилия |
Санкт-Петербург 2024
Цель работы: обучить нейронную сеть для выполнения задачи регрессии и классификации.
Вариант 1
Часть 1
Импортирован датасет с автомобилями (Рисунок 1).

Рисунок 1 – Импорт датасета
Датафрейм содержит информацию о различных автомобилях, включая их технические характеристики и стоимость.
Произведена предварительная обработка данных. Для оценки данных использовался метод info() (Рисунок 2).

Рисунок 2 – Использование метода info()
В датафрейме 205 строк и 26 столбцов.
Так как в датасете есть категориальные данные, которые могут повлиять на предсказание, категориальные значения преобразованы в числовые с помощью OrdinalEncoder (Рисунок 3).
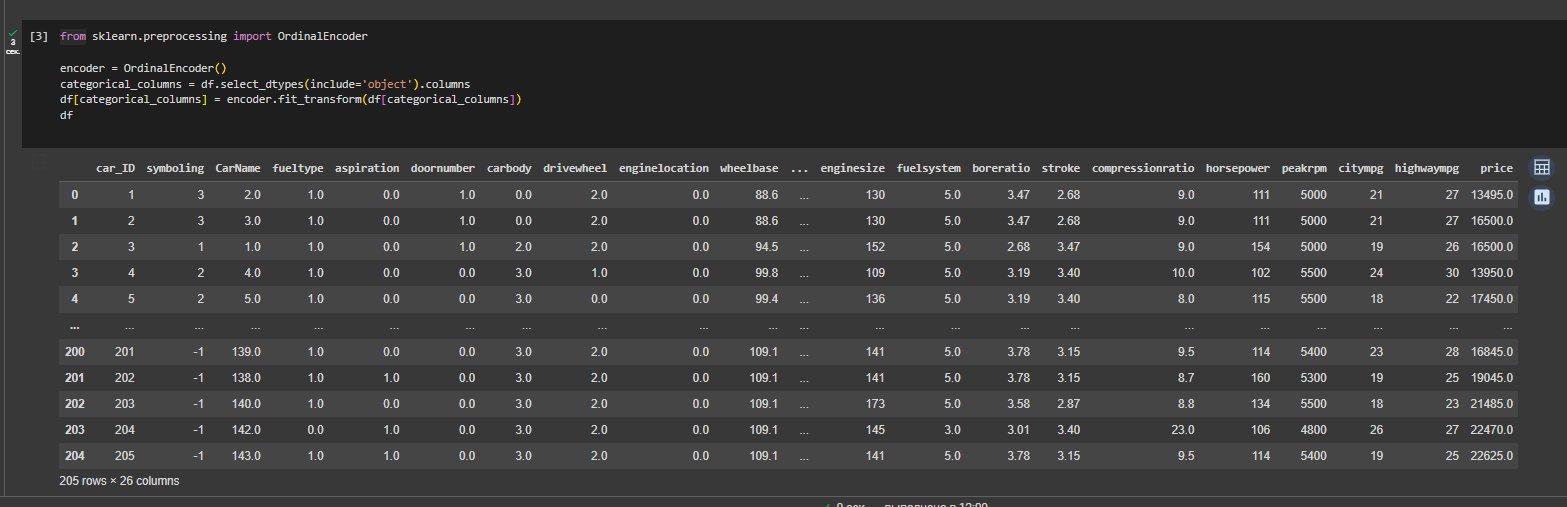
Рисунок 3 – Преобразование категориальных данных в числовые
Затем произведена стандартизация числовых данных. Создается объект StandartScaler, который обучается на числовых данных, и затем эти данные заменяются нормализованными значениями (Рисунок 4).

Рисунок 4 – Стандартизация данных
Затем данные разделены на обучающий и тестовый наборы (Рисунок 5).

Рисунок 5 – Разделение на обучающий и тестовый наборы
Реализованы последовательные модели нейронной сети с разным количеством слоев с использованием библиотеки Keras. Sequential позволяет определить модель последовательно, добавляя слои один за другим. С помощью Dense добавляется полносвязный слой нейронной сети, в котором каждый нейрон связан с каждым нейроном в следующем слое.
Параметр units определяет количество нейронов в слое. Параметр activation определяет функцию активации, применяемую к выходу нейронов в слое. Функция активации ReLU означает, что для любого входного значения меньше нуля она возвращает ноль, а для положительных значений возвращает само значение. Параметр input_shape определяет форму входных данных, используется только для первого слоя модели.
Метод summary() выводит сводку модели, включая количество параметров каждого слоя и общее количество параметров модели. (Рисунок 6-7).

