

книги / Практикум по программированию на языке Си
..pdfexit(1);
}
strcpy(pstr,strAr); return pstr;
}
Чтение строки из входного потока выполняет библиотечная функция gets() в достаточно большой символьный массив strAr[S_AR], локализованный в теле функции getLine(). Размер массива определяется препроцессорной константой S_AR. При достижении признака EOF функция gets() возвращает значение NULL. В этом случае функция getLine() также вернет нулевое значение адреса (NULL). Переменной len присваивается значение длины прочитанной строки. Если длина оказывается больше предельно допустимой (len>S_AR-1), выдается сообщение и прекращается выполнение программы. В противном случае выделяется участок памяти размером (len+1) байт и в него библиотечной функцией strcpy() копируется строка из массива strAr[]. Значение указателя pstr на динамически выделенный участок памяти возвращается как результат выполнения функции getLine().
Имея функцию, формирующую динамический массив с очередной строкой входного потока, можно так написать функцию для создания в динамической памяти звена списка:
/* cellCreate.c – функция создания звена списка */ struct cell * cellCreate(void)
{
struct cell * point; char * pstr;
char * getLine(void); /* прототип */ pstr = getLine();
if (pstr == NULL) return NULL;
/* Выделить память для очередного звена списка: */ point=(struct cell *)malloc(sizeof(struct cell)); if (point == NULL)
{ puts("\nERROR! No memory!"); exit(1);
}
point -> next = NULL;
point -> len = strlen(pstr);
491
point -> pLine = pstr; return point;
}
Для трансляции и исполнения этой функции необходимо, чтобы перед нею было размещено определение структурного типа struct cell. В теле функции cellCreate() определены два указателя. Указателю pstr присваивается адрес строки, прочитанной из входного потока и размещенной в динамическом массиве, созданном функцией getLine(). Указателю point присваивается адрес динамически выделяемого участка памяти для размещения структуры (звена списка). После проверки результата выделения памяти компонентам структуры присваиваются значения, и ее адрес используется в операторе return.
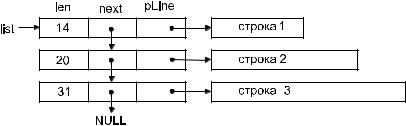
Проектировать функцию для включения в список нового звена удобнее всего, имея перед собой графическое представление списка. На рис 11.1 изображен список с тремя звеньями. Алгоритмы вставки звена в список могут быть разными, но для односвязного списка выбор невелик. Длину строки из подключаемого звена нужно сравнивать с длинами строк из звеньев списка, последовательно перебирая их от начала списка. Как только встретится строка с длиной большей, чем у подключаемой, перед ней в список нужно включить новое звено. Возможны следующие особые случаи:
!список пуст (в нем еще нет звеньев);
!включать новое звено нужно в начало списка;
!включать новое звено нужно в конец списка.
Рис. 11.1. Схема списка с тремя звеньями
492
Программная реализация может быть такой:
/* inList.c – функция включения звена в связный список */
struct cell * inList(struct cell * list, struct cell * new)
{
struct cell * current = list; struct cell * previous = NULL; while(1)
{if (current == NULL)
{if (previous == NULL)
return new; /* Списка не было.*/ /* Дошли до конца списка: */ previous -> next = new;
return list;
}
if (new -> len > current -> len)
{previous = current; current = current -> next;
}
else
{new -> next = current;
if (previous == NULL) return new; previous -> next = new;
return list;
}
}
}
В теле функции определены два указателя типа struct cell *. Указатель current адресует очередное звено списка. Указатель previous сохраняет адрес предыдущего звена. Указатель current инициализирован адресом первого звена списка. Указатель previous инициализирован значением NULL. Если current==NULL, и при этом previous==NULL, то список пуст и в него включается единственное новое звено, адресуемое параметром new. Если только current==NULL, то достигнут конец списка, туда "присоединяется" новое звено и возвращается старый адрес начала списка. Если длина строки из звена new больше длины строки текущего звена (new->len > current->len), то необходимо перейти к сравнению со следующим звеном списка. В этом случае previous получает адрес "текущего" звена, а current – адрес следующего за
493
ним. В противном случае, когда (new->len <= current->len) нужно вставить звено new в список. Здесь возможны два варианта – current адресует начальное звено списка (previous==NULL) или какое-то среднее (previous!=NULL). В обоих случаях компоненту new->next присваивается значение указателя current (адрес текущего звена). Затем, если previous==NULL, то возвращается новый адрес начала списка. В противном случае в предыдущем звене сохраняется адрес нового (подключаемого) звена и возвращается старый адрес начала списка. Все операции выполняются в "бесконечном" цикле, выходы из которого соответствуют разным точкам включения звена в список.
