

Определение данных в SQL
Команды языка определения данных DDL (Data Definition Language, язык определения данных) - это подмножество SQL, используемое для определения и модификации различных структур данных.
К данной группе относятся команды предназначенные для создания, изменения и удаления различных объектов базы данных. Команды CREATE (создание), ALTER (модификация) и DROP (удаление) имеют большинство типов объектов баз данных (таблиц, представлений, процедур, триггеров, табличных областей, пользователей и др.). Т.е. существует множество команд DDL, например, CREATE TABLE, CREATE VIEW, CREATE PROCEDURE, CREATE TRIGGER, CREATE USER, CREATE ROLE и т.д.
Некоторым кажется, что применение DDL является прерогативой администраторов базы данных, а операторы DML должны писать разработчики, но эти два языка не так-то просто разделить. Сложно организовать эффективный доступ к данным и их обработку, не понимая, какие структуры доступны и как они связаны. Также сложно проектировать соответствующие структуры, не зная, как они будут обрабатываться.
Формат команды select
Язык запросов строится на единственном операторе SELECT, используемом чаще всех операторов языка SQL. Он производит выборки данных из таблиц БД и предоставляет их пользователям в необходимом виде. Практически SELECT реализует всю мощь реляционной алгебры.
Оператор SELECT состоит из нескольких предложений (разделов):
SELECT - определяет список возвращаемых столбцов (как существующих, так и вычисляемых), их имена, ограничения на уникальность строк в возвращаемом наборе, ограничения на количество строк в возвращаемом наборе;
FROM - задаёт табличное выражение, которое определяет базовый набор данных для применения операций, определяемых в других предложениях оператора;
WHERE - задает ограничение на строки табличного выражения из предложения FROM;
GROUP BY - объединяет ряды, имеющие одинаковое свойство с применением агрегатных функций
HAVING - выбирает среди групп, определённых параметром GROUP BY
ORDER BY - задает критерии сортировки строк; отсортированные строки передаются в точку вызова.
Простые запросы
Выведет список ВСЕХ баз.
SHOW databases;
Выведет список ВСЕХ таблиц в Базе Данных base_name.
SHOW tables in base_name;
SELECT – запрос, который выбирает уже существующие данные из БД. Для выбора можно указывать определённые параметры выбора. Например, суть запроса русским языком звучит так - ВЫБРАТЬ такие-то колонки ИЗ такой-то таблицы ГДЕ параметр такой-то колонки равен значению.
Выбирает ВСЕ данные в таблице tbl_name.
SELECT * FROM tbl_name;
Выведет количество записей в таблице tbl_name.
SELECT count(*) FROM tbl_name;
Выбирает (SELECT) из(FROM) таблицы tbl_name лимит (LIMIT) 3 записи, начиная с 2.
SELECT * FROM tbl_name LIMIT 2,3;
Выбирает (SELECT) ВСЕ (*) записи из (FROM) таблицы tbl_name и сортирует их (ORDER BY) по полю id по порядку.
SELECT * FROM tbl_name ORDER BY id;
Выбирает (SELECT) ВСЕ записи из (FROM) таблицы tbl_name и сортирует их (ORDER BY) по полю id в ОБРАТНОМ порядке.
SELECT * FROM tbl_name ORDER BY id DESC;
INSERT – запрос, который позволяет ПЕРВОНАЧАЛЬНО вставить запись в БД. То есть создаёт НОВУЮ запись (строчку) в БД.
Делает новую запись в таблице users, в поле name вставляет Сергей, а в поле age вставляет 25. Таким образом, в таблицу дописывается новая
строки с данными значениями. Если колонок больше, то они оставшиеся останутся либо пустыми, либо с установленными по умолчанию значениями.
INSERT INTO users (name, age) VALUES ('Сергей', '25');
UPDATE – запрос, который позволяет ПЕРЕЗАПИСАТЬ значения полей или ДОПИСАТЬ что-то в уже существующей строке в БД. Например, есть готовая строка, но в ней нужно перезаписать параметр возраста, так как он изменился со временем.
В таблице users ГДЕ id равно 3 значение поля age становится 18.
UPDATE users SET age = '18' WHERE id = '3';
Всё то же самое, что и в первом запросе, просто показан синтаксис запроса, где перезаписываются два поля и более.
В таблице users ГДЕ id равно 3 значение поля age становится 18, а country Россия.
UPDATE users SET age = '18', country = 'Россия' WHERE id = '3';
DELETE – запрос, который удаляет строку из таблицы.
Удаляет строку из таблицы users ГДЕ id равен 10.
DELETE FROM users WHERE id = '10';
DROP – запрос, который удаляет таблицу.
Удаляет целиком таблицу tbl_name.
DROP TABLE tbl_name;
Выборка по условию
Условия позволяют указать какие строки таблицы нужно вывести в результате выполнения запроса. Задаются они после указания необходимых столбцов и таблиц командой WHERE.
Условие на выборку добавляется при составлении большинства запросов. Они позволяют отсеять не нужные строки, путем указания тех или иных параметров отбора. В результате можно из больших таблиц быстро выбрать необходимые строки. Именно это и была основная задумка при создании языка запросов для БД.
Ещё IN и FROM

Выборка на основе between …. And
SQL условие BETWEEN позволяет легко проверить, находится ли выражение в диапазоне значений (включительно). Его можно использовать в операторе SELECT, INSERT, UPDATE или DELETE. Значения могут быть числами, текстом или датами.
Оператор BETWEEN является инклюзивным: включаются начальное и конечное значения.
SELECT column_name(s) FROM table_name
WHERE column_name BETWEEN value1 AND value2;
Выборка на основе like, in
LIKE:
Определяет, совпадает ли указанная символьная строка с заданным шаблоном. Шаблон может включать обычные символы и символы-шаблоны. Во время сравнения с шаблоном необходимо, чтобы его обычные символы в точности совпадали с символами, указанными в строке. Символы-шаблоны могут совпадать с произвольными элементами символьной строки. Использование символов-шаблонов в отличие от использования операторов сравнения строки (= и !=) делает оператор LIKE более гибким. Если тип данных одного из аргументов не является символьной строкой, компонент Компонент SQL Server Database Engine, если это возможно, преобразует его в тип данных символьной строки.
В сочетании с оператором LIKE используются два подстановочных знака:
% - Знак процента представляет нулевой, один или несколько символов
_ - Подчеркнутый символ представляет собой один символ

IN:
Определяет, совпадает ли указанное значение с одним из значений, содержащихся во вложенном запросе или списке.
Сортировка строк
Для выполнения сортировки в строку запроса нужно добавить команду ORDER BY. После этой команды указывается поле, по которому производится сортировка.
Сортировка
строк чаще всего проводится вместе с
условием на выборку данных. Команда
ORDER BY ставится после условия выборки
WHERE. Например, выбираем товары с ценой
меньше 100 рублей, упорядочив по названию
в алфавитном порядке:![]()
SELECT * FROM goods – указывает выбрать все поля из таблицы goods; ORDER BY – команда сортировки;
title – столбец, по которому будет выполняться сортировка.
По умолчанию, команда ORDER BY выполняет сортировку по возрастанию. Чтобы управлять направлением сортировки вручную, после имени столбца указывается ключевое слово ASC (по возрастанию) или DESC (по убыванию).
Группировка строк
Оператор SQL GROUP BY служит для распределения строк - результата запроса - по группам, в которых значения некоторого столбца, по которому происходит группировка, являются одинаковыми. Группировку можно производить как по одному столбцу, так и по нескольким.
Часто
оператор SQL GROUP BY применяется вместе с
агрегатными функциями (COUNT, SUM, AVG, MAX,
MIN). В этих случаях агрегатные

Вычисляемые выражения и статистические функции
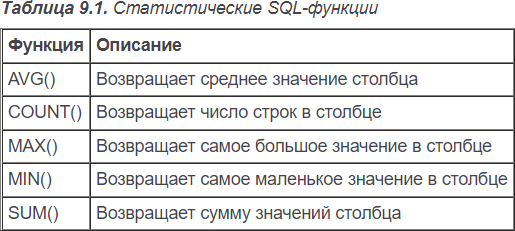
Функция AVG() используется для возвращения среднего значения определенного столбца путем подсчета числа строк в таблице и суммирования их значений. Эту функцию можно использовать для возвращения среднего значения всех столбцов или определенных столбцов или строк.
Функция COUNT() подсчитывает число строк. При помощи функции COUNT() можно узнать общее число строк в таблице или число строк, удовлетворяющих определенному критерию.
Эту функцию можно использовать двумя способами:
В виде COUNT(*) для подсчета числа строк в таблице независимо от того, содержат столбцы значения NULL или нет.
В виде COUNT(column) для подсчета числа строк, которые имеют значения в указанных столбцах, причем значения NULL игнорируются.
Функция МАХ() возвращает самое большое значение из указанного столбца. Для этой функции необходимо указывать имя столбца, как это показано ниже.
Функция MIN() производит противоположное по отношению к МАХ() действие – она возвращает наименьшее значение в указанном столбце.
Функция SUM() возвращает сумму (общую) значений в определенном столбце.
Выборка групп
Формализация знаний
Представление и описание предметной области человеческой деятельности в виде организованных данных понимают как формализация знаний. Приведение данных, поступающих из разных источников, к одинаковой форме, необходимо для повышения их уровня доступности в информационных системах
Продукционная модель представления знаний
вариант ответа:

вариант ответа:
Продукционная модель представления знаний — это модель, которая базируется на определённых правилах и даёт возможность выразить знание в форме предложений типа «Если (условие), то (действие)»
Традиционная продукционная модель знаний включает в себя следующие базовые компоненты:
набор правил (или продукций), представляющих базу знаний продукционной системы;
рабочую память, в которой хранятся исходные факты, а также факты, выведенные из исходных фактов при помощи механизма логического вывода;
сам механизм логического вывода, позволяющий из имеющихся фактов, согласно имеющимся правилам вывода, выводить новые факты.
Исчисление предикатов первого порядка 1 вариант ответа:
Формальная система, называемая исчислением предикатов первого порядка, или логикой предикатов первого порядка, является расширением логики высказываний. Логика предикатов дает возможность более детально рассматривать, а следовательно, более точно формализовать знания и рассуждения о свойствах объектов предметной области.
В логике высказываний пропозициональные символы служат для обозначения простых высказываний (утверждений) о предметной области, представляющих собой с точки зрения русского языка простые (с одной грамматической основой) повествовательные предложения. Логические связки логики высказываний обозначают следующие союзы или словосочетания и их синонимы:
-л — «не», «неверно, что»,
V — «или», «либо», л — «и», «а», «но»,
-> — «если», «при условии, что»,
= — «равносильно», «эквивалентно», «тогда и только тогда, когда».
В силу этого формулы логики высказываний обозначают простые или сложные (с несколькими грамматическими основами) повествовательные предложения, в которых выражены свойства предметной области.
Исчисление высказываний не «проникает» внутрь простого высказывания, т.е. не учитывает его внутренней структуры.
2 Вариант ответа:
Логика первого порядка(исчисление предикатов) — формальное исчисление, допускающее высказывания относительно переменных, фиксированных функций и предикатов. Расширяет логику высказываний.
Язык логики первого порядка строится на основе сигнатуры, состоящей из множества функциональных символов {F} и множества предикатных символов {P}. С каждым функциональным и предикатным символом связана арность, то есть число возможных аргументов. Допускаются как функциональные, так и предикатные символы арности 0.
Фрейм
Под фреймом понимается однажды определенная единица представления знаний, которую можно изменять лишь в деталях согласно текущей ситуации. Теория фреймов предложена М. Минским в 1974 г.
В основе данной модели представления знаний лежит свойство концептуальных объектов иметь аналогии, которые позволяют строить иерархические структуры отношений типа “абстрактное-конкретное”. Каждый фрейм следует рассматривать как сеть из нескольких вершин и отношений. На самом верхнем уровне фрейма представляется фиксированная информация о состоянии моделируемого объекта, которая является истинной вне зависимости от контекста рассмотрения объекта и соответствует имени фрейма.
Семантическая сеть
Семантическая сеть — информационная модель предметной области, имеет вид ориентированного графа, вершины которого соответствуют объектам предметной области, а ребра задают отношения между ними. Объектами могут быть понятия, события, свойства, процессы.
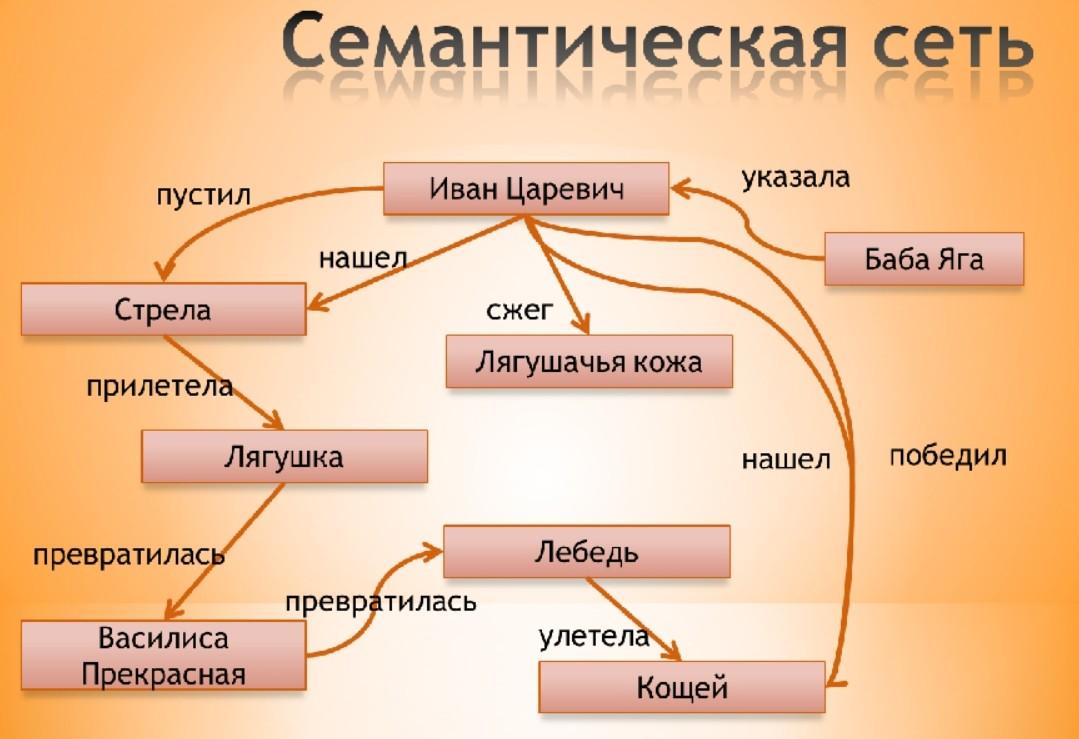
В качестве понятий обычно выступают абстрактные или конкретные объекты (огурец, машина, любовь, Маша). В качестве отношений наиболее часто используются следующие (смысловая классификация) [19, 31]:
таксономические («класс – подкласс – экземпляр»,
«множество – подмножество – элемент» и т.п.). Данный тип отношения называют также отношением AKO (англ. A Kind Of
является разновидностью), IS A (является, это есть) или гипонимии (гипероним – общая сущность; гипоним – частная сущность);
структурные («часть – целое»). Данный тип отношения называют также отношением Part of (является частью), Has part (состоит из, включает в себя), агрегации (лат. aggregatio – присоединение), композиции (лат. compositio – составление, связывание, сложение, соединение) или меронимии (холоним
сущность, включающая в себя другие; мероним – сущность, являющаяся частью другой);
родовые («предок» - «потомок»);
производственные («начальник» - «подчиненный»);
функциональные (определяемые обычно глаголами
«производит», «влияет» и т.п.);
количественные (больше, меньше, равно и т.п.);
пространственные (далеко от, близко от, за, под, над и т.п.);
временные (раньше, позже, в течение и т.п.);
атрибутивные (иметь свойство, иметь значение);
логические (И, ИЛИ, НЕ);
казуальные (причинно-следственные).
Отношения можно также классифицировать по степени участия
(арности) понятий в отношениях:
унарное (рекурсивное) - отношение связывает понятие само с собой;
бинарное - отношение связывает два понятия;
N-арное - отношение, связывающее более двух понятий.