

ММТССиПД_ns2_метода
.pdfNs2 имеет генератор Парето случайных чисел, который использует характеристический показатель распределения α и масштабный коэффициент
b:
double pareto(double scale, double shape)
Когда генератору трафика Парето необходимо сосчитать величину next_burstlen, он выполняет:
int next_burstlen = int(pareto(b1, a) + 0.5);
/* величина next_burstlen должна быть не меньше, чем один пакет */
if(next_burstlen == 0) next_burstlen = 1;
Расчет величины next_idle_time:
double next_idle_time = pareto(b2, a);
4.3.2 СОЗДАНИЕ СЛУЧАЙНЫХ ВЕЛИЧИН
Если необходимо создать трафик, две величины которого распределены по разным законам (например, M/D), то необходимо создавать независимые случайные величины вручную и описывать процедуры передачи пакетов в соответствии со случайными величинами.
При создании случайных переменных используются сиды (seeds) –
начальные числа (при генерации псевдослучайных последовательностей). При значении seed=0 каждый запуск моделирования возвращает новую случайную переменную. Если используются другие значения seed, то при каждом новом запуске моделирования возвращается одна и та же последовательность случайных величин. По умолчанию в ns2 seed=1.
Для создания случайных переменных необходимо создать новый генератор и назначить ему seed.
set MyRng [new RNG] $MyRng seed 2
Далее создаются сами случайные переменные, распределенные по закону Парето, постоянному закону, равномерному закону,
экспоненциальному или гиперэкспоненциальному3.
3 В версии ns-2.30 появилась возможность создавать переменные, распределенные по закону Вейбулла
(Weibull).
53
Рассмотрим создание случайной величины на примере величины,
распределенной по закону Парето:
set r1 [new RandomVariable/Pareto] $r1 use-rng $MyRng
$r1 set avg_ 10.0 $r1 set shape_ 1.5
Где avg_ – математическое ожидание (среднее значение), а shape_ –
характеристический показатель распределения (shape parameter).
Для создания моделей СМО необходимо описать две переменные – длительность интервалов между моментами поступления требований и размер пакета. Более подробно алгоритм создания моделей СМО на ns2 описан в [4].
5. ВИДЫ ПРЕДСТАВЛЕНИЯ РЕЗУЛЬТАТОВ МОДЕЛИРОВАНИЯ НА NS2
5.1. Визуализатор nam (network animator)
Ns2 содержит средство анимации результатов моделирования – nam (Network Animator). Nam графически воспроизводит имитационную модель
(топология сети, анимация прохождения пакетов по сети, постановки их в очередь и т.д.) и наглядно показывает алгоритмы работы протоколов,
дисциплин обслуживания очередей. Он может служить наглядным пособием не только в научных, но и в учебных целях. Запустить nam можно либо с помощью команды nam <nam-file>, где <nam-file> – имя трейс-файла nam,
созданного ns2, либо выполнить запуск прямо из скрипта моделирования
OTcl.
Интерфейс пользователя (рис. 5.1) содержит зону анимации, несколько меню и кнопок. В меню “views” находится четыре пункта:
• New view – создает новый вид той же анимации. Пользователь может увеличивать и прокручивать изображение в новом окне. Все виды работают
синхронно.
54
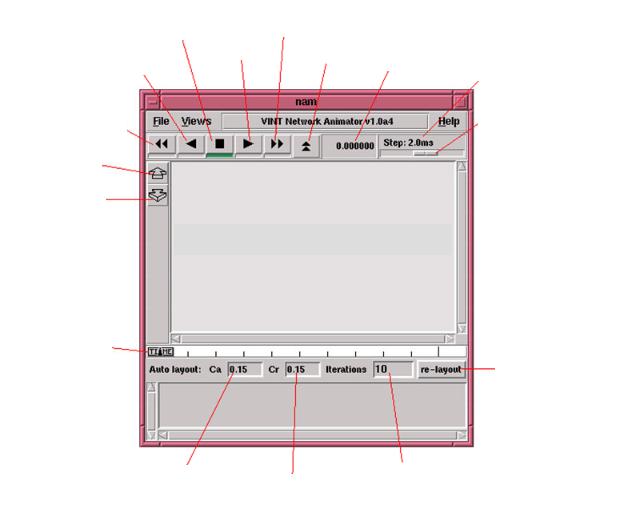
•Show monitors – показывает окно в нижней части экрана, где осуществляется мониторинг.
