

МУ Эконометрика 1477
.pdf31
Рис. 20. Описательная статистика переменных
Если возникает необходимость проанализировать матрицу коэффициентов корреляции, то необходимо выбрать View/Correlations. Результат представлен на рис. 21.
Рис. 21. Матрица коэффициентов корреляции
Вы также можете исследовать характеристики для отдельных серий (переменных), совместив вывод диаграммы и числовых характеристик. Дважды щелкните на имени серии (например, на переменной consumption) и выберете в рабочем файле пункт меню View/Descriptive Stats/Histogram and Stats. Результат наглядно виден на рис. 22.
Рис. 22. Описательная статистика переменной CONSUMPTION
32
2.2. Применение Eviews при построении и анализе линейной однофакторной модели регрессии
Для демонстрации анализа линейной модели создадим рабочую группу Group1 из переменных CONSUMPTION и INCOME. Зависимой переменной будет переменная CONSUMPTION.
Для просмотра описательных статистик выберем пункт
View/Descriptive Stats/Common Sample.
Для построения поля корреляции в окне Workfile выберем следую-
щие пункты меню: View/Graph/Scatter/Simple scatter. Полученный в ре-
зультате график представляет собой поле корреляции результативного и факторного признаков (рис. 23).
Рис. 23. Поле корреляции результативного и факторного признаков
В окне Workfile (используя созданную группу из двух переменных) выберем: View/Correlation. Полученная таблица корреляционная матрица, в которой отражено значение коэффициента парной корреляции результативного и факторного признаков.
Для оценки регрессии в командной сроке окна EViews опишем в общем виде искомое уравнение: ls consumption c income (метод наименьших квадратов (LS) эндогенная переменная, константа, экзогенная переменная), или выбрать в строке главного меню EViews: Quick/Estimate equation (рис. 24).
Рис. 24. Окно уравнения регрессии

33
В открывшемся окне (рис. 25) должны быть переменные: зависимая переменная, применяемый метод, число наблюдений, параметры уравнения регрессии, стандартные ошибки, значения t–статистик и соответствующие им вероятности, значение R2 и ряд других показателей.
Рис. 25. Окно параметров регрессии
Остановимся на описании статистик, характеризующих качество модели, и присутствующих в стандартном окне уравнения EViews.
Коэффициент детерминации R2 (R-squared)
R2 |
|
ˆ'ˆ |
|
1 |
|
, |
|
y ˆ ' y |
|||
где ˆ выборочное среднее зависимой переменной yt; ˆ вектор-
столбец случайных ошибок регрессии.
При стандартных предположениях коэффициент детерминации может быть интерпретирован как доля дисперсии зависимой переменной yt, которая объясняется при помощи данного набора экзогенных переменных. Если регрессия оценивается методом наименьших квадратов, значения коэффициента детерминации изменяются от 0 до 1. В некоторых случаях (например, при использовании других методов оценивания) коэффициент детерминации может быть отрицательным.
Скорректированный коэффициент детерминации Radj2 (Adjusted
R-squared)
2 2 T 1
Radj 1 1 R ,
T k
где k – число оцениваемых параметров.
Поскольку обычный коэффициент детерминации R2 не уменьшается при включении в оцениваемую модель дополнительных переменных, то он не может служить хорошей мерой качества множественной регрес-

34
сии. При расчете скорректированного коэффициента детерминации вводится штраф за дополнительные регрессоры, которые не способствуют увеличению объясняющей силы регрессии. Значение скорректированного коэффициента детерминации не превышает соответствующих значений обычного коэффициента детерминации, могут уменьшаться при включении в регрессию дополнительных переменных и могут быть отрицательным, если модель плохо специфицирована.
Стандартная ошибка регрессии s.e.regr. (S.E. of regression)
s.e.regr. = 
 ˆ'ˆ .
ˆ'ˆ .
T k
Сумма квадратов остатков регрессии RSS (Sum squared resid). Дан-
ный показатель приводится в окне регрессии для удобства пользователя, поскольку используется для расчета многочисленных статистических характеристик регрессии.
T
RSS = SSR = ˆ'ˆ yt Xt'b 2 ,
t 1
где Xt – матрица объясняющих переменных; b – вектор-столбец коэффициентов при объясняющих переменных соответствующих размерностей.
