

ОТчет 2
.docxНа чем базируется классификация архитектур Флинна?
Классификация архитектур ВС Флинна базируется на понятии потока.
Поток - последовательность элементов, команд или данных, обрабатываемая процессором.
На основе числа потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD, MISD, SIMD, MIMD.
SISD - одиночный поток команд и одиночный поток данных. К этому классу относятся, прежде всего, классические последовательные машины, или иначе, машины фон-неймановского типа. В таких машинах есть только один поток команд, все команды обрабатываются последовательно друг за другом и каждая команда инициирует одну операцию с одним потоком данных.
SIMD - одиночный поток команд и множественный поток данных. В архитектурах подобного рода сохраняется один поток команд, включающий, в отличие от предыдущего класса, векторные команды. Это позволяет выполнять одну арифметическую операцию сразу над многими данными - элементами вектора. Способ выполнения векторных операций не оговаривается, поэтому обработка элементов вектора может производится либо процессорной матрицей, как в ILLIAC IV, либо с помощью конвейера, как, например, в машине CRAY-1.
MISD - множественный поток команд и одиночный поток данных. Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих один и тот же поток данных. Однако ни Флинн, ни другие специалисты в области архитектуры компьютеров до сих пор не смогли представить убедительный пример реально существующей вычислительной системы, построенной на данном принципе.