•Show autolayout – показывает окно в нижней части экрана, которое содержит окна для ввода данных и кнопки для настроек автоматического расположения.
•Show annotation – показывает пункт в нижней части экрана с примечаниями по мере увеличения модельного времени.
Рис. 5.1. Пользовательский интерфейс визуализатора nam
Под панелью меню находятся кнопки перемотки назад, запуска анимации в обратную сторону, остановки анимации, запуска анимации,
перемотки вперед и выхода из nam, индикатор текущего времени анимации и
55
движок изменения скорости анимации (текущая скорость изображена над
ним).
Также возможно увеличения и уменьшения изображения с помощью кнопок расположенных в левой части экрана.
Изменять текущее время анимации пользователь может при помощи движка времени анимации.
Под движком времени анимации находится панель автопланировки топологии сети (изначально может отсутствовать). Существует три параметра для настройки процесса автоматической планировки:
•Ca – константа притягивающего воздействия между узлами,
которая контролирует силу сжатия между узлами в зоне анимации.
•Cr – константа отталкивающего воздействия между узлам,
которая контролирует силу отталкивания между узлами в зоне анимации.
• Количество итераций – определяет сколько раз запускать процедуру автопланировки.
Для маленьких топологий с десятками узлов использование исходных параметров (с 20-30 итерациями) достаточно для изображения приемлемого вида сети. Но для больших топологий необходимо изменение этих параметров.
Основные команды ns2, управляющие видом сети в визуализаторе nam
были описаны в главе 4. Кроме этого в nam есть ещё набор функций:
•Изменение цвета звена, например:
$ns duplex-link-op $n0 $n2 color "green"
•Выделение цветом узла:
$ns at 2.0 "$n3 add-mark m3 blue" $ns at 20.0 "$n3 delete mark m3"
На примере со второй секунды моделирования по двадцатую узел n3
выделяется голубым цветом.
•Добавление обозначений узлов и звеньев:
$ns at 2.0 "$n3 label \"active node\""
$ns duplex-link-op $n0 $n2 label "TCP input link"
56

•Добавление текста в нижней панели nam
$ns at 2.0 "$ns trace-annotate \"packet drop\""
5.2. Файлы трассировки
Обработка результатов моделирования является целью самого моделирования. Программа моделирования, которая просто воспроизводит сеть, а не дает какой-то точный результат моделирования (такая как nam),
может быть использована только в качестве наглядного пособия. Для научных исследований же нужны точные результаты моделирования. Результатом моделирования в ns2 являются различные виды трейс-файлов. Трейс-файл представляет собой текст в формате ASCII, в котором зарегистрированы необходимые события моделирования. Самым распространенным видом трейс-файлов в ns2 является обычный (normal) трейс-файл, в котором регистрируются все события, происходящие в моделируемой сети. Для того,
чтобы такой трейс-файл был создан, необходимо в текст программы на языке
OTcl добавить:
set f [open out.tr w]
$ns trace-all $f
Эти строки добавляют объекты трассировки во все звенья сети. Имя трейс-файла может быть произвольным. Расширение рекомендуется использовать “tr”. В принципе, расширение может быть также произвольным,
но некоторые программы обработки результатов, написанные для платформ
Windows (например, Tracegraph) , считывают файлы только с расширением
“tr”.
Идент. потока – идентификатор потока Адр. ист. – адрес источника Адр. получ. – адрес получателя Поряд. номер – порядковый номер
Идент. пакета – идентификатор пакета
Рис. 5.2. Формат строки обычного трейс-файла
57
Каждая строчка трейс-файла состоит из двенадцати полей (рис. 5.2),
разделенных пробелом.
В поле «событие» может стоять несколько символов: r: принятие пакета узлом;
+: постановка в очередь; –: снятие с очереди;
d: отбрасывание пакета в очереди.
Поле «время» показывает модельное время данного события в секундах.
Следующие два поля: «от узла» и «к узлу» показывают, в каком звене происходит данное событие. То есть, поле «от узла» означает последний узел,
который обрабатывал данный пакет, а «к узлу» в каком направлении этот пакет отправлен.
Поле «тип пакета» указывает на то, к какому приложению или агенту относится данный пакет. Причем, если транспортным агентом является агент
UDP, то указывается приложение (CBR, pareto и др.), а если TCP, то указывается “tcp” или “ack” (подтверждение tcp) вне зависимости, какое приложение создало этот пакет.
Следующее поле показывает размер пакета на сетевом уровне с учетом заголовка IP.
Поле «флаги» содержит шесть флагов. Четыре из них используются для явного извещения о перегрузке (ECN – Explicit Congestion Notification):
“E” – опытная индикация перегрузки (Congestion Experienced indication
– CE);
“N” – индикация явного извещения о перегрузке с возможностью переноса (ECN-Capable-Transport – ECT);
“C” – эхо явного извещения о перегрузке (ECN-echo – ECE);
“A” – сокращение окна перегрузки (Congestion Window Reduced –CWR).
Первые два заполняют биты 6 и 7 в заголовке IP в поле ToS, а
следующие два в заголовке TCP.
Остальные два флага:
58
“P” – приоритет (priority);
“F” – быстрый старт TCP (TCP Fast Start).
Поле «идентификатор потока» совпадает с полем ”fid” (flow ID) в
заголовке IPv6. Такой идентификатор пользователь может установить в тексте программы для каждого потока. Его можно использовать для анализа сети, а
также для использования разных цветов в визуализаторе nam.
Следующие поля: «адрес источника» и «адрес получателя», имеют
формат: узел.порт. (например: 1.0).
Следующее поле показывает порядковый номер пакета на транспортном уровне. Причем, необходимо отметить, что протокол UDP хотя и не использует порядковые номера в реальной сети, ns2 отслеживает порядковые номера UDP для целей анализа.
Последнее поле показывает уникальный идентификатор пакета.
Ниже приведен отрывок из трейс-файла:
+0.02896 2 3 tcp 1040 ------- 2 4.0 3.1 2 3 - 0.02896 2 3 tcp 1040 ------- 2 4.0 3.1 2 3
+0.03 5 2 tcp 40 ------- 4 5.0 3.3 0 4
- 0.03 5 2 tcp 40 |
------- |
4 5.0 3.3 0 4 |
|
|
|
||||||
r 0.03096 |
2 |
3 |
tcp |
1040 ------- |
|
2 4.0 3.1 |
1 |
2 |
|||
+ |
0.03096 |
3 |
2 |
ack |
40 ------- |
2 |
3.1 |
4.0 |
1 |
5 |
|
- |
0.03096 |
3 |
2 |
ack |
40 ------- |
2 |
3.1 |
4.0 |
1 |
5 |
|
Существуют и другие форматы трейс-файлов. Одним из наиболее важных является трейс-файл для визуализатора nam. Он создается следующим образом:
set nf [open out.nam w]
$ns namtrace-all $nf
Этот файл обязательно должен иметь расширение “nam”. Он использует nam для воспроизведения анимации, и для дальнейшей обработки он не предназначен. Но при необходимости его можно использовать для последующего анализа.
Также существуют различные трейс-файлы для мониторинга очередей каждый из которых имеет свою структуру.
59
Несколько видов трейс-файлов предназначено для регистрации событий в беспроводных сетях.
Если результатом моделирования должно являться только одно значение и нет необходимости применять трейс-файлы, то можно все необходимые вычисления произвести внутри программы и с помощью Tcl-
команды puts вывести результат на экран.
Вид трейс-файлов ns2 очень удобен для дальнейшей обработки. Все они представляют собой текстовые файлы в коде ASCII в табулированной форме.
Файлы таких типов могут обрабатывать множество инструментов во все операционных системах. Основные методы и программы обработки будут рассмотрены в следующем разделе.
5.3.Утилиты обработки файлов трассировки
5.3.1.УТИЛИТА AWK
Результатом работы пакета ns2 являются файлы трассировки. Для того,
чтобы дальше можно было заниматься анализом моделирования, необходимо извлечь ту часть данных, которая потребуется для дальнейших действий. Для этого в системах Unix разработан специальный язык AWK.
AWK – утилита, предназначенная для простых (механических и вычислительных) манипуляций над данными. Довольно несложные операции часто необходимо выполнить над целыми группами файлов, а писать для этого программу на одном из стандартных языков программирования является, как правило, не очень простым делом. Оптимальное решение проблемы – использование специальной утилиты AWK, включающей в себя негромоздкий и удобный язык программирования, позволяющий решать задачи обработки данных с помощью коротких программ, состоящих из двух-
трех строк.
Утилита AWK была создана в 1977г, американскими авторами: Alfred
V. Aho, Brian W. Kernighan и Peter J. Weinberger. AWK (Aho-
Weinberger-Kernighan). AWK входит в состав многих пакетов Unix-like
60
программ для ОС Windows, в том числе Cygwin. Исходный код на языке С доступен в полном пакете Linux.
AWK использует метод поиска по шаблону (pattern matching). Она оперирует двумя видами входных данных: файлом данных и командным файлом. Файл данных должен представлять собой не обычный текст, а
упорядоченные данные, состоящие из строк, которые в свою очередь состоят из групп знаков (слов). Разделителем групп знаков по умолчанию является пробел, но в командной строке могут быть определены и другие виды разделителей. Командный файл содержит инструкции (команды) поиска по шаблону. Таким образом, AWK является интерпретатором, исполняющим действия, записанные в командном файле, над файлом данных.
Все команды одновременно могут использовать все переменные программы AWK и только одну строку из файла данных. Строка является предметом поиска по шаблону. Она автоматически загружается в специальные переменные. Переменная $0 содержит всю строку, переменная $1 – первое слово в строке, $2 – второе слово и т.д. (максимальное количество
– 100 слов).
AWK может быть использован для извлечения частей из большого текста, форматирования текста и извлечения информации для других программ. Это очень универсальная программа, особенно она полезна при использовании внутри других программ (например, таких как ns2).
При моделировании в ns2 AWK можно запустить двумя способами.
Первый – это создать отдельный файл с кодом AWK. Например, код,
вычисляющий среднее значение чисел, записанных в четвертой колонке.
BEGIN {FS =" "}{nl++} {s=s+$4} END {print "average:" s/nl}
Если столбцы разделены не пробелом, а знаком табуляции, то вместо FS =" " необходмо вставить FS ="/t"/.
После моделирования, когда получен файл данных (трейс-файл), с
помощью специальной команды запустить обработку файла. Например, пусть
61
файл с кодом awk называется code.awk, а файл данных – out.tr, тогда необходимо прописать команду:
awk –f code.awk out.tr
Второй способ – включить код AWK в текст программы
моделирования. Например:
proc finish {} { global ns f nf $ns flush-trace set awkCode {
{
if ($1 == "+") { print $2>> "temp.d";
}
}
{
if ($3 == "2" && $4=="3") { print $0>> "temp.a";
}
}
}
exec awk $awkCode par.tr close $f
close $nf
exec nam out.nam & exit 0
}
В данном примере код awk включен в процедуру finish с помощью команды set awkCode {# код AWK}. Выполнение кода осуществляется с помощью команды exec awk $awkCode par.tr. Здесь файлом данных служит файл par.tr. Ещё один плюс этого варианта – это то, что обработка трейс-
файла происходит сразу после моделирования, при этом пользователь не вводит никаких дополнительных команд.
5.3.2. УТИЛИТА GREP
Утилита grep является утилитой, работающей в режиме командной строки в системах Unix/Linux. C помощью grep можно создать новый файл,
который состоит только из тех строк исходного файла, которые включают в
62