Рисунок 6 – Создание модели нейронной сети

Рисунок 7 – Сводки моделей
Количество параметров в модели соответствует сумме параметров всех слоев в сети. Как видно из примеров, с увеличением числа скрытых слоев и их размера увеличивается и общее количество параметров в сети.
Далее происходит процесс компиляции модели - процесс настройки модели для обучения. Функция потерь loss определяет функцию, которая будет использоваться для оценки разницы между предсказанными значениями модели и истинными значениями во время обучения, используется среднеквадратичная ошибка MSE. Параметр metrics определяет список метрик, которые будут использоваться для оценки производительности модели во время обучения, в данном случае используется средняя абсолютная ошибка MAE (среднее абсолютное отклонение между предсказанными и истинными значениями) (Рисунок 8).

Рисунок 8 – Компиляция модели
Для выбора оптимальной модели выведены показатели потерь и точности моделей (Рисунок 9).
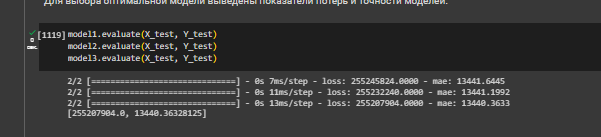
Рисунок 9 – Вывод показателей для моделей
Наименьшая средняя абсолютная ошибка у третьей модели, что указывает на то, что она в среднем лучше предсказывает значения, с меньшим отклонением от истинных значений. Значение loss также наименьшее у третьей модели.
Выполнено обучение модели нейронной сети на тренировочных данных в течение 100 эпох и оценка производительности модели на валидационных данных. Выполнено предсказание значения целевой переменной на валидационных данных (Рисунок 10).

Рисунок 10 – Обучение модели и вывод истинных и предсказанных значений
Значения функции потерь на обучающем наборе данных и на валидационном наборе данных постепенно снижаются с каждой эпохой, это свидетельствует о том, что модель постепенно улучшает свою способность делать предсказания.
Значения средней абсолютной ошибки также снижаются по мере обучения модели, средняя абсолютная ошибка предсказаний модели уменьшается, что также является положительным признаком.
По предсказанию значений видно, что в некоторых случаях предсказанные значения близки к истинным значениям, а в других есть значительное расхождение. Это указывает на то, что модель может быть не слишком точной. Реализован график для сравнения истинных и предсказанных значений (Рисунок 11).
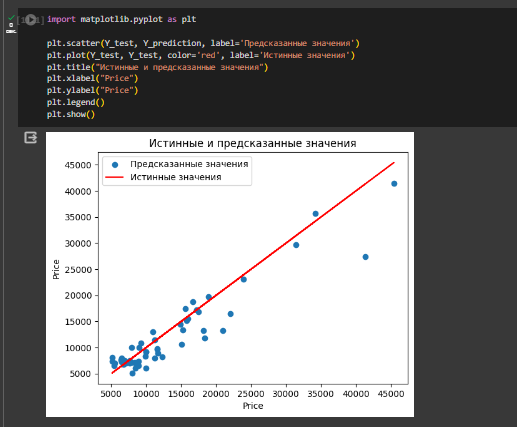
Рисунок 11 – Истинные и предсказанные значения на графике
Из графика видно, что есть выбросы, которые указывают, что модель может допускать неточные прогнозы для определенных значений. Однако, основная часть предсказанных значений близка к истинным.
Для визуализации процесса обучения нейронной сети построены два графика.
Построен график ошибок, который показывает изменение значения функции потерь на обучающем и валидационном наборах данных в зависимости от количества эпох обучения. Затем построен график метрики качества, который показывает изменение метрики качества MAE (средняя абсолютная ошибка) на обучающем и валидационном наборах данных по мере увеличения числа эпох обучения (Рисунок 12-13)