Глядя на ту же схему списка (см. рис. 11.1), несложно написать функцию печати строк из звеньев списка:
/* printList.c – функция печати строк из списка */ void printList(struct cell * list)
{
struct cell * p = list; while(p != NULL)
{puts(p -> pLine); p = p -> next;
}
}
Текст основной программы соответствует приведенному выше псевдокоду:
// 11_15.c - упорядочить строки из входного потока
#include <stdlib.h> #include <stdio.h> #include <string.h>
/* Структурный тип "Звено списка": */ struct cell {
int len;
struct cell * next; char * pLine;
}; /* Функция для чтения строки. */
#define S_AR 4000 #include "getLine.c"
494

/* Функция для формирования звена списка. */ #include "cellCreate.c"
/* Включить новое звено в список */ #include "inList.c"
/* Напечатать строки из списка */ #include "printList.c"
int main()
{
struct cell * list = NULL; struct cell * new;
puts("Input text (EOF - end of run):"); while(1)
{new = cellCreate();
if (new == NULL) break; list = inList(list,new);
}
printList(list); return 0;
}
Результат выполнения программы:
Input text (EOF - end of run): list<ENTER>
098<ENTER>
stop!<ENTER>
1<ENTER>
^Z<ENTER>
1
098 list stop!
Исполнение программы возможно только при моделировании сигнала EOF клавишами "Сtrl+Z" или при чтении данных из текстового файла.
495
ЗАДАЧА 11-16. Определите, сколько раз каждое слово встречается во входном потоке. Выведите на экран в алфавитном порядке список слов с указанием количества их появлений. Используйте для обработки двоичное дерево.
Предлагаемую задачу можно решать с помощью односвязного списка, как это сделано в предыдущей задаче. Однако производительность линейного поиска делает такое решение неэффективным даже при не слишком больших объемах обрабатываемых данных. Поэтому будем использовать двоичное дерево, "растущее" по мере чтения из входного потока новых слов.
Введем ограничение – будем анализировать только слова из букв латинского алфавита. Это позволит воспользоваться библиотечной функцией для сравнения слов:
int strcmp(const char * s1, const char * s2);
Функция выполняет сравнение строк, адресуемых указателями s1 и s2. Сравнение выполняется в соответствии с ASCII-кодами символов. Если в соответствии с алфавитной упорядоченностью s1<s2, результат отрицателен. Если s1>s2, результат положителен. При совпадении строк результат равен нулю.
Второе ограничение, скорее даже соглашение, делается для упрощения процедуры выбора слов из входного потока. Будем считать словом любую последовательность, не содержащую никаких символов, отличных от строчных латинских букв. Таким образом, "don't", воспринимается как два слова "don" и "t".
Алгоритм решения задачи может быть таким:
Цикл до конца входного потока (EOF) Прочитать очередное слово Внести слово в двоичное дерево
Конец - цикла Печатать в алфавитном порядке информацию из двоичного дерева
Для чтения из входного потока очередного слова определим функцию:
/* getWord.c - функция чтения слова из латинских букв */
496
#include <stdio.h> #define LEN_AR 400 char * getWord(void)
{
int len=0;
char word[LEN_AR]; char * pWord;
int c; while(1)
{ c=getchar(); if(strchr("abcdefghijklmnopqrstuvwxyz",c)!=NULL)
{ word[len++] = c;
if (len >= LEN_AR-1)
{puts("\nERROR! Word is very long!"); exit(1);
}
continue;
}
if (len == 0)
if (c != EOF) continue; else return NULL;
break;
}
word[len] = '\0';
pWord = (char *) malloc(len+1); if (pWord == NULL)
{puts("\nERROR! No memory!"); exit(1);
}
strcpy(pWord,word); return pWord;
}
При достижении EOF функция getWord() должна возвращать значение NULL. В противном случае возвращается адрес динамически выделенного участка памяти, содержащего строку (очередное слово из входного потока).
