

RapidMiner_Practic_2
.docПрактика 2
-
Запустите RapidMiner ( .ехе файл на рабочем столе)
-
На панели Repositories активируйте репозиторий, созданный вами на прошлой паре.
-
Запустите из папки Proc процесс Practic_1_Tree
-
Двойным щелчком откройте оператор Validation. Щелчком мыши сделаете активным модель Decision Tree. Обратите внимание на панель Parameters
С помощью пункт Criterion, можно определить используемый критерий для выбора атрибутов и численного распада. Возможны следующие варианты: gain_ratio, information_gain, gini_index, accuracy. По умолчанию указывается критерий "gain_ratio".
minimal size for split: минимальные количество узлов
minimal leaf size:- минимальное количество листьев
minimal gain: - минимальный прирост
maximal depth: - максимальная глубина
confidence: уровень доверия для пессимистического расчета погрешности обрезки.
number of prepruning – число альтернативных атрибутов, используется для уменьшения случаев раскола.
no pre pruning: без предварительной обрезки
no pruning: отключается обрезка дерева (используется для получения полной картины классификации)
-
Ниже представлены значения, которые указываются по умолчанию.

-
Измените исходные данные. Поменяйте Criterion с gain_ratio на information_gain. Запустите процесс, нажав на кнопку
 .
Сохраните процесс в папке Proc,
как Practic_1_tree2.
Сохраните в отчете
screenshot
содержимого вкладки PerformansVector,
с сформулированными выводами относительно
точности (таблица представлена ниже),
так же сохраните screenshot
содержимого вкладки Tree,
с сформулированными выводами относительно
корневого атрибута.
.
Сохраните процесс в папке Proc,
как Practic_1_tree2.
Сохраните в отчете
screenshot
содержимого вкладки PerformansVector,
с сформулированными выводами относительно
точности (таблица представлена ниже),
так же сохраните screenshot
содержимого вкладки Tree,
с сформулированными выводами относительно
корневого атрибута.
|
Интервал точности |
Значение |
|
0-20 |
очень низкая |
|
20-40 |
низкая |
|
40-60 |
посредственная |
|
60-80 |
высокая |
|
80-100 |
очень высокая |
-
Измените исходные данные. Установите флажок на пункте no pre pruning и no pruning . таким образом, мы увеличиваем количество узлов отраженных в дереве. Запустите процесс, нажав на кнопку
 .
Сохраните процесс в папке Proc,
как Practic_1_tree3.
Сохраните в отчете
screenshot
содержимого вкладