

книги / Практикум по программированию на языке Си
..pdfВ файле hash будут храниться позиции размещения в файле articles начал цепочек словарных статей. Известно, что для позиционирования в файлах используются значения типа long. С их помощью указываются смещения позиции (чтения или записи) относительно начала отсчета. "Разобьем" весь файл hash на (HASH_LEN+1) участков фиксированных размеров. На этапе проектирования и отладки программы используем участки небольших размеров и очень небольшое значение HASH_LEN.
Пусть каждый участок занимает 5 байт. При инициализации файла (рис. 12.2) в первый участок нужно занести значение HASH_LEN, остальные участки заполнить значениями –1L. При дальнейших манипуляциях с файлом hash он не растет (его длина не изменяется), но в его "участки" заносятся новые отличные от –1L значения. Поэтому режим открытия для файла должен быть "r+". В первый участок (с нулевым смещением от начала файла) запишем значение HASH_LEN. Теперь, обратившись к файлу, можно сразу же узнать его объем, т.е. диапазон возможных значений, которые должна формировать хэш-функция.
Рис. 12.2. Файл hash после создания и инициализации
Файл articles при добавлении словарных статей постоянно растет, и, кроме того, в уже сохраняемые в файле статьи необходимо вносить изменения при добавлении нового элемента (новой словарной статьи) в хэш-цепочку. Такая обработка требует, чтобы файл был открыт в режиме "a+". При создании файла его инициализация не требуется. Записи словарных статей в файле articles будут вестись последовательно, начиная с начала файла. Если файл уже содержит информацию, то следующая словарная статья размещается в конце файла.
551

Алгоритм подготовки файлов:
Открыть для модификаций и дополнения файл articles ("a+") Если неудача
Прекратить выполнение Все-если
Открыть для чтения и модификаций файл hash ("r+") Если файла нет
Открыть файл hash для записи ("w") Инициализировать файл hash Закрыть файл hash
Открыть файл hash в режиме "r+' Все-если
Прочитать из hash значение hashlen
Если hashlen!=HASH_LEN
Прекратить выполнение Все-если
Прежде чем приводить текст функции, реализующей предложенный алгоритм, введем соглашения об обменах информацией между функциями нашего словаря. Для обмена используем объекты внешней памяти. (Этот факт иногда считается нарушением принципов структурного программирования. "Пуританский" подход к проектированию функций требует, чтобы все обмены происходили через параметры.) Используем следующие объекты. Препроцессорная константа HASH_LEN задает количество различных хэш-значений. Именно эта константа определяет количество "записей" в файле hash (плюс одна). Препроцессорная константа FORMAT задает форматную строку, определяющую размеры отдельных записей в файле hash. Указатели FILE *hashFile и FILE *artiFile обеспечивают доступ к файлам после их открытия. Именно с помощью этих указателей всем функциям программы будут доступны файлы hash
и articles.
Для чтения из входного потока исходных данных (терминов и переводов) в функциях будем использовать символьные массивы, размеры которых определяются с помощью препроцессорной константы LINE_MAX. Перечисленные объекты введем, поместив их определения во вспомогательный текстовый заголовочный файл такого вида:
552
/* dicTune.c – заголовочный файл словаря */ #ifndef DIC_TUNE
#define DIC_TUNE #define LINE_MAX 200 #define HASH_LEN 26 #define FORMAT "%5ld" FILE * hashFile;
FILE * artiFile; #endif
С учетом принятых решений алгоритм подготовки файлов реализует следующая функция:
/* fileTune.c – функция настройки файлов словаря */ #include <stdio.h>
#include "dicTune.c" void fileTune(void)
{
int i;
long hashLen;
artiFile = fopen("articles", "a+"); if (artiFile == NULL)
/* Файл не открылся в режиме "a+"*/ { printf
("\nThe error of file \"articles\" opening!"); exit(0);
}
/*Подготовка файла для хэш-значений */ hashFile = fopen("hash", "r+");
if (hashFile == NULL)
/* Файл отсутствует, создать новый: */
{hashFile = fopen("hash", "w"); if (hashFile == NULL)
/* Файл не открылся в режиме "w"*/ { printf
("\nThe error of file \"hash\" creating!"); exit(0);
}
fprintf(hashFile, FORMAT, HASH_LEN); for (i=0; i < HASH_LEN; i++)
fprintf(hashFile, FORMAT, -1L); fclose(hashFile);
553
hashFile = fopen("hash", "r+");
if |
(hashFile == NULL) |
|
/* Файл не |
открылся в режиме "r+"*/ |
|
{ |
printf |
error of file \"hash\" opening!"); |
|
("\nThe |
|
} |
exit(0); |
|
|
|
|
} |
/* старый файл открылся в режиме "r+" */ |
|
else |
||
{fscanf(hashFile, FORMAT, &hashLen); if (hashLen != HASH_LEN)
{ printf
("\nThe new length of file \"hash\"!"); exit(0);
}
}
return;
}
Прежде чем разрабатывать основной алгоритм словаря, вернемся к примеру взаимосвязей его данных 12.1 и выберем схему их размещения в файлах. Мы уже решили, как хранить адреса хэш-цепочек в файле hash. Выберем способ хранения словарных статей в файле articles. Наиболее наглядно это проектирование структуры данных можно сделать графически (рис. 12.3). Построим схему для ситуации, когда в файлах находятся только четыре словарные статьи и вводились они в том порядке, как они указаны в предыдущем списке
(all, run, sky, room).
Для простоты функция хэширования объединяет в хэш-цепочку все слова, начинающиеся на одну букву (см. рис. 12.1, 12.3). Будем помещать и считывать информацию в файл articles по строкам. В файле articles данные (строки) каждой словарной статьи размещаются подряд. Вначале английский термин, затем его переводы и завершает статью "адрес продолжения хэш-цепочки" (позиция начала) следующей словарной статьи данной хэш-цепочки. Если хэшцепочка закончилась, адрес продолжения устанавливается равным нулю (0L). В примере на рисунке статьи "all" и "sky" не имеют "продолжений", статья "run" включена в хэш-цепочку, где следующей является статья "room".
554
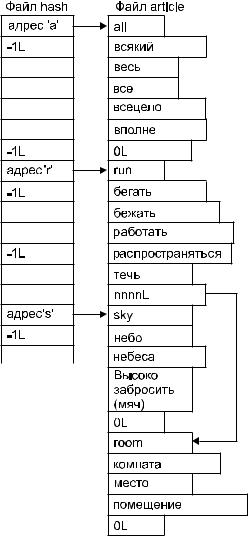
Рис. 12.3. Размещение словарных статей в файлах
Вначале файл articles создается пустым и заполняется постепенно по мере ввода словарных статей. В общем виде алгоритм работы словаря можно представить таким образом:
555

Подготовить файлы словаря Цикл ввода английских терминов
Ввести английский термин Получить хэш-значение для термина Проверить запись в хэш-файле Если нет начала хэш-цепочки
Поместить словарную статью в новую хэш-цепочку Перейти к следующей итерации цикла
Все-если Поиск термина в хэш-цепочке
Если термин найден Вывести переводы
Иначе Добавить в цепочку новую словарную статью
Все-если Конец-цикла
Представленному псевдокоду соответствует следующая программа, ряд функций которой будут рассмотрены позже:
/* 12_09.c - англо-русский словарь */ #include <stdlib.h>
#include <stdio.h> #include <string.h> #include "dicTune.c" #include "fileTune.c" #include "hashFun.c" #include "newHash.c" #include "newArt.c" #include "search.c" #include "display.c" int main ()
{
char engTerm[LINE_MAX];
long hashValue, address, position; /* Подготовить файлы словаря */
fileTune();
/* Цикл ввода английских терминов */ for (;;)
{printf("\nPrint english term or ENTER:\n"); gets(engTerm);
556
if (strlen(engTerm) == 0)
{ puts("The end of running!"); return 0;
}
/* Получить по термину адрес (позицию) в "hash" */ hashValue=hashFun(engTerm);
/* получить из "hash" адрес в "article" цепочки для термина */
fseek(hashFile, hashValue, SEEK_SET); fscanf(hashFile, "%ld", &address);
if (address == -1L) /* Цепочка отсутствует */ { newHash(engTerm, hashValue);
continue;
}
/* Поиск термина в хэш-цепочке */ position = search(engTerm, address); if (position >= 0) /* Термин есть */
/* Вывести переводы */ display(position);
else
{ position = -position;
/* Добавить в цепочку новую статью */ newArt(engTerm, position);
}
}
return 0;
}
Результаты диалога с программой:
Print english term or ENTER: must<ENTER>
Print the translations or ENTER:
быть обязанным<ENTER> <ENTER>
Print english term or ENTER: must<ENTER>
быть обязанным
Print english term or ENTER: <ENTER>
The end of running!
557
Еще раз остановимся на роли в нашей программе препроцессорных констант. Они определены в заголовочном файле dicTune.c. После включения директивой #include этого файла они доступны как в функции main(), так и во всех текстах, включаемых в программу после их определения. LINE_MAX используется для указания длины символьных массивов, в которые помещаются при вводе термины и их переводы. Константы HASH_LEN и FORMAT используются для реализации механизма хэширования. HASH_LEN определяет количество хэш-значений, т.е. число возможных хэш-цепочек, в которые будут объединяться словарные статьи. В данном учебном варианте программы идентификатор HASH_LEN представляет значение 26 (число букв в латинском алфавите). Для препроцессорного идентификатора FORMAT выбрана строка замещения "%5ld". Тем самым адреса (позиции), сохраняемые в файлах hash и articles, не должны превышать значения 99999.
