

4.3 Защита программ.
Стратегии защиты программ и защиты данных имеют много общего , но имеются и различия. При этом защита как программ, так и данных на одном уровне привилегий производится на основе разделения адресных пространств механизмом виртуальной памяти при помощи локальных таблиц дескрипторов, каталогов и страниц. При обращении к программам также производятся проверки на выход за пределы сегмента и таблиц, проверки соответствия типа сегмента и проверки прав использования содержимого сегмента или страницы. Различия в защите программ и данных проявляются при межсегментных передачах управления.
Рассмотрим работу механизма защиты программ на примере межсегментных передач управления без изменения уровня привилегий. Существуют две разновидности таких передач управления. Это – переходы на программы сегмента того же уровня привилегий и переходы на программы подчиненных сегментов.
Среди сервисных программ операционной системы имеется ряд программ, которые используют другие программы на каждом уровне привилегий. Обычно такие программы просты по конструкции, требуют обращения только к своему параметру и возвращают результат вызывающей программе. Для упрощения обращения к таким программам можно было бы разместить их на уровне пользовательских программ. Но их используют на всех уровнях. Следовательно, такие программы нужны либо дублировать для каждого уровня привилегий, либо использовать более сложные межсегментные переходы с увеличением уровня привилегий. Для таких ситуаций в процессоре Intel предусмотрено альтернативное чтение – использование подчиненных программных сегментов.
Программный сегмент определяется как подчиненный установкой бита C – conforming в байте прав доступа AR дескриптора программного сегмента. Обычные правила защиты по значениям CPL и DPL не действуют, если бит подчиненности С установлен в единицу (С=1). В этом случае используются другие правила.
С подчиненными программными сегментами, у которых С=1, не ассоциируется конкретный уровень привилегий, так как эти программы подчиняются уровню привилегий той программы, которая передает им управление. Например, если программа, у которой PL=3, передает управление подчиненному программному сегменту, то такая подчиненная программа будет работать с CPL=3, если же этот сегмент вызывает программа с PL=0, то подчиненная программа из этого сегмента будет выполняться, имея CPL=0. Когда управление передается подчиненному программному сегменту, то биты поля CPL регистра кодов CS не принимает значение поля DPL дескриптора нового программного сегмента, а сохраняют значение DPL последнего выполнявшегося неподчиненного программного сегмента. Таким образом, переход на подчиненные программные сегменты являются переходом без изменения текущего уровня привилегий PL.
Но
даже для подчиненных программных
сегментов имеются ограничения по их
использованию. Передавать управление
подчиненному сегменту может только та
программа, уровень привилегий которой
CPL
не выше уровня привилегий DPL
подчиненного программного сегмента,
т.е. проверяется условие CPL![]() DPL.
Чтобы программа подчиненного сегмента
была доступна на всех уровнях привилегий,
она должна иметь наивысший уровень
привилегий, т.е. DPL=0.
Такое условие соответствует общему
правилу использования сервисных
программ: любая программа может быть
сервисом только для программ более
низкого уровня иерархии.
DPL.
Чтобы программа подчиненного сегмента
была доступна на всех уровнях привилегий,
она должна иметь наивысший уровень
привилегий, т.е. DPL=0.
Такое условие соответствует общему
правилу использования сервисных
программ: любая программа может быть
сервисом только для программ более
низкого уровня иерархии.
При
переходе на программы сегментов того
же уровня привилегий механизм защиты
контролирует соблюдение равенства
уровней привилегий , вызывающей CPL
и вызываемой DPL
программ, а также, чтобы значение поля
RPL
в селекторе было меньше или равно
значению CPL,
т.е. в этом случае должно выполняться
условие (CPL![]() DPL)&(CPL
DPL)&(CPL![]() RPL).
RPL).
Рассмотренная модель взаимодействия программ проста по реализации, но имеет минимум защиты программ от возможных ошибок.
В процессоре Intel запрещена передача управления обычным средствам, программному сегменту, находящемуся на другом уровне привилегий. Ограничивая передачу управления в пределах одного кольца защиты, процессор тем самым предотвращает произвольное изменение уровней привилегий. Если бы значение CPL можно было легко изменять, все остальные средства защиты оказались бы бессмысленными.
Но передача управления на программы ОС необходима. Для решения этой проблемы в микропроцессоре предусмотрены особые системные объекты – шлюзы. Шлюзы являются ключевыми объектами для организации межсегментных переходов с увеличением уровня привилегий, т.е. на программы ОС. Любые переходы с увеличением уровня привилегий производятся только с использованием шлюза. Дескриптор шлюза вызова действует как посредник между программными сегментами, находящимися на различных уровнях привилегии.
Шлюзы идентифицируют разрешенные точки (метки) в программе, которым может быть передано управление. Таким образом, разрешенные точки входа в сервисные программы ОС задаются не вызывающей программой, а шлюзом. Использование шлюзов является защитой от несанкционированного использования программного сегмента. Шлюзы имеют свои уровни привилегий PL. При вызове шлюза проверяется его доступность по соотношению PL вызывающей программы и PL шлюза. Кроме того, проверяется соотношение уровней привилегий вызывающей и вызываемой программы.
Доступность
шлюза аналогично доступности данных.
Шлюз доступен, если его уровень привилегий
DPL
шл не
выше текущего уровня привилегий CPL
вызывающей программы и уровня привилегий
RPL
запроса. Таким образом, механизм защиты
проверяет условие: (CPL![]() DPLшл)&(RPL
DPLшл)&(RPL![]() DPLшл)
(2)
DPLшл)
(2)
В
результате получается следующий алгоритм
проверок при использовании шлюзов. На
первом этапе вызывающая программа
производит чтение дескриптора шлюза
вызова и проверяется условие его доступа
(2). Уровень привилегий шлюза DPLшл
выбирается
из дескриптора шлюза. Если условие (2)
выполняется, то на втором этапе
производится чтение дескриптора
программного сегмента из локальной LDT
или глобальной GDT
таблиц дескрипторов. Обращение к этим
таблицам производится с помощью
селектора, заданного в дескрипторе
шлюза вызова. После этого проверяется
условие доступности программного
сегмента. Межсегментная передача
управления допустима только на программы
своего или более высоких уровней
привилегий DPL.
Таким образом на втором этапе проверяется
условие (CPL![]() DPL)
(3). Если условие (3) выполняется , то
значение DPL
из дескриптора вызываемого программного
сегмента заносится в поле уровня
привилегий CPL
сегментного регистра CS.
После сохранения в стеке параметров
вызывающей программы, таких как точки
возврата, и проведения необходимых
проверок управление передается вызываемой
программе.
DPL)
(3). Если условие (3) выполняется , то
значение DPL
из дескриптора вызываемого программного
сегмента заносится в поле уровня
привилегий CPL
сегментного регистра CS.
После сохранения в стеке параметров
вызывающей программы, таких как точки
возврата, и проведения необходимых
проверок управление передается вызываемой
программе.
Принципы организации системы прерывания
В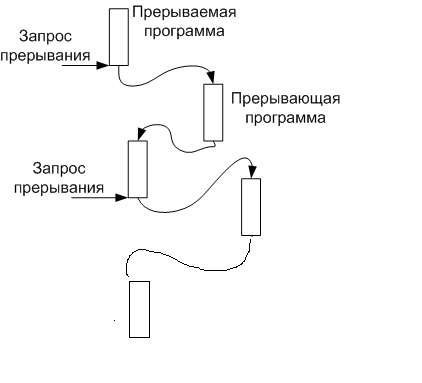 о
время выполнения ЭВМ текущей программы
внутри машины в связанной с ней внешней
среде могут возникать события , требующие
немедленной реакции на них со стороны
машины. Реакция состоит в том, что машина
прерывает выполнение текущей программы
и переходит к выполнению некоторой
другой программы, специально предназначенной
для данного события. По завершению
прерывающей программы ЭВМ возвращается
к выполнению прерванной программы к
той точке, где произошло прерывание.
о
время выполнения ЭВМ текущей программы
внутри машины в связанной с ней внешней
среде могут возникать события , требующие
немедленной реакции на них со стороны
машины. Реакция состоит в том, что машина
прерывает выполнение текущей программы
и переходит к выполнению некоторой
другой программы, специально предназначенной
для данного события. По завершению
прерывающей программы ЭВМ возвращается
к выполнению прерванной программы к
той точке, где произошло прерывание.
Каждое событие, требующее прерывания, сопровождается сигналом, который называется запросом прерывания.
Моменты возникновения запросов прерывания заранее неизвестны и поэтому не могут быть учтены при программировании. Запросы на прерывание могут возникать как в самой машине, так и в ее внешней среде.
Внутренние запросы – сбой в работе аппаратуры, переполнение разрядной сетки, деление на 0, нарушение защиты памяти, различные ситуации при выполнении операции ввода/вывода.
Запросы из внешней среды – от других ЭВМ и от различных датчиков, которые подключены к машине. Возможность прерывания программы важное архитектурное свойство ЭВМ, позволяющее эффективно использовать производительность процессора при наличии несколько одновременно протекающих во времени процессов, требующих управление и обслуживание со стороны процессора.
Для реализации прерывания программ в состав ЭВМ вводят специальные аппаратные и программные средства. Совокупность аппаратных и программных средств, необходимых для реализации прерываний, называется системой прерывания программ.
Основными функциями системы прерывания программ являются:
1.Запоминание состояния прерываемой программы и осуществление перехода к прерывающей программе.
2.Восстановление состояния прерванной программы и возврат к ней.
Основной характеристикой систем прерываний является глубина прерываний. Глубина прерываний - это максимальное число программ, которые могут прерывать друг друга. Если при выполнении прерывающей программы другие запросы на прерывание не обслуживаются, то система имеет единичную глубину. Глубина прерывания равна n, если допускаются последовательные прерывания до n программ.
Поскольку прерывающая программа может быть в свою очередь прерванной только в случае поступления запроса с более высоким приоритетом, то глубина прерывания обычно совпадает с числом уровней приоритета в системе прерывания. В ЭВМ число различных запросов прерывания может достигать нескольких десятков и сотен. В таких случаях запросы разделяют на несколько классов или уровней.
З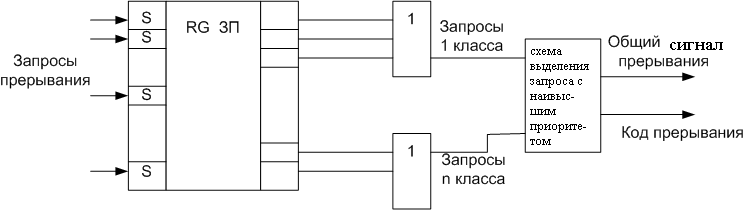 апросы
одного уровня имеют одинаковый приоритет.
Обычно запросы от всех источников
прерывания поступают на специальный
регистр запросов прерыванияRG
ЗП. Поступивший
запрос устанавливает соответствующий
разряд регистра в единичное состояние.
Наличие 1 в данном разряде указывает на
наличие запроса на прерывание от
определенного источника, поскольку
каждому запросу соответствует свой
разряд регистра.
апросы
одного уровня имеют одинаковый приоритет.
Обычно запросы от всех источников
прерывания поступают на специальный
регистр запросов прерыванияRG
ЗП. Поступивший
запрос устанавливает соответствующий
разряд регистра в единичное состояние.
Наличие 1 в данном разряде указывает на
наличие запроса на прерывание от
определенного источника, поскольку
каждому запросу соответствует свой
разряд регистра.
Запросы одного уровня (класса) объединяются с помощью дизъюнкторов. Далее стоит схема, которая выделяет запросы с наивысшим приоритетом. Информация о действительной причине прерывания содержится в коде прерывания. После принятия запроса прерывания на обслуживание и передачи управления прерывающей программе, соответствующий разряд RG ЗП сбрасывается в ноль.
Очень часто встречается ситуация, когда приоритет за каждым классом прерывания не может быть закреплен жестко и может меняться в процессе решения задачи. В этом случае применяется программное управление приоритетом на основе маски прерывания.
Маска прерывания представляет собой двоичный код, разряды которого поставлены в соответствие запросам или классам прерывания. Маска загружается в специальный регистр маски RGM. Единичное состояние в данном разряде маски разрешает, а нулевое – запрещает (маскирует) прерывание текущей программы по соответствующему запросу, то есть каждая прерывающая программа может устанавливать свою маску и устанавливать произвольные приоритетные соотношения между запросами прерываний.
При формировании маски единицы устанавливаются в разряды соответствующие запросам с более высоким приоритетом, чем у данной программы, а в остальные разряды записываются нули, запрещая тем самым выполнение программ с меньшим приоритетом.
