

3.2 Тестирование кластерной системы
Осуществим тестирование созданных приложений на основе параллельных алгоритмов рассмотренных выше в главе Алгоритмы.
Рассмотрим результаты тестирований приложений представленные в виде графиков зависимостей.
Вычисление частных сумм последовательности числовых значений (см. рис. 3.3), где ось Х – количество элементов подлежащих суммированию, У – получаемое ускорение, ломаные линии определенного цвета – результат, полученный при использовании определенного количества процессоров для вычисления.
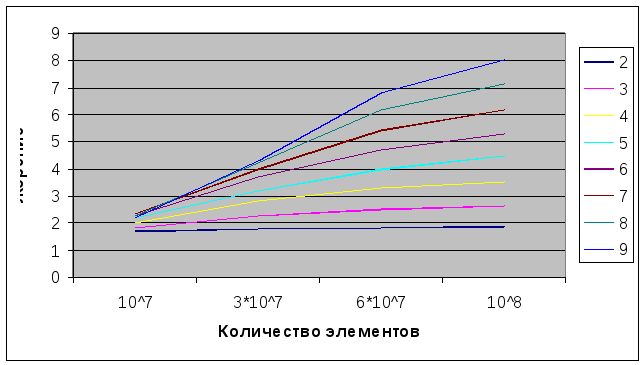
Рис. 3.3 Зависимость ускорения вычислений от количества элементов и числа
процессоров
Умножение матрицы на вектор (см. рис. 3.4), где ось Х – размер стороны квадратной матрицы, У – получаемое ускорение, ломаные линии определенного цвета – результат, полученный при использовании определенного количества процессоров для вычисления.

Рис. 3.4 Зависимость ускорения вычислений от размера матрицы, вектора и числа
процессоров
Матричное умножение (см. рис. 3.5), где ось Х – размер стороны квадратной матрицы, У – получаемое ускорение, ломаные линии определенного цвета – результат, полученный при использовании определенного количества процессоров для вычисления.

Рис. 3.5 Зависимость ускорения перемножения матриц от их размера и числа
процессоров
Сортировка (см. рис. 3.6), где ось Х – количество элементов подлежащих сортировке, У – получаемое ускорение, кривые линии с обозначениями – результат, полученный при использовании определенного количества процессоров для вычисления.

Рис. 3.6 Зависимость ускорения процесса сортировки от количества элементов и числа
процессоров
Интегрирование (см. рис. 3.7), где ось Х – количество интервалов интегрирования, У – получаемое ускорение, ломаные линии определенного цвета – результат, полученный при использовании определенного количества процессоров для вычисления.

Рис. 3.7 Зависимость ускорения вычислений от количества интервалов и числа
процессоров
Тестирование различных программ на созданном кластере дало следующие результаты:
Ускорение вычислений при увеличении числа процессоров;
Ускорение вычислений при использовании больших объемов данных.
Результаты вычислений наглядно показывают, что применение кластерной системы позволяет получить существенное ускорение при решении данной задачи. Также возможно получить лучшие результаты при работе с большими объемами данных. Эта особенность связана с техническими характеристиками используемой коммуникационной технологии Fast Ethernet, а именно с латентность (задержкой) при передаче данных. Чем больше данные мы посылаем на обработку, тем больше уходит время на полезную обработку, а не на передачу, так как задержка постоянна при любом объеме передаваемых данных.
3.3Выводы по главе 3
Рассмотрен процесс создания кластера на основе существующего компьютерного класса. Последовательность действий для его установки и запуска программ на нем. Были показаны результаты тестирования параллельных приложений на созданном кластере. Анализ результатов позволяет сделать вывод, что созданный кластер способен более эффективно решать параллельные задачи по сравнению с последовательными. Если в алгоритме задачи возможна параллельная обработка данных, то в зависимости от доли параллельных операций в алгоритме и количества узлов кластера можно добиться ускорения в несколько раз.