Логарифм функции правдоподобия l (Log likelihood)
|
T |
|
ˆ'ˆ |
|
l |
|
1 log 2 log |
|
. |
|
|
|||
2 |
|
T |
||
Логарифм функции правдоподобия вычисляется при предположении, что остатки модели нормально распределены.
Статистика Дарбина-Уотсона DW (Durbin-Watson stat). Позволяет определить (при определенных условиях на параметры модели) наличие автокорреляции остатков первого порядка
T
ˆt ˆt 1 2
DW |
t 2 |
|
. |
|
T |
||
|
|
ˆt2 |
|
|
|
t 1 |
|
Среднее значение и стандартное отклонение переменной ˆ и ˆ y
(Mean dependent var и S.D. dependent var). Среднее значение и стандартное
отклонение зависимой переменной вычисляются с использованием стандартных формул:
|
T |
|
T |
|
|
|
yt |
|
yt ˆ 2 |
|
|
ˆ |
t 1 |
и ˆ y |
t 1 |
. |
|
|
|||||
T |
T 1 |
||||
|
|
|

35
Информационный критерий Акаике AIC (Akaike info criterion).
AIC 2 l 2 k , T T
где l логарифм функции правдоподобия; k – количество оцениваемых в модели параметров. Информационный критерий Акаике, так же как и информационный критерий Шварца, используется для выбора лучшей модели из некоторого набора альтернативных моделей – чем меньше значение критерия, тем лучше модель.
Информационный критерий Шварца BIC или SC (Schwarz criterion).
BIC SC 2 l klogT . T T
Информационный критерий Шварца всегда выбирает лучшую модель с числом параметров, не превышающим число параметров в модели, которая была выбрана по критерию Акаике. Кроме того, критерий Шварца является асимптотически состоятельным, в то время как информационный критерий Акаике смещен в сторону выбора перепараметризованной модели.
F-статистика (F-statistic). При помощи F-статистики в предположении, что остатки модели распределены нормально, проверяется гипотеза о значимости регрессии в целом, т.е. проверяется нулевая гипотеза о том, что коэффициенты при всех экзогенных переменных, включенных в модель, кроме свободного члена, значимо отличаются от нуля.
F |
R2 |
k 1 |
, |
1 R2 |
|||
|
|
T k |
|
где k – число ограниченной в модели, т.е. число оцениваемых параметров (включая константу). Также в окне регрессии EViews приводится Р- значение для F-статистики (Prob(F-statistic)). Если Р-значение меньше, чем уровень значимости, на котором вы проверяете нулевую гипотезу, то гипотезу о том, что все коэффициенты модели равны нулю, можно отвергнуть на этом уровне значимости. Помните, что регрессия может быть значимой, даже если каждый коэффициент в отдельности не значим.
Для построения эмпирической линии регрессии в окне Workfile выделим группу переменных и выберем: View/Graph/Scatter/Scatter with regression. В промежуточном окне необходимо нажать OK. Полученный график (рис. 26) – эмпирическая линия регрессии.

36
Рис. 26. Окно эмпирической линии регрессии
Чтобы построить теоретическую (подогнанную) линию регрессии, необходимо найти теоретические (вычисленные с помощью уравнения регрессии) значения результативного признака. Для этого открыть окно с параметрами уравнения регрессии, далее выбрать Forecast. Появится окно, в котором к исходным добавилась новая переменная CONSUMPTIOF (прогнозное, (теоретическое, выровненное) значение переменной CONSUMPTION). Полученный график (рис. 27) – теоретическая (подогнанная) линия регрессии.
Рис. 27. Окно теоретической линии регрессии
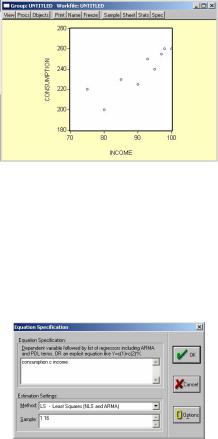
Следующая операция возможна только в том случае, если ей предшествует построение регрессионного уравнения. В окне Workfile можно дважды щелкнуть на переменной Resid (случайная составляющая, остаток). Далее, выберем: View/Line graph, или, открыв окно с параметрами уравнения регрессии, выбрать: View/Actual,Fitted…/Actual,Fitted…table.