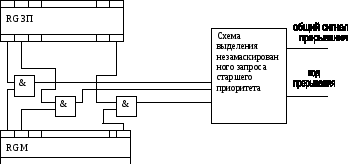
Конъюнкторы выделяют не замаскированные запросы прерывания, из которых специальная схема выделяет наиболее приоритетный запрос и формирует его код. С замаскированными запросами в зависимости от причин прерываний поступают двумя образами: либо они игнорируются, либо запоминается с тем, чтобы осуществить прерывание, когда запрет на прерывание будет снят.
В ЭВМ часто используются так называемые векторные прерывания. Прерывание называется векторным, если источник прерывания посылают в процессор адрес ячейки памяти, в которой находится его вектор прерывания. Он обычно состоит из нескольких слов и содержит следующую информацию:
1. начальный адрес прерывающей программы(начальный адрес программы обработки прерывания от данного источника)
2.слово состояния процессора(ССП)
Начальный адрес
прерывающей программы
ССП

Получив адрес вектора прерывания процессор читает из ОЗУ сам вектор и передает управление прерывающей программы, чей адрес находится в первом слове этого вектора прерывания. Таким образом при векторном прерывании каждый источник прерывания, например ПУ, имеет свою прерывающую программу, переход к которой происходит по адресу, содержащемуся в векторе.
Система прерывания PDP-11.
В PDP-11 возможно два вида прерываний от внешних устройств.
1.Внепроцессорное прерывание, при котором ПУ осуществляет обмен данными непосредственно с ОЗУ или другими ПУ, минуя процессор. Это внепроцессорная передача данных. Такой режим работы называется прямой доступ в память (ПДП).
2.Программное прерывание, при котором управление передается специальной программе обработки прерывания. Это программная передача данных под управлением процессора.
Всего в PDP-11 имеется 4 уровня программных прерываний и 1 уровень внепроцессорных прерываний.
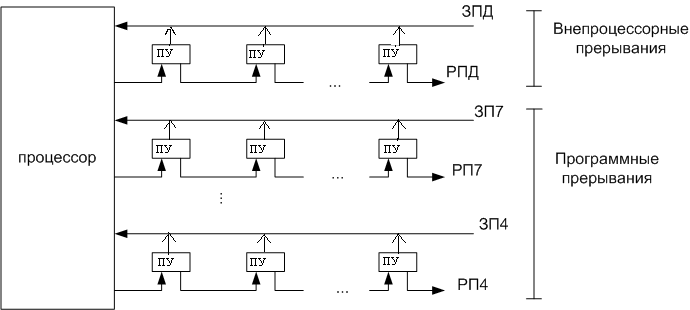
Устройства, поставляющие запросы на линию ЗПД, имеют наивысший абсолютный приоритет. В этом случае управление передачей данных происходит под управлением того ПУ, которое выставило сигнал ЗПД (запрос прямого доступа). В этом случае обмен данными идет без участия процессора.
Устройства, которые получают управление интерфейсом по одной из линий запросов передачи ЗП, могут использовать возможности процессора для обработки запросов прерывания.
При получении запроса на одной из линий ЗП4 – ЗП7 процессор сравнивает приоритет, то есть номер линии со своим приоритетом. Если приоритет линии выше, то процессор выдает соответствующий сигнал по РП. При равенстве приоритетов линии ЗП и процессора прерывание не происходит. Поэтому, если приоритет процессора равен 7, то ни одно из ПУ не может прервать текущую программу процессора.
Линии РПД и РП проходят последовательно через все устройства, находящиеся на их уровне.
Если несколько устройств одного уровня выставили запрос, то удовлетворяется запрос того ПУ, которое первым подключено к соответствующей линии РП.
Рассмотрим процедуру обслуживания прерывания для ПУ , пославшего запрос по одной из линий ЗП 4 – ЗП 7.
1.Если приоритеты позволяют, то процессор предоставляет интерфейс запрашивающему ПУ.
2.Получив управление интерфейсом (сигнал РП), устройство посылает в процессор сигнал прерывания и адрес ячейки памяти, которая содержит вектор прерывания. Каждая ПУ имеет свой вектор прерывания. В векторе прерывания – 2 слова. Первое слово содержит начальный адрес программы обслуживания прерывания от данного устройства. Второе слово – содержит слово состояние процессора – ССП. После получения адреса вектора прерывания начинается процедура обслуживания прерывания.
3.Процессор вводит текущее значение ССП, а затем текущее значение счетчика команд ( СК ) – в стек.