Рисунок 12 – Реализация графика ошибок и графика метрики качества

Рисунок 13 – График ошибок и график метрики качества
График ошибок показывает, что ошибка на обучающем и валидационном наборах быстро снижается и стабилизируется после примерно 30 эпох. Это указывает на то, что модель достигает определённого уровня производительности и дальнейшее уменьшение ошибки минимально.
На графике метрики качества метрика на обоих наборах данных также улучшается в начале и стабилизируется, что свидетельствует о достижении моделью хорошей предсказательной способности.
Эти графики также показывают, что модель не переобучается, обе кривые для обучающего и валидационного наборов данных очень близки друг к другу и следуют почти идентичным траекториям, что говорит о том, что модель обобщает, а не запоминает обучающие данные. Это хороший признак того, что модель будет хорошо работать на новых, неизвестных данных.
Часть 2
Загружен набор данных, который содержит информацию о сердечных болезнях (Рисунок 14).
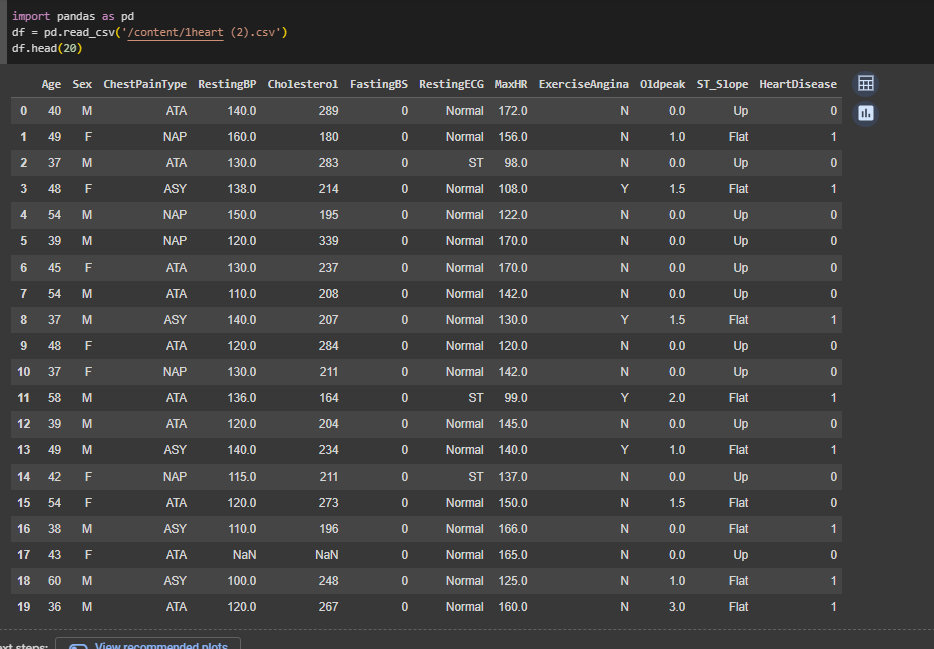
Рисунок 14 – Импортирование датасета с данными о сердечных болезнях
Произведена предварительная обработка данных. Для оценки данных использовался метод info (Рисунок 15).

Рисунок 15 – Использование метода info () для датасета с сердечными болезнями
Затем произведено удаление явных дубликатов (Рисунок 16).

Рисунок 16 – Удаление явных дубликатов
Для поиска неявных дубликатов применятся метод unique, который выводит уникальные значения.

Рисунок 17 – Вывод уникальных значений
Из столбца "Sex" выводится количество уникальных значений (Рисунок 18).

Рисунок 18 – Вывод количества уникальных значений в столбце Sex
В столбце с полом пациентов есть одно значение, которое вероятно всего является ошибочным и его следует исправить (Рисунок 19).

Рисунок 19 – Замена ошибочных значений
Выполнена проверка на пустые значения, и удалены строки с ними (Рисунок 20).

Рисунок 20 – Удаление строк с пустыми значениями
В датасете есть не только числовые, но и категориальные данные. Для преобразования категориальных данных в числовые использовалось порядковое кодирование (Рисунок 21).

Рисунок 21– Замена категориальных данных на числовые
Затем выполнена стандартизация числовых данных с помощью StandardScaler (Рисунок 22).

Рисунок 22– Стандартизация данных
Данные разделены на обучающий и тестовый наборы (Рисунок 23).

Рисунок 23– Разделение на обучающий и тестовый наборы
Созданы 3 модели последовательной нейронной сети. Activation определяет функцию активации для нейронов в слое. Используется ReLU для скрытых слоев и сигмоидная функция активации для выходного слоя. (Рисунок 24).

Рисунок 24- Создание НС
Затем выполнен процесс компиляции моделей. Функция потерь binary_crossentropy используется для задач бинарной классификации, метрика accuracy используется для оценки производительности модели на основе точности предсказаний классов (Рисунок 25).