Результат представлен на рис. 28.
37
Рис. 28. Окно случайной составляющей
2.3. Применение Eviews при построении и анализе многофакторной модели регрессии
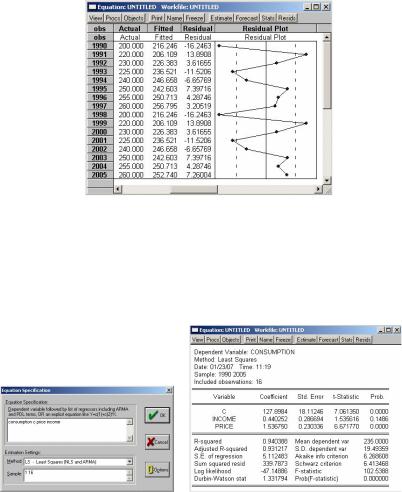
Построим регрессионное уравнение МНК, в котором зависимая переменная – объем потребления продукции (CONSUMPTION), а независимые –доход на душу населения (INCOME) и цена за единицу продук-
ции (PRICE) (рис. 29).
Рис. 29. Множественная регрессия
Уравнение примет следующий вид:
Yi = a0 + a1∙INCOME + a2∙PRICE + ei.
Подставим полученные оценки из итоговой формы вывода:
Yˆi = 127,898 + 1,5367 PRICE + 0,4403 INCOME.
38
2.4. Выявление гетероскедастичности и автокорреляции в модели
Используя Eviews, можно провести проверку и устранение гетероскедастичности следующим образом:
Запустить стандартную регрессию.
Вычислить остатки.
Запустить регрессию с использованием квадрата остатков как зависимой переменной и оценить зависимую переменную yˆ как
независимую переменную (тест White). В окне регрессии выбрать
Views/Residual Tests/White Heteroskedasticity (no cross terms).
Оценить nR2, где n – объем выборки, R2 – коэффициент детерминации.
Использовать статистику Фишера с одной степенью свободы (в
Eviews – используется F-статистика) для проверки существенности отличия nR2 от нуля.
Основным способом устранения гетероскедастичности является применение взвешенного метода наименьших квадратов.
Для проверки гипотезы о наличии автокорреляции используются различные методы:
1.Тест на основе критерия Дарбина-Уотсона. Недостаток этого метода заключается в определении автокорреляции только первого порядка.
2.Тест по Q-статистике. Позволяет определить автокорреляцию любого порядка, поэтому является более предпочтительным по сравнению с критерием Дарбина-Уотсона.
3.Тест Бройша и Гофри (Breusch-Godfrey) – этот же тест иногда называют МП-тестом. Аналогичен тесту по Q-статистике. Он основан на описании автокорреляции стандартными средними.
1. Тест на основе критерия Дарбина-Уотсона
Для определения автокорреляции с помощью статистики ДарбинаУотсона необходимо рассчитать оценку параметров уравнения линейной регрессии.
Табличное значение статистики Дарбина-Уотсона для нашего эксперимента при уровне значимости = 0,05 dн = 0,98, dв = 1,54.
Из рис. 7 имеем:
1.Если dв < Durbin-Watson stat < 4 dв, можно сделать вывод, что автокорреляция отсутствует.
2.Если 0 < Durbin-Watson stat < dн, то принимается альтернативная гипотеза о положительной автокорреляции.
3.Если 4 – dн < Durbin-Watson stat < 4, то принимается альтернативная гипотеза об отрицательной автокорреляции.

39
4. Если dн < Durbin-Watson stat < dв или 4 dв < Durbin-Watson stat < 4, то
вопрос об отвержении или принятии гипотезы остается открытым (область неопределенности критерия).
Для нашего примера Durbin-Watson stat = 1,33, поэтому вопрос об отвержении или принятии гипотезы остается открытым.
Для более полного анализа можно применить тест Q-статистики. Подробно теоретические вопросы, связанные с проблемами специ-
фикации эконометрических моделей, были рассмотрены в лекционном курсе.