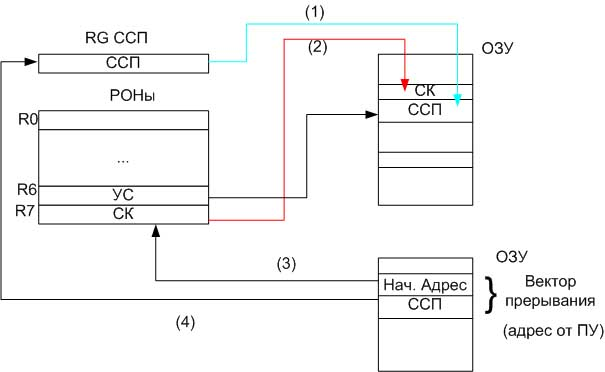
В качестве аппаратного указателя стека (УС) используется РОН R6. Таким образом, происходит сохранение параметров прерываемой программы (сохраняется ССП и адрес точки возврата в прерванную программу).
4.Новое значение СК и ССП выбираются из ОЗУ по адресу, указанному запрашивающим ПУ. После этого запускается программа обслуживания устройства.
5.По окончании работы программы обслуживания устройства происходит возврат к прерванной программе, для чего два верхних слова из стека загружаются обратно в СК и RG ССП. Возобновляется выполнение прерванной программы с точки, где произошло прерывание.
Программируемый контроллер прерываний фирмы Intel .
Программируемый контроллер прерываний обеспечивает управление восьми уровневыми векторными приоритетными прерываниями, то есть один контроллер прерываний обеспечивает приемную обработку до восьми сигналов прерывания.
Структурная схема контроллера прерываний имеет следующий вид. (Рис.1.)
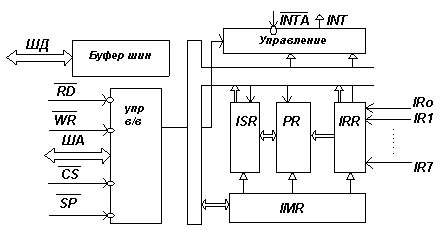 Рис.1.
Рис.1.

![]() -запрос
прерывания
-запрос
прерывания
Запросы прерывания обрабатываются тремя взаимосвязанными регистрами. Регистр запросов (IRR) фиксирует все запросы прерываний, а регистр обслуживания (ISR) хранит только те прерывания, которые приняты на обслуживание .
Регистр масок-IMR идентифицирует маскируемые коды прерывания.
Шифратор приоритетов (арбитр приоритетов)-PR анализирует содержимое этих трех регистров и определяет нужно или нет генерировать сигнал запроса прерывания INT.
Контроллер прерываний может работать в одном из двух режимов:
1)контроллер является ведущим.
2)контроллер является ведомым.
Если на вход контроллера поступает сигнал SP с отриц.=1, то в этом случае контроллер является ведущим, в противном случае ведомым. Когда контроллер ведомый, то микропроцессор загружает в его регистры специальную управляющую информацию. Когда контроллер ведущий, то он управляет процессом передачи данных.
Рассмотрим алгоритм работы контроллера:
1)ПУ
посылает по одной из линий
![]() единичный сигнал.
единичный сигнал.
2)в регистре IRR происходит установка соответствующих разрядов в единицу под действием сигналов, поступающих от ПУ.
3)незамаскированные запросы, то есть те, для которых соответствующие разряды регистров IMG содержат 1, передаются в арбитр PR ,замаскированные запросы при этом блокируются.
4)арбитр PR выделяет наиболее приоритетный запрос и передает его в регистр обслуживания ISR.
5)приоритет запроса сравнивается с текущим приоритетом программы, выполняемой в микропроцессоре. Если приоритет запроса выше приоритета программы, то контроллер формирует сигнал прерывания INT, в противном случае обработка запроса откладывается.
6)Микропроцессор
принимает микро запросы прерываний INT
и начинает реализовывать последовательности
прерываний, выполняя с цикла подтверждения
прерывания, с формированием сигнала
![]() в каждом из этих циклов.
в каждом из этих циклов.
7)В первом цикле подтверждение с прерывания происходит установка соответствующего разряда ISR и сброса аналогичного сигнала в регистре IRR.
8)Во втором цикле подтверждение прерывания текущее содержимое адреса прерывания передается в микропроцессор по шине данных.
9)Микропроцессор принимает этот адрес и использует его для обращения к таблице векторов прерывания, где хранятся сами вектора прерывания.