Рисунок 25- Компиляция модели
Выведены показатели потерь и точности моделей (Рисунок 26).

Рисунок 26- Вывод показателей моделей
Вторая модель имеет самые низкие потери и самую высокую точность, что делает её лучшей из трех представленных моделей.
Выполнено обучение модели нейронной сети на тренировочных данных в течение 100 эпох и произведено предсказание значения целевой переменной на валидационных данных (Рисунок 27).

Рисунок 27- Обучение модели НС
Потери на обучающем наборе данных постепенно уменьшаются с каждой эпохой, что является положительным признаком. Точность на обучающем наборе данных увеличивается, что говорит о том, что модель становится лучше в предсказаниях правильных классов. В начале обучения потери на валидационном наборе уменьшаются, а точность увеличивается. Однако, с определённого момента, потери на валидационном наборе начинают увеличиваться, а точность либо выравнивается, либо колеблется.
Построен график, на котором отображена точность модели на обучающем и валидационном наборах данных в зависимости от эпохи обучения (Рисунок 28).

Рисунок 28- График точности модели
Точность на обучающем наборе монотонно увеличивается, что говорит о том, что модель хорошо усваивает тренировочные данные и с каждой эпохой обучения повышает свою способность правильно классифицировать обучающий набор.
Точность на валидационном наборе повышается, но затем выравнивается и демонстрирует некоторые колебания.
Разрыв между обучающим и валидационным наборами постепенно увеличивается, что может говорить о переобучении модели. Модель очень хорошо работает на данных, которые она уже видела (обучающий набор), но её способность предсказывать результаты на новых данных (валидационный набор) не улучшается с той же скоростью.
Далее построен график, на котором отображены потери модели на обучающем и валидационном наборах данных в зависимости от эпохи обучения (Рисунок 29).

Рисунок 29- График потерь
Потери на обучающем наборе монотонно уменьшаются, что указывает на то, что модель продолжает улучшать свою способность к корректной классификации данных с каждой эпохой обучения.
Потери на валидационном наборе начинают увеличиваться после определенной эпохи, что является признаком переобучения.
Разрыв между кривыми потерь для обучающего и валидационного наборов увеличивается, что является дополнительным подтверждением переобучения.
Для визуализации производительности модели классификации построен график, который представляет собой кривую ROC. Ось x представляет собой долю ложноположительных оценок, ось y- долю правильных положительных оценок (Рисунок 30).
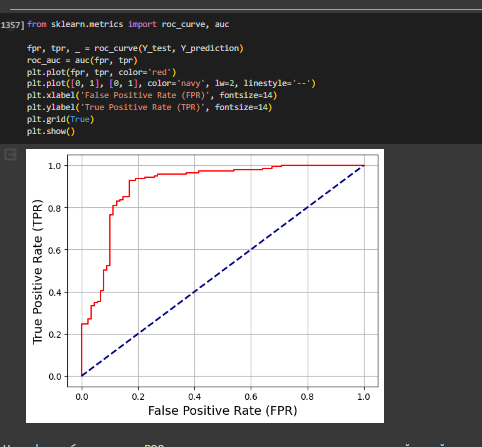
Рисунок 30- ROC-кривая
На графике наблюдается, что ROC-кривая значительно выше линии, представляющей случайное угадывание, что свидетельствует о хорошей способности модели к классификации. Однако, кривая не приближается к верхнему левому углу, модель всё же допускает ошибки (есть некоторые ложноположительные результаты).
Ссылка на Google Colab:
https://colab.research.google.com/drive/1OL4zpzvDosObutnImG6v0vPCEIxHNXNB?usp=sharing
Вывод:
Для задачи регрессии модель нейронной сети показала эффективные результаты. Ошибка как на обучающем, так и на валидационном наборе данных быстро снижалась, и обе кривые сходились, что указывает на хорошую обобщающую способность модели без явных признаков переобучения. Это говорит о том, что модель достаточно хорошо настроена для решения задачи регрессии на представленных данных.
Для задачи классификации модель демонстрировала улучшение точности на обучающем наборе данных, однако на валидационном наборе наблюдались признаки переобучения, так как точность выравнивалась с некоторыми колебаниями, а потери после снижения начинали возрастать.
ROC-кривая показала, что модель обладает хорошей диагностической способностью, значительно превосходя случайное угадывание.