В нашем случае мы ограничимся тем, что попробуем исключить поочередно независимые переменные. Первой исключаем переменную PRICE (табл. 11). Затем исключаем переменную INCOME (табл. 12).
Таблица 11
Dependent Variable: CONSUMPTION Method: Least Squares
Date: 01/23/07 Time: 11:23 Sample: 1990 2005 Included observations: 16
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|
|
|
|
|
C |
54.05240 |
29.05876 |
1.860107 |
0.0840 |
INCOME |
2.027424 |
0.324292 |
6.251849 |
0.0000 |
|
|
|
|
|
R-squared |
0.736275 |
|
|
||
Adjusted R-squared |
0.717438 |
|
|
||
S.E. of regression |
10.36213 |
|
|
||
Sum squared resid |
1503.232 |
|
|
||
Log likelihood |
-59.04529 |
|
|
||
Durbin-Watson stat |
2.219191 |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
Mean dependent var 235.0000
S.D. dependent var |
19.49359 |
||
Akaike info criterion |
7.630661 |
||
Schwarz criterion |
7.727235 |
||
F-statistic |
39.08561 |
||
Prob(F-statistic) |
0.000021 |
||
|
|
|
|
|
|
|
|
Представляется разумным разделять эффект двух независимых переменных на зависимую переменную в модели с совместным их влиянием в регрессионном уравнении. Данный пример иллюстрирует важность использования множественной регрессии вместо парной в случае, когда изучаемое явление существенно детерминирует несколько независимых переменных.
Таблица 12
Dependent Variable: CONSUMPTION Method: Least Squares
Date: 01/23/07 Time: 11:24 Sample: 1990 2005 Included observations: 16
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|
|
|
|
|
C |
154.2402 |
6.089862 |
25.32737 |
0.0000 |
PRICE |
1.830251 |
0.134638 |
13.59386 |
0.0000 |
|
|
|
|
|
R-squared |
0.929575 |
|
|
||
Adjusted R-squared |
0.924545 |
|
|
||
S.E. of regression |
5.354721 |
|
|
||
Sum squared resid |
401.4225 |
|
|
||
Log likelihood |
-48.48242 |
|
|
||
Durbin-Watson stat |
0.845046 |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
Mean dependent var 235.0000
S.D. dependent var |
19.49359 |
||
Akaike info criterion |
6.310303 |
||
Schwarz criterion |
6.406876 |
||
F-statistic |
184.7931 |
||
Prob(F-statistic) |
0.000000 |
||
|
|
|
|
|
|
|
|
40
3. МОДЕЛИРОВАНИЕ ПРОЦЕССОВ ТИПА ARIMA(p, d, q)
Эконометрический пакет EViews позволяет довольно легко моделировать случайные процессы типа ARIMA(p, d, q), поскольку в пакете запрограммированы специальные команды, позволяющие оценивать соответствующие модели.
3.1.Авторегрессионные модели порядка р – AR(p)
Вкачестве общего замечания остановимся на одной специфической особенности оценки авторегрессионных моделей в пакете EViews. В теории временных рядов под авторегрессионной моделью порядка р обычно понимается модель вида:
yt = 0 + 1yt-1 + … + pyt-p + t, |
(11) |
где t WN(0, 2 ). Оценивать такую модель в пакете EViews можно
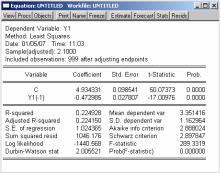
несколькими способами. Например, допустим, у вас есть некий временной ряд у1 (случайный процесс авторегрессии первого порядка с константой равной 5, и коэффициентом при авторегрессионном члене, равном ( 0,5)), и вы хотите оценить для него авторегрессионную модель первого порядка. Тогда наберите в командной строке окна EViews
ls y1 c y1(-1)
В результате появится окно уравнения EViews, в котором отображены результаты оценивания модели (рис. 30).
Рис. 30. Оценка авторегрессионной модели
Меню окна уравнения частично совпадает с меню окна временного ряда, а частично содержит свои специфические опции:
Estimate – данная опция меню позволяет оценивать/переоценивать
модель;
Forecast – позволяет строить прогнозы и вычислять соответст-
вующие статистики;