MIMD - множественный поток команд и множественный поток данных. Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных.
(К какому классу по Флинну относится ЭВМ фон неймановского типа?)
SISD - одиночный поток команд и одиночный поток данных. К этому классу относятся, прежде всего машины фон-неймановского типа,
(К какому классу по Флинну относятся векторно-конвейерные и векторно-параллельны ВС?)
Векторно-конвейерные и векторно-параллельные – SIMD
(Классификация ВС по способу организации оперативной памяти)
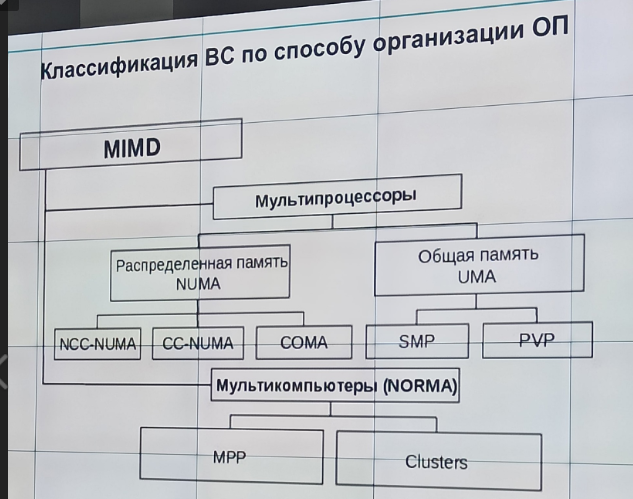
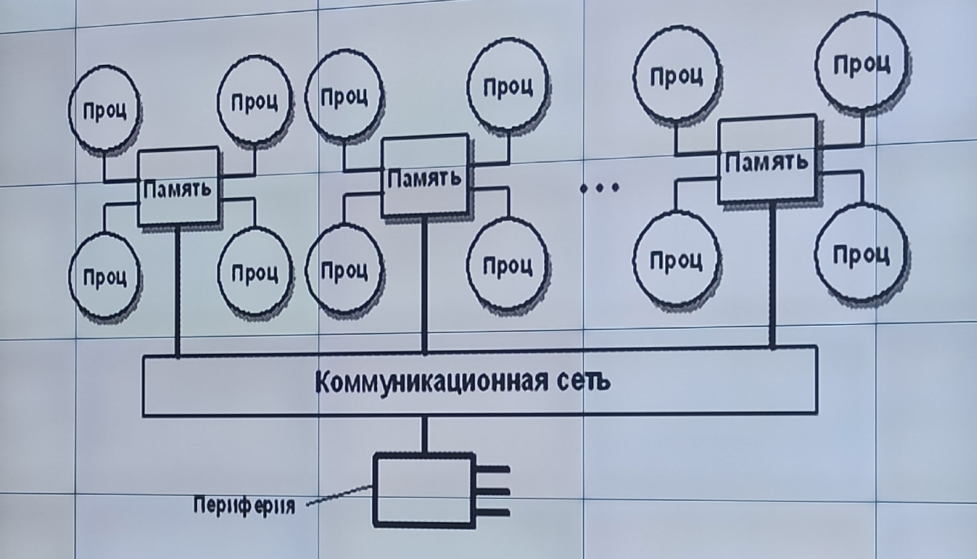
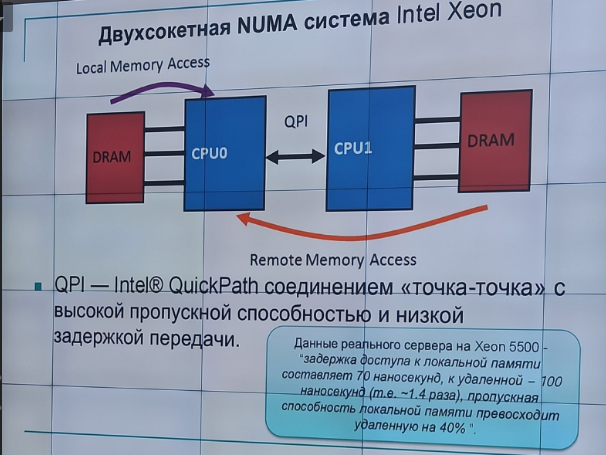
с неоднородным доступом к памяти (NUMA) - имеют память, которая физически распределена по различным частям системы, но логически разделяема (образует единое адресное пространство). Такая память называется еще логически общей (разделяемой) памятью (logically shared memory). В отличие от UMA-систем, в NUMA-системах время доступа к различным частям оперативной памяти различно.
COMA – системы в которых в качестве оперативной памяти используется только локальная кэш-память процессоров
CC-NUMA – системы, в которых аппаратно обеспечивается когерентность кэш-памяти процессоров
NCC-NUMA – системы, в которых аппаратно не поддерживается когерентность кэш-памяти разный процессоров
Когерентность определяет поведение чтений и записей в одно и то же место памяти. Если один процессор изменил данные, а другой об этом не узнал – это плохо, против этого и есть когерентность.
Кэш называется когерентным, если каждая операция чтения по какому-либо адресу, выполненная любым из процессоров, возвращает значение, занесенное в ходе последней операции записи по этому адресу, вне зависимости от того, какой из процессоров производил запись последним.
с общей памятью (UMA) - значение, записанное в память одним из процессоров, напрямую доступно для другого процессора. К общей памяти доступ разных процессорами системы осуществляется, как правило, за одинаковое время.
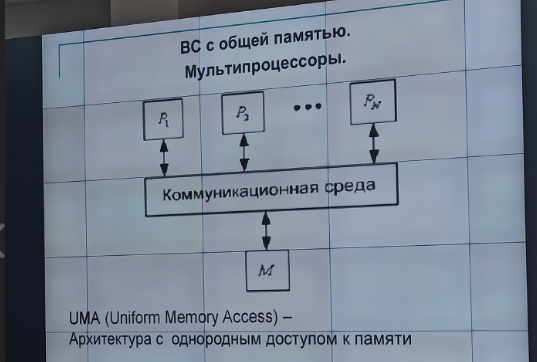
SMP – однородные мультипроцессоры с равноправным (симметричным) доступом к общей оперативной памяти – системы с симметричной мультипроцессорной архитектурой

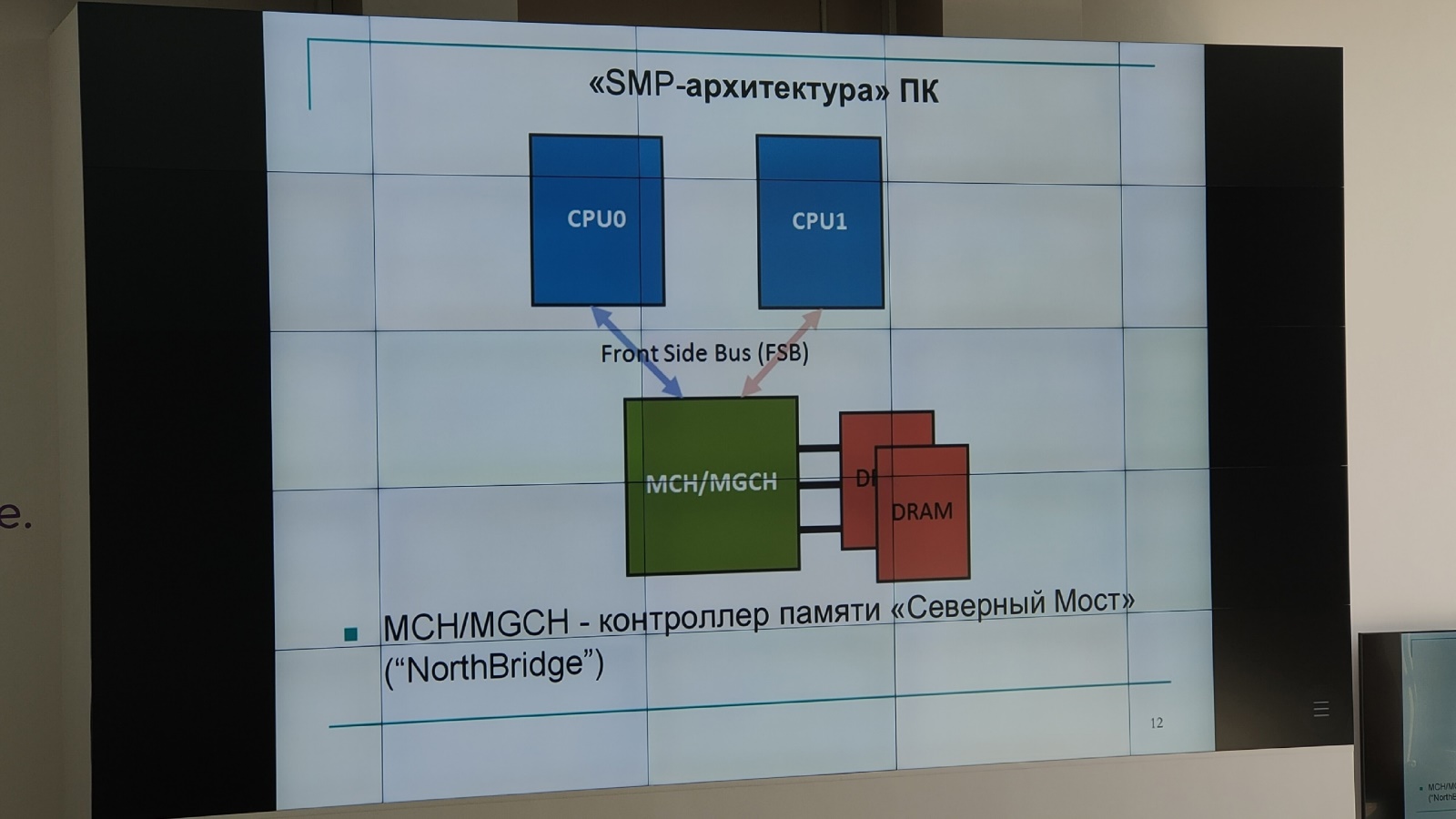
Симметричный доступ к памяти:
Равные права всех процессоров на доступ к памяти
Одна и та же адресация для всех элементов памяти
Равное время доступа всех процессоров системы к памяти (без учета взаимных блокировок)
PVP – в них есть специальные векторно-конвейерные процессоры, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах.
Как правило, несколько таких процессоров работают одновременно над общей памятью в рамках многопроцессорных конфигураций. Несколько таких узлов могут быть объединены с помощью коммутатора.
Вектор – упорядоченный набор однотипных данных (массивы).
Современный векторно-конвейерные системы имеют иерархическую структуру:
На нижнем уровне иерархии расположены конвейеры операций сложения вещественных чисел, конвейер умножения
Некоторая совокупность конвейеров операций объединяется в конвейерное функциональное устройство
Векторно-конвейерный процессор содержит ряд конвейерных функциональных устройств
Несколько векторно-конвейерных процессоров, объединенных общей памятью, образуют вычислительный узел
Несколько таких узлов объединяются с помощью коммутаторов, образую либо NUMA-систему либо MPP-систему
Основное назначение векторных операций состоит в распараллеливании выполнения операторов цикла
Каждая ступень конвейера операций называется ступенью конвейера операций
Общее число ступеней – длина конвейера операций


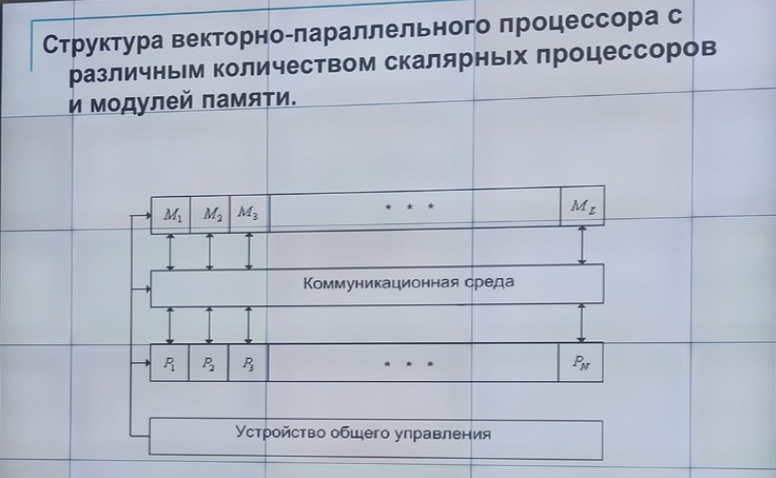
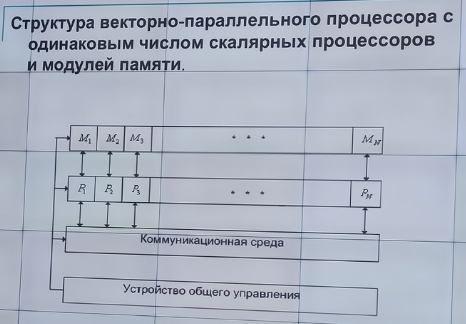
Основные компоненты векторно-параллельного процессора:
Совокупность скалярных процессоров (Р)
Совокупность модулей оперативной памяти (М)
Коммуникативная среда
Устройство общего управления
Современные векторно-параллельные системы имеют иерархическую структуру:
На нижнем уровне находятся векторно-параллельные процессоры, представляющие собой совокупность скалярных процессоров (П)
П объединены коммуникативной сетью
В каждом такте П синхронно выполняют одну и ту же команду над разными данными
Несколько таких узлов объединяются общей памятью или коммуникативной сетью, образуя либо NUMA-систему либо MPP-систему
Динамическое (спекулятивное) исполнение – исполнение не в том порядке как это задано программным кодом, а в том, как удобно процессору
Без прямого доступа к удаленной памяти (NORMA) – мультикомпьютеры не имеют общей памяти. Межпроцессорный обмен происходит через коммуникационную сеть с помощью передачи сообщений. Каждый процессор имеет независимое адресное пространство.
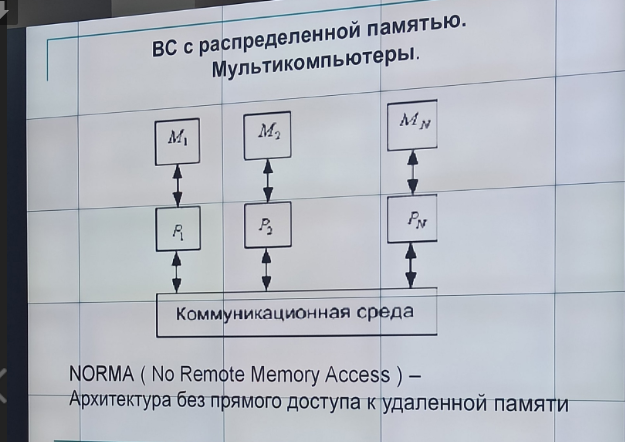
Кластеры – группа взаимно соединенных вычислительных систем (узлов), работающих совместно, составляя единый вычислительный ресурс и создавая иллюзию наличия единой ВС.
