

МТУСИ
Интеллектуальные системы
Дизайн И.. Гайдель 2007
Лекция 15

Дизайн И. Гайдель 2007
Генеративное глубокое обучение
Искусственный интеллект пока не может состязаться с людьми, сценаристами, художниками и композиторами. Впрочем, замена человека никогда не была главной целью: ИИ предполагался не для замены нашего интеллекта, а для вовлечения интеллекта в нашу жизнь и работу. Во многих областях, и особенно в творчестве, ИИ будет использоваться людьми как инструмент для расширения своих возможностей: более широких, чем возможности искусственного интеллекта.
Модели машинного обучения могут изучать скрытое статистическое пространство изображений, музыки и литературных произведений, а затем, основываясь на образах из этого пространства, создавать новые произведения с характеристиками, схожими с теми, что модель видела в обучающих данных.
Естественно, создание таких произведений трудно назвать актом творчества. Это простая математическая операция: алгоритм не имеет опыта человеческой жизни, человеческих эмоций или нашего практического опыта; он учится на опыте, который имеет мало общего с нашим. Это только наша интерпретация как наблюдателей, придающая смысл тому, что генерирует модель. 
Дизайн И. Гайдель 2007
Генеративное глубокое обучение
Краткая история
В конце 2014 года даже в сообществе машинного обучения мало кто был знаком с аббревиатурой LSTM. Успешное применение методов генерации последовательностей данных с помощью рекуррентных сетей начало приобретать широкую известность только в 2016 году. Но сами методы имеют довольно давнюю историю, начиная с разработки алгоритма LSTM в 1997 году. Этот новый алгоритм первое время использовался для генерации текстов символ за символом.
Дизайн И. Гайдель 2007
Генеративное глубокое обучение
Как генерируются последовательности данных
Универсальный способ генерации последовательностей данных с применением методов глубокого обучения заключается в обучении модели (обычно рекуррентной) для прогнозирования следующего токена или следующих нескольких токенов в последовательности, опираясь на предыдущие токены.
Например, для входной последовательности «Кошка лежит на …» модель обучается предсказывать следующее целевое слово «коврике».
Как обычно, при работе с текстовыми данными в роли токенов часто выступают слова или символы, и любая сеть, моделирующая вероятность появления следующего токена на основе предыдущих, называется языковой моделью. Языковая модель фиксирует скрытое пространство языка, его статистическую структуру.
Дизайн И. Гайдель 2007
Генеративное глубокое обучение
Как генерируются последовательности данных
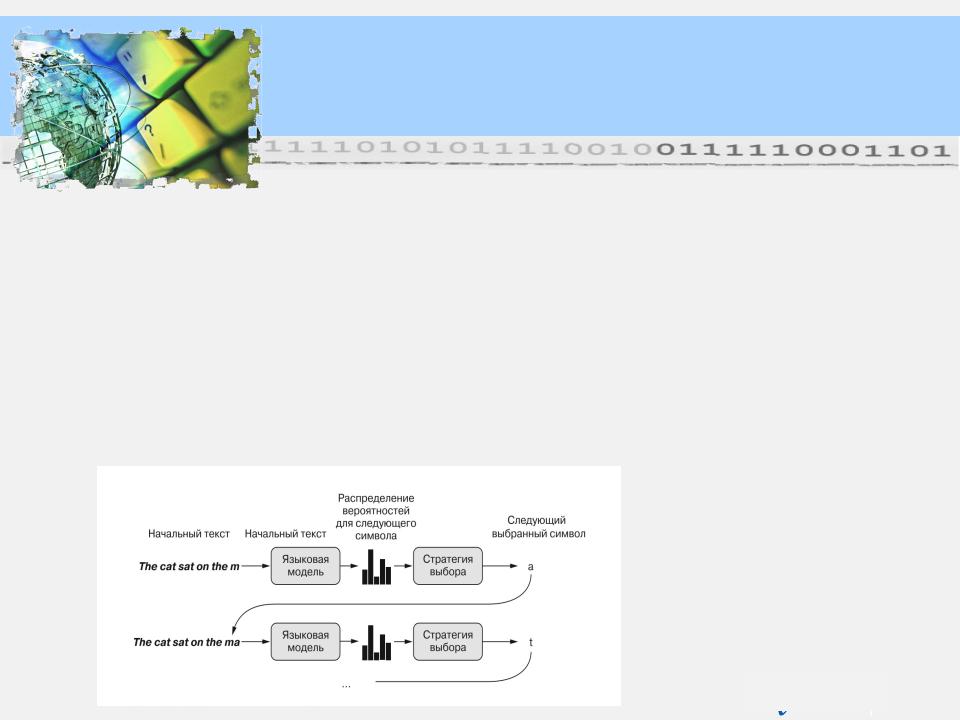
После получения такой обученной языковой модели мы можем извлекать образцы из нее (генерировать новые последовательности): передать ей начальную строку текста (так называемые кондиционные данные), попросить сгенерировать следующий символ или слово (можно даже сгенерировать несколько слов сразу), добавить сгенерированный вывод в конец предыдущих входных данных и повторить процесс много раз.