10)Текущее значение вектора прерывания , прерванное программой, запоминается в стеке, а вместо него в микропроцессор загружается вектор прерывания , выбранный из таблицы векторов прерывания. Управление передается прерывающей программе по адресу, содержащемуся в первом слове вектора прерывания.
11)По завершению прерывающей программы происходит восстановление сохраненного в стеке вектора прерывания прерванной программы, после этого управление возвращается к прерванной программе с той точки, где произошло прерывание.
Контроллер может быть запрограммирован на один из следующих режимов работы:
1)вложенные прерывания.
Каждому
из восьми входов запросов прерывания
![]() назначается
фиксированный приоритет , при этом
наивысший приоритет будет у запроса
назначается
фиксированный приоритет , при этом
наивысший приоритет будет у запроса![]() и
далее в порядке убывания приоритетов
до
и
далее в порядке убывания приоритетов
до![]() .Запрос
с большим приоритетом прерывает
обслуживание того ПУ , у которого меньший
приоритет.
.Запрос
с большим приоритетом прерывает
обслуживание того ПУ , у которого меньший
приоритет.
2)круговой (циклический) приоритет
В
этом режиме также каждому входу
![]() назначается приоритет, однако, после
запроса и обслуживания прерывания
приоритеты изменяются в круговом порядке
таким образом, что последний обслуженный
вход будет иметь самый маленький
приоритет.
назначается приоритет, однако, после
запроса и обслуживания прерывания
приоритеты изменяются в круговом порядке
таким образом, что последний обслуженный
вход будет иметь самый маленький
приоритет.
Организация прямого доступа к памяти.
Одним из способов обмена данными с ПУ является обмен в режиме прямого доступа к памяти (ПДП). В этом режиме обмен данными между ПУ и основной памятью микроЭВМ происходит без участия процессора. Обменом в режиме ПДП управляет не программа, выполняемая процессором, а электронные схемы, внешние по отношению к процессору. Обычно эти схемы размещаются в специальном контроллере, который называется контроллером прямого доступа к памяти.
Режим ПДП обычно используется при начальной загрузке программ в основную память микроЭВМ из устройств ввода и для организации обмена данными с быстродействующими внешними запоминающими устройствами (дисковыми накопителями).
Контроллер ПДП подключается к основной памяти посредством системного интерфейса. При этом возникает проблема совместного использования шин системного интерфейса процессором и контроллером ПДП. Существует два основных способа решения этой проблемы:
1. Реализация обмена в режиме ПДП с захватом цикла.
2. Реализация обмена в режиме ПДП с блокировкой процессора.
Наиболее простой способ организации ПДП с захватом цикла состоит в использовании контроллером ПДП тех машинных циклов процессора, когда процессор не обменивается данными с памятью. В такие циклы контроллер ПДП может обмениваться данными с памятью, не мешая работе процессора и не снижая его производительности. Однако при использовании такого способа организации ПДП обмен возможен только в случайные моменты времени и одиночными байтами, что не всегда является удобно.
Поэтому на практике чаще используется режим ПДП с захватом цикла и принудительным отключением процессора от шин системного интерфейса. Для реализации такого режима системные интерфейс дополняется двумя линиями для передачи управляющих сигналов: «Запрос прямого доступа к памяти» (ЗПДП) и «Подтверждение прямого доступа к памяти» (ППДП).
Управляющий сигнал ЗПДП формируется контроллером ПДП. Процессор, получив этот сигнал, приостанавливает выполнение очередной команды, не дожидаясь ее завершения, выдает в системный интерфейс управляющий сигнал ППДП и отключается от шин системного интерфейса. С этого момента управление шинами системного интерфейса передается контроллеру ПДП. Контроллер по шинам системного интерфейса осуществляет обмен одним байтом или словом данных с памятью микроЭВМ, а затем, сняв сигнал ЗПДП, возвращает управление системным интерфейсом процессору.
Как только контроллер ПДП будет готов к обмену следующим байтом, он вновь захватывает цикл процессора. Эта процедура будет продолжаться до тех пор, пока не будут переданы все данные. В промежутках между сигналами ЗПДП процессор продолжает выполнять команды программы. Тем самым выполнение программы процессора замедляется, но в меньшей степени, чем при обмене в режиме прерывания.
Прямой доступ в память с блокировкой процессора отличается от ПДП с захватом цикла тем, что управление системным интерфейсом передается контроллеру ПДП на все время обмена блоком данных. Такой режим ПДП необходим в тех случаях, когда процессор не успевает выполнить хотя бы одну команду между очередными операциями обмена в режиме ПДП, и поэтому режим захвата цикла не имеет смысла. Такая ситуация возникает тогда, когда время обмена одним байтом между ПУ и памятью сопоставима с циклом процессора из-за малой производительности последнего.
Для организации обмена данными между памятью и ПУ контроллер должен иметь в своем составе регистр адреса для обращения к памяти и счетчик байт для подсчета числа переданных байт. Перед началом обмена процессор должен загрузить в регистр начальный адрес выделенной ПУ области памяти, а в счетчик байт – размер этой области. Таким образом, контроллер подготавливается к выполнению операции ввода данных в режиме ПДП. Далее в процессе передачи данных содержимое регистра адреса и счетчика байт изменяется. После передачи очередного байта в память содержимое регистра адреса увеличивается на единицу, а из содержимого счетчика байт вычитается единица. Как только содержимое счетчика станет равно нулю, контроллер прекратит передачу данных от ПУ в память, поскольку нужное количество байт уже передано и выделенная область памяти заполнена.
К одному контроллеру ПДП можно подключать несколько ПУ , которые получают право обмена данными с памятью в соответствии с их приоритетами.
Контроллеры ПДП обычно реализуются в виде одной микросхемы, к которой подключаются несколько ПУ.
Программируемый контроллер прямого доступа к памяти.
Такой контроллер служит для управления обменом данными между четырьмя ПУ и памятью. Управление работой каждого из 4 каналов ПДП осуществляется с помощью двух 16-разрядных регистров: регистра начального адреса и регистра управления. В регистр начального адреса при программировании БИС заносится начальный адрес передаваемого массива данных . В 14-и младших разрядов регистра управления размещается счетчик байт, в который заносится число на единицу меньше длины передаваемого массива данных. Два оставшихся разрядов (15 и 14) регистра управления определяют тип операции обмена: 00 – контроль, 01 – запись в память, 10 – чтение из памяти, 11 – запрещенное состояние.
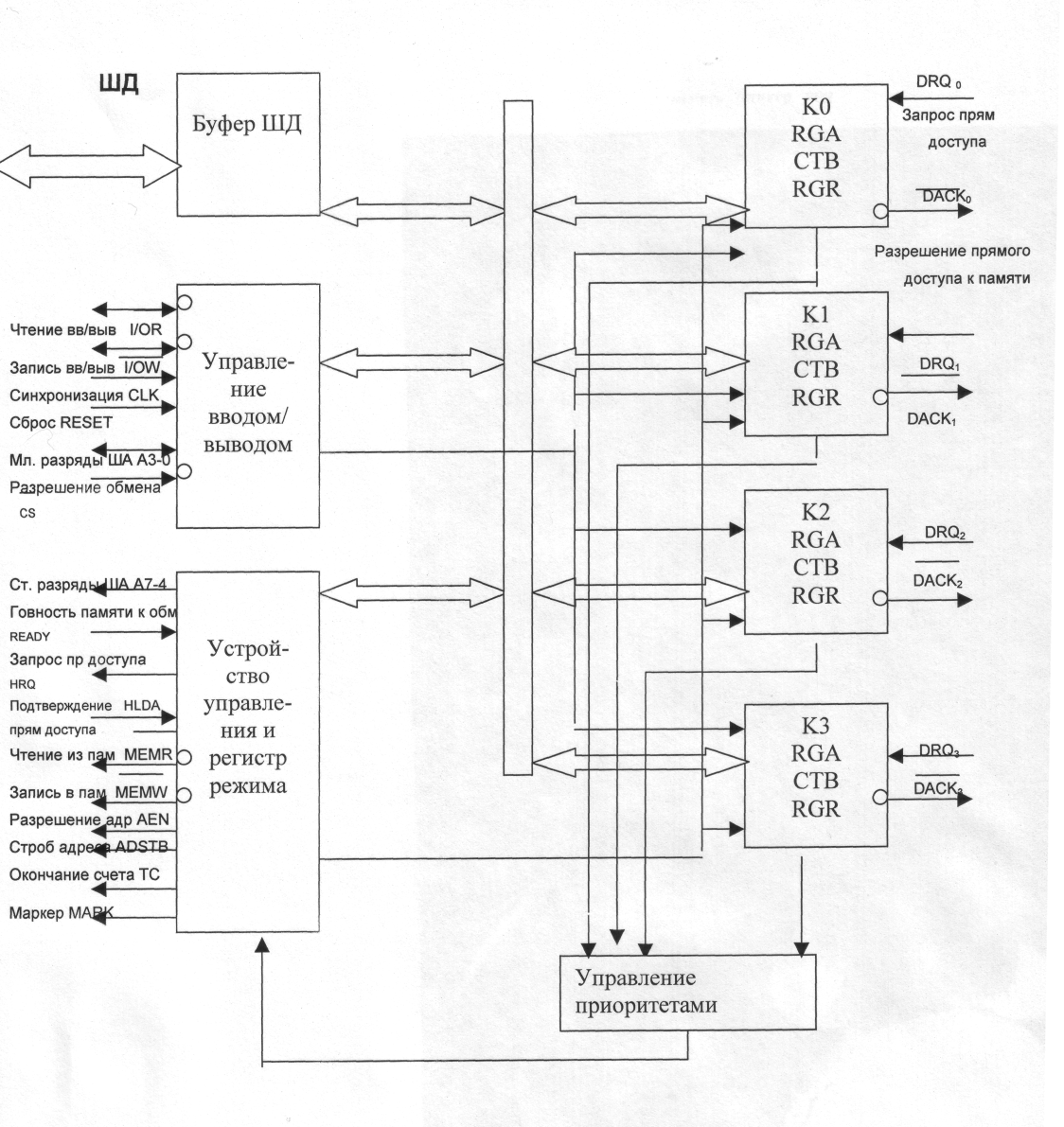