В качестве узлов могут выступать, как однопроцессорые ВС, так и ВС типа SMP или MPP
Каждый узел может функционировать самостоятельно и отдельно от кластера
Архитектура кластерные вычислений сводится к объединению нескольких узлов высокоскоростной сетью
Неотъемлемая часть – специализированное ПО
Преимущества кластеризации:
Абсолютная масштабируемость - возможно создание больших кластеров, превосходящих по вычислительной мощности даже самые производительные одиночные ВМ
Наращиваемая масштабируемость - кластер строится так, что его можно наращивать, добавляя новые узлы
Высокий коэффициент готовности
Превосходное соотношение цена/производительность
Кластеры с функциональной точки зрения:
Кластеры с балансированной нагрузкой (серверная ферма)
HP (высокопроизводительные)
HA (с высокой готовность) – для надежности дублируются компоненты
Системы распределенных вычислений (GRID) – не кластер
Латентность – время начальной задержки при посылке сообщений
Пропускная способность сети определяется скорость передачи информации по каналам связи
MPP – однородный мультикомпьютеры с однородной памятью – системы с массивно-параллельной архитектурой
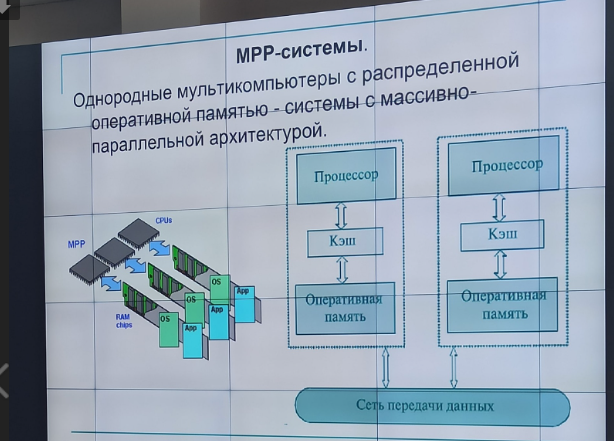
MPP система состоит из однородных вычислительных узлов, включающих:
Один или несколько центральных процессоров (обычно RISC)
Локальных блок оперативной памяти (прямой доступ к памяти других узлов невозможен)
Коммуникационный процессор или сетевой адаптер
Иногда жесткие диски и/или другие устройства ввода-вывода
В таких системах нужна специальная техника программирования для реализации обмена данных между процессорами (MPI)
(Детализация класса MIMD)
MIMD – ВС имеют несколько процессоров, которые функционируют асинхронно и независимо. В любой момент, различные процессоры могут выполнять различные команды над различными частями данных.
(Какой принцип распараллеливания используется при распараллеливании арифметических выражений?)
Наиболее известные алгоритмы распараллеливания арифметических выражений (Баера Бовета, Брента, Винограда) основаны на общем принципе: ориентированный ациклический граф, описывающий последовательное вычисление выражения E, т.к. в него все переменные входят только один раз, представляет собой бинарное дерево. К этому дереву применяются преобразования в соответствии с алгебраическими законами:
• коммутативности, например a*b=b*a;
• ассоциативности, например (a*b)*c=a*(b*c);
• дистрибутивности, например a*(b+c)=a*b+a*c.
(Почему арифметические выражения относят к классу задач с неявным параллелизмом?)
Поскольку порядок вычисления может быть изменен или доопределен таким образом, что бы некоторые операции можно было выполнять параллельно, говорят, что арифметические выражения обладают неявным параллелизмом.
ЯПФ – ярусно-параллельная форма. Алгоритм в ярусно-параллельной форме представляется в виде ярусов, причем в нулевой ярус входят операторы (ветви) независящие друг от друга, в первый ярус— операторы, зависящие только от нулевого яруса, во второй - от первого яруса и т. д. Таким образом ярусы ЯПФ устанавливают между операторами отношение предшествования – к моменту начала вычислений на ярусе должны быть закончены вычисления на прошлом ярусе.
(Какие основные свойства арифметических операций используются при преобразовании арифметических выражений в эквивалентные?)
Алгебраические законы:
• коммутативность, например a*b=b*a;
• ассоциативность, например (a*b)*c=a*(b*c);
• дистрибутивность, например a*(b+c)=a*b+a*c.
(Какие характеристики параллельности Вы знаете?)
Степенью параллелизма - отношение общего числа операций к числу ярусов дерева вычислений.
Ускорением параллельного алгоритма называют отношение Sp = Ti/t = w/t (число операций на количество ярусов)
Эффективность – отношение Ep = Sp/p (ускорение на количество процессоров)
(Чем характеризуется эффективность схемы при оптимальной загрузке процессоров?)
Чем ближе значение Sp (ускорение) к p (числу процессоров), а Ep (эффективность) – к 1, тем “лучше” построенный параллельный алгоритм.
Но еще лучше когда процессору нагружены равномерно и используется их оптимальное количество.
(В чем основной смысл леммы Брента?)
Лемма Брента позволяет, зная характеристики арифметического выражения при распараллеливании на неограниченном числе процессоров, оценить время реализации выражения на ограниченном числе вычислителей.
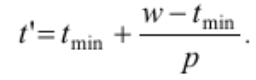
![]()
Современный векторно-конвейерные системы имеют иерархическую структуру:
На нижнем уровне иерархии расположены конвейеры операций сложения вещественных чисел, конвейер умножения
Некоторая совокупность конвейеров операций объединяется в конвейерное функциональное устройство
Векторно-конвейерный процессор содержит ряд конвейерных функциональных устройств