Функция getWord() не содержит средств для освобождения памяти. Для каждого слова выделяется отдельный участок динамической памяти, и все слова, прочитанные в программе функцией getWord(), доступны по их адресам.
497
Чтобы продемонстрировать особенности исполнения функции getWord(), выполним такую тестовую программу:
/* 11_16_1.c – проверка функции чтения getWord() */ #include <stdio.h>
#include "getWord.c" int main (void)
{
char * word=NULL;
puts("Input text (EOF - end of run):"); while (word=getWord())
puts(word); return 0;
}
Результат выполнения программы:
Input text (EOF - end of run): wer 562 adsfg uety247ahjk<ENTER> wer
adsfg uety ahjk
sdfgsdghsghdsfg fsghxeyt27247zcgvnas7<ENTER> sdfgsdghsghdsfg
fsghxeyt zcgvnas ^Z
Обратите внимание на исходные данные и результаты. Программа начинает обрабатывать входной поток после каждого нажатия клавиши ENTER. Прекращение выполнения – моделирование кода EOF сочетанием клавиш "Ctrl+Z".
Для построения двоичного дерева определим структурный тип:
struct node {
int counter; /*счетчик для данного слова*/ struct node * left; /*ссылка на левую вершину*/
struct node * right; /*ссылка на правую вершину*/ char *nWord; /указатель на слово*/
}
498
Для удобства введем короткое имя типа:
typedef struct node Node;
Чтобы поместить слово в двоичное дерево, необходимо направленным образом перебирать его вершины, начиная от корня дерева. Слово каждой вершины сравнивается с вводимым. Если они совпали, следует увеличить счетчик слова вершины (элемент структуры counter) и прекратить перебор. В противном случае нужно "перемещаться" к левой или правой из двух нижних вершин. Выбор направления зависит от алфавитной упорядоченности сравниваемых слов. Если при попытке перемещения из очередной вершины окажется, что нужное "направление" (указатель left или right) имеет значение NULL, то вводимое слово отсутствует в исследуемом дереве. В этом случае нужно создать вершину (как объект структурного типа Node), поместить в нее новое слово и "связать" вершину с последней проанализированной вершиной дерева, т.е. присвоить соответствующему указателю left или right адрес созданной вершины.
Для создания новой вершины, включающей заданное слово, определим функцию:
/* newNode.c – функция формирования новой вершины дерева */
Node * newNode(char * word)
{
Node * point;
if (word == NULL) return NULL;
/* Выделить память для очередной вершины дерева: */ point=(Node *)malloc(sizeof(Node));
if (point == NULL)
{puts("\nERROR! No memory!"); exit(1);
}
point -> left = NULL; point -> right = NULL; point -> counter = 1; point -> nWord = word; return point;
}
499
Получив в качестве параметра word адрес слова, функция newNode() выделяет участок динамической памяти для структуры типа Node. Счетчику слов (элемент counter из структуры) присваивается единичное значение. Указателю nWord из структуры присваивается значение параметра word. Указатели на ветви дерева (left, right) получают нулевые значения (NULL).
Имея функцию newNode(), определим функцию, выполняющую "внесение" слова в двоичное дерево. (Используем такой не очень четкий термин "внесение", чтобы подчеркнуть, что слово либо учитывается за счет увеличения соответствующего счетчика, либо подключается к дереву в новой вершине.)
/* addWord.c – функция добавления слова (новая вершина или учет) */
void addWord(Node * tree, char * word)
{
int comp;
if (tree == NULL)
{ puts("The tree is empty!"); exit(1); }
while (1)
{comp = strcmp(word, tree -> nWord); if (comp == 0)
{tree -> counter++; free(word); return; }
if (comp < 0)
{if (tree -> left == NULL)
{tree -> left = newNode(word);
return; }
tree = tree -> left;
}
else
{if (tree -> right == NULL)
{tree -> right = newNode(word); return;
}
tree = tree -> right;
}
}
}
500