Связь контроллера с системным интерфейсом микроЭВМ осуществляется по шине данных ШД. Запись информации в регистр начального адреса и в регистр управления производится программным путем перед началом передачи данных.
По четырем входным линиям DRQ запросов от ПУ внешние устройства сигнализируют контроллеру об их готовности к передаче данных. Программно запросам DRQ могут быть назначены либо фиксированные приоритеты (при этом DRQ0 - высший, а DRQ3 - низший), либо циклические приоритеты.
В![]() ответ на получение запросаDRQ
контроллер
сигналом
ответ на получение запросаDRQ
контроллер
сигналом
извещает ПУ о начале запрошенного им цикла ПДП.
Когда контроллер получает управление системной шиной он выводит на ШД 8 старших бит адреса памяти из старшей половины регистра начального адреса работающего канала ПДП. По сигналу «Строб адреса» ADSTB эти 8 бит загружаются во внешний регистр старших разрядов адреса, выходы которого подключены к линиям А15 - А8 шины адреса системного интерфейса. Младшие разряды адреса формируются на линиях А7 – А0 .
Контроллер может быть либо ведомым, либо ведущим. Ведомым контроллер является при его программировании или при считывании содержимого его внутренних регистров. При этом контроллер управляется МП. Когда же контроллер получает управление системным интерфейсом он становится ведущим и управляет процессом передачи данных без участия микропроцессора.
Е![]() сли
контроллер ведомый, то он по сигналу
сли
контроллер ведомый, то он по сигналу
п![]() ринимает
с ШД байт и загружает его в адресуемый
по линиям А3
– А0
внутренний
регистр. По сигналу
ринимает
с ШД байт и загружает его в адресуемый
по линиям А3
– А0
внутренний
регистр. По сигналу
содержимое адресуемого регистра передается на ШД (чтение из контроллера).
К![]() огда
контроллер является ведущим, то он
формирует пару сигналов
огда
контроллер является ведущим, то он
формирует пару сигналов
п![]() ри
передаче данных в основную память, и
ри
передаче данных в основную память, и
при передаче данных из памяти в ПУ.
Сигнал «Запрос ПДП» HRQ подается на вход HOLD микропроцессора и сигнализирует о необходимости его отключения от системной шины.
Сигнал «Подтверждение ПДП» HLDA формируется МП и извещает контроллер о том, что он может управлять системной шиной.
Сигнал «Разрешение адреса» AEN служит для управления работой шинных формирователей, связывающих МП, и другие устройства с системной шиной.
Сигнал «Окончание счета» ТС форсируется при достижении нуля в 14-битном счетчике работающего канала. Это сигнал извещает об окончании передачи заданного блока данных.