Несколько векторно-конвейерных процессоров, объединенных общей памятью, образуют вычислительный узел
Несколько таких узлов объединяются с помощью коммутаторов, образую либо NUMA-систему либо MPP-систему
Основное назначение векторных операций состоит в распараллеливании выполнения операторов цикла
Каждая ступень конвейера операций называется ступенью конвейера операций
Общее число ступеней – длина конвейера операций
Основные компоненты векторно-параллельного процессора:
Совокупность скалярных процессоров (Р)
Совокупность модулей оперативной памяти (М)
Коммуникативная среда
Устройство общего управления
Современные векторно-параллельные системы имеют иерархическую структуру:
На нижнем уровне находятся векторно-параллельные процессоры, представляющие собой совокупность скалярных процессоров (П)
П объединены коммуникативной сетью
В каждом такте П синхронно выполняют одну и ту же команду над разными данными
Несколько таких узлов объединяются общей памятью или коммуникативной сетью, образуя либо NUMA-систему либо MPP-систему
Динамическое (спекулятивное) исполнение – исполнение не в том порядке как это задано программным кодом, а в том, как удобно процессору
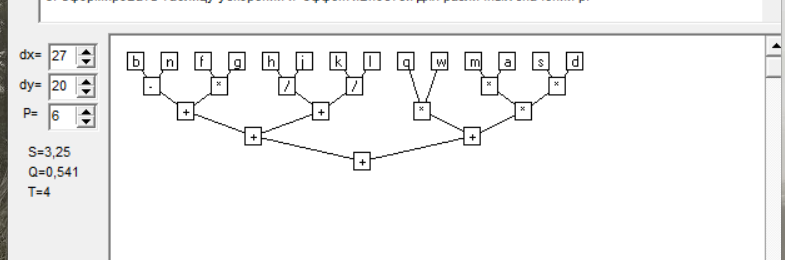
b-n+m*a*s*d+(f*g+h/j)+(k/l+q*w)
b-n+m*a*s*d+(f*g+h/j)+(k/l+q*w) – для программы
b-(n+(m*(a*(s*d)))+(((f*g)+(h/j))+((k/l)+(q*w))))
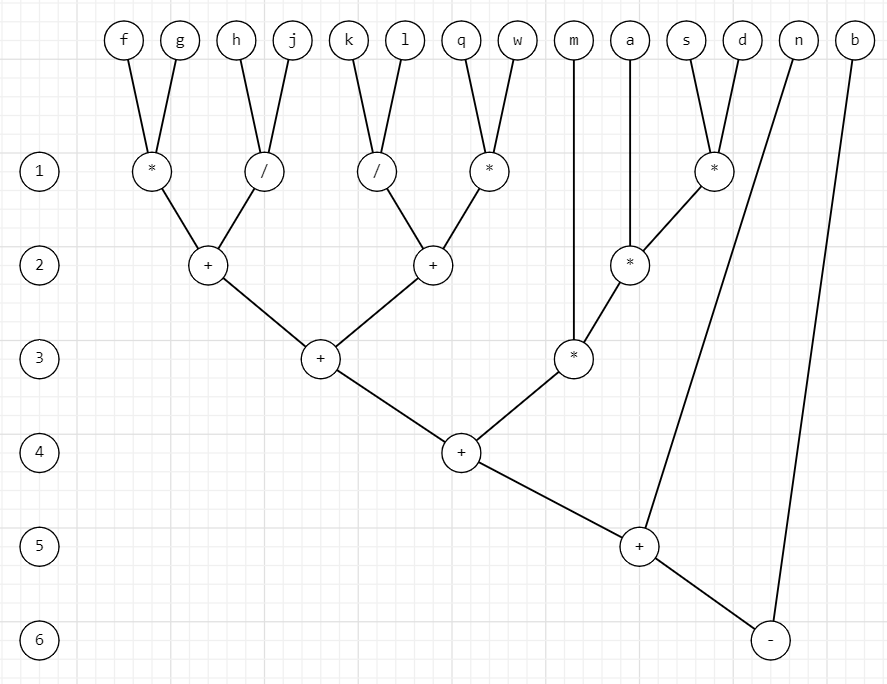
h = t = 6 - время, затрачиваемое на вычисление арифметического выражения
p = 5 - число процессоров
w = 13 – общее число операций