О глобальных указателях hashFile и artiFile, также определенных в файле dicTune.c, мы уже говорили – они "настраиваются" функцией fileTune() на файлы hash и articles и используются почти во всех функциях программы.
В текст программы на препроцессорном уровне включаются тексты функций. Одну из них fileTune() мы уже рассмотрели. Остановимся на остальных.
long hashFun(char * term); – функция формирует значение адреса (позиции) в файле hash, используя код первой буквы английского термина (параметра).
void newHash(char * engTerm, long hashValue); –
функция должна прочитать из входного потока (с клавиатуры) переводные эквиваленты английского термина (engTerm), записать словарную статью в файл articles и занести по адресу hashValue в hashфайл позицию (адрес) словарной статьи в файле articles. Эта словарная статья начнет новую хэш-цепочку.
long search(char * engTerm, long address); – функ-
ция, получив позицию (address) начала хэш-цепочки, просматривает в ней все словарные статьи, разыскивая в них английский термин (engTerm). Если термин найден, функция возвращает позицию начала соответствующей словарной статьи. Если термин в цепочке статей отсутствует, функция возвращает позицию нулевого адреса продолжения из последней словарной статьи в этой хэш-цепочке. Чтобы
558
различить две описанные ситуации и не вводить дополнительных параметров, примем следующее решение. Если термин найден, функция search() будет возвращать его адрес (позицию в файле) как неотрицательное значение типа long. Если термин отсутствует, функция будет возвращать значение позиции адреса продолжения 0L из последней статьи в хэш-цепочке, взятое со знаком минус.
void display(long position); – функция в качестве параметра получает позицию начала словарной статьи в файле articles, читает переводы и выводит их на экран. Окончание чтения – строка, содержащая символы цифр, представляющих число типа long (признак окончания словарной статьи).
void NewArt(char * engTerm, long position); – функ-
ция должна прочитать из входного потока (с клавиатуры) переводные эквиваленты английского термина (адресованного параметром engTerm), записать словарную статью в файл articles и занести позицию начала этой статьи в адрес продолжения предыдущей словарной статьи той же хэш-цепочки, используя значение позиции ад-
реса (position).
Кроме перечисленных функций, непосредственно вызываемых из функции main(), в процессе разработки "появилась" функция "более низкого в иерархии уровня" с прототипом:
void readWrite(char * engTerm, long position);
Ее назначение – формировать в файле articles словарную статью. В качестве параметров функция получает английский термин (engTerm) и позицию (параметр position) в файле articles, начиная с которой нужно разместить словарную статью. Функция записывает в файл articles английский термин, затем в цикле читает из стандартного потока переводные эквиваленты и записывает их в файл articles. В конец словарной статьи записывается строка, содержащая "изображение" числа 0L – признак конца хэш-цепочки (нулевой адрес продолжения хэш-цепочки).
Прежде чем приводить тексты функций, еще раз обратим внимание на взаимоотношения компонентов нашей программы. Изобразим на схеме (рис 12.4) файлы, функции и внешние по отношению к функциям данные. На рисунке не показаны стандартные потоки вво- да-вывода. Кроме того, не отображены обмены между функциями и файлами.
559
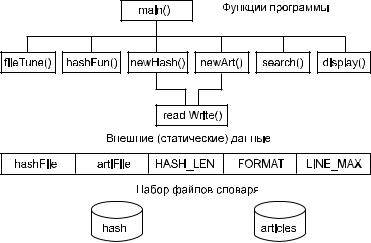
Рис. 12.4. Компоненты автоматического словаря
Чтобы проследить за передачами данных, обратимся к текстам функций.
/* hashFun.c – функция вычисления позиции термина в файле "hash" */
long hashFun(char * term)
{
if (term[0]<'a' || term[0]>'z')
{puts("Error of input!"); exit(0);
}
return 5*((long)term[0]-(long)'a'+1L);
}
Как уже упоминалось, мы использовали простейшие решения для реализации словаря. Принято, что адреса, сохраняемые в файле hash, занимают по 5 байт каждый и хранятся в символьном виде. Диапазон хэш-значений выбран от 1 до 26, и каждому хэш-значению hashValue соответствует позиция 5*hashValue в хэш-файле. Напомним, что в начале файла hash (начиная с нулевой позиции) размещается значение HASH_LEN. Хэширование должно выполняться только для английских терминов. В теле функции hashFun() вы-
560