Этот цикл позволяет генерировать последовательности произвольной длины, отражающие структуру данных, на которых обучалась модель: последовательности, которые выглядят почти как предложения, написанные человеком.
Процесс пословной генерации текста с использованием языковой модели
Дизайн И. Гайдель 2007
Генеративное глубокое обучение
Стратегии выбора
Для генерации текста важную роль играет алгоритм выбора следующего токена.
Простейшее решение — жадный выбор, когда выбирается наиболее вероятный символ. Но такой подход приводит к получению повторяющихся, предсказуемых строк, которые не выглядят связными предложениями.
Намного интереснее подход, который делает порой неожиданный выбор, вводя случайную составляющую в процесс выбора из распределения вероятностей для следующего символа. Этот подход называется стохастическим выбором. Таким образом, если слово имеет вероятность 0,3 стать следующим в предложении, согласно модели мы выберем его в 30 % случаев.
Жадный выбор тоже может использоваться для выбора из распределения вероятностей, когда какой-то символ имеет вероятность 1, а все остальные — вероятность 0.
Дизайн И. Гайдель 2007
Генеративное глубокое обучение
Стратегии выбора
Вероятностный выбор является хорошим решением: он позволяет время от времени появляться в выводе даже маловероятным символам, генерировать более интересные предложения и иногда демонстрировать творческую жилку, придумывая новые, реалистично звучащие слова, которые отсутствуют в обучающих данных.
Однако здесь есть одна проблема: эта стратегия не предусматривает возможности управлять величиной случайности в процессе выбора.
Вопрос: зачем может понадобиться увеличивать или уменьшать случайную составляющую?
Дизайн И. Гайдель 2007
Генеративное глубокое обучение
Стратегии выбора
Рассмотрим крайний случай: случайный выбор, когда следующее слово выбирается из равномерно распределенных вероятностей и каждое слово одинаково вероятно. Эта схема имеет максимальную случайность; иными словами, это распределение вероятностей имеет максимальную энтропию.
С другой стороны, жадный выбор, имеющий минимальную энтропию, не производит ничего интересного, так как все предсказуемо.
Интересные решения, получающиеся путем выбора из «реального» распределения вероятностей, находятся между этими двумя крайностями. Так как есть еще множество других промежуточных точек с большей или меньшей энтропией. Меньшая энтропия позволит генерировать последовательности с более предсказуемой структурой (и потому выглядящие более реалистичными), тогда как большая энтропия даст более неожиданный и творческий результат.
Выбирая результаты из генеративных моделей, всегда полезно исследовать разные величины случайности в процессе генерации. Поскольку высшими судьями, определяющими, насколько интересны сгенерированные данные, являемся мы, люди, интересность оказывается весьма субъективной величиной, и поэтому нельзя сказать наперед, где лежит точка оптимальной энтропии.
Дизайн И. Гайдель 2007
Генеративное глубокое обучение
Стратегии выбора
Для управления величиной случайности в процессе выбора введем параметр, который назовем температурой, характеризующий энтропию распределения вероятностей, используемую для выбора: она будет определять степень необычности или предсказуемости выбора следующего символа. С учетом значения temperature и на основе оригинального распределения вероятностей будет вычисляться новое распределение.
Модель «последовательность в последовательность»
Цель — обучить модель прогнозировать распределение вероятностей для выбора следующего слова в предложении с учетом некоторого количества начальных слов. После обучения модели мы дадим ей подсказку, затем выберем следующее слово, добавим его в конец подсказки и снова передадим модели. И будем повторять это действие до тех пор, пока не сгенерируем короткий абзац.
Дизайн И. Гайдель 2007
Генеративное глубокое обучение
Стратегии выбора
Обучая модель для предсказания следующего токена по предшествующим, можно генерировать последовательности дискретных данных. Выбор следующего токена требует баланса между мнением языковой модели и случайностью. Обеспечить такой баланс можно путем вариации параметра temperature.
Рекомендуется использовать |
разные температуры, чтобы найти |
правильную. |
|