Dp = w/h = 13/6 = 2.17 - степень параллелизма
Ti = w = 13 - время выполнения “наилучшего” последовательного алгоритма
Sp = Ti/t = 13/6 = 2.17 – ускорение
Ep = Sp/p = 2.17/5 = 0.43 - эффективность
((b-n)+(((m*a)*s)*d))+((f*g)+(h/j))+((k/l)+(q*w))
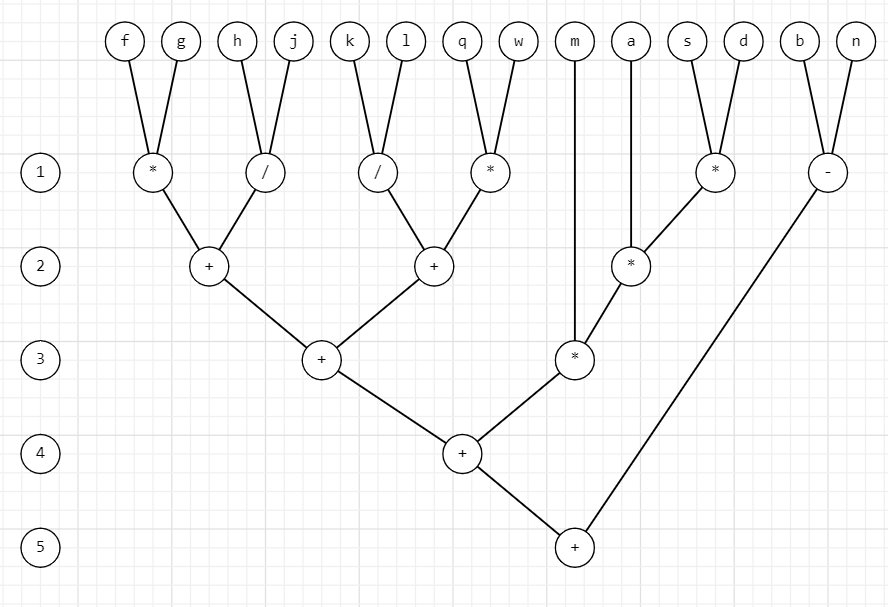
h = t = 5 - время, затрачиваемое на вычисление арифметического выражения
p = 6 - число процессоров
w = 13 – общее число операций
Dp = w/h = 13/5 = 2.6 - степень параллелизма
Ti = w = 13 - время выполнения “наилучшего” последовательного алгоритма
Sp = Ti/t = 13/5 = 2.6 – ускорение
Ep = Sp/p = 2.6/6 = 0.43 - эффективность
((b-n)+((m*a)*(s*d)))+(((f*g)+(h/j))+((k/l)+(q*w)))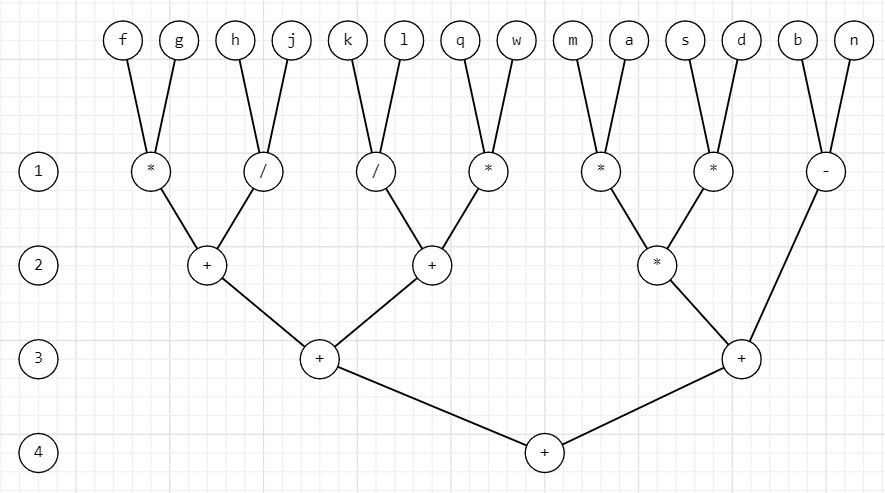
h = t = 4 - время, затрачиваемое на вычисление арифметического выражения
p = 7 - число процессоров
w = 13 – общее число операций
Dp = w/h = 13/4 = 3.25 - степень параллелизма
Ti = w = 13 - время выполнения “наилучшего” последовательного алгоритма
Sp = Ti/t = 13/4 = 3.25 – ускорение
Ep = Sp/p = 3.25/7 = 0.46 - эффективность
((b-n)+((m*a)*(s*d)))+(((f*g)+(h/j))+((k/l)+(q*w)))
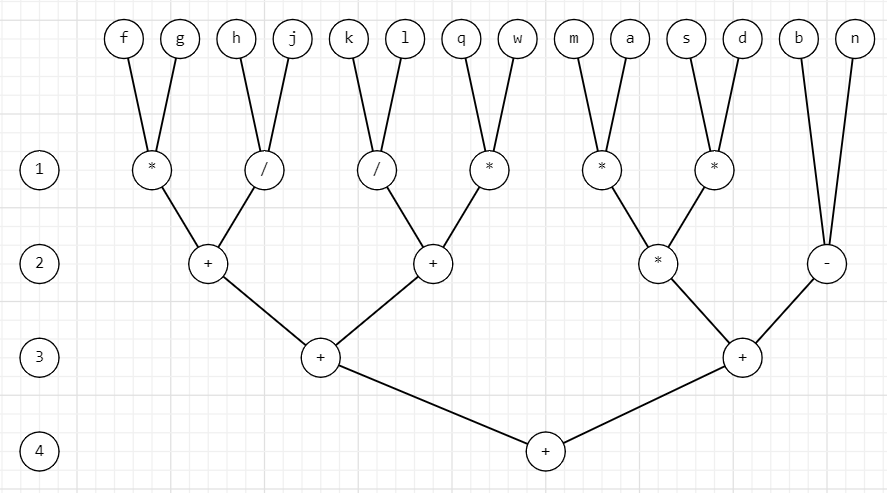
h = t = 4 - время, затрачиваемое на вычисление арифметического выражения
p = 6 - число процессоров
w = 13 – общее число операций
Dp = w/h = 13/4 = 3.25 - степень параллелизма
Ti = w = 13 - время выполнения “наилучшего” последовательного алгоритма
Sp = Ti/t = 13/4 = 3.25 – ускорение
Ep = Sp/p = 3.25/6 = 0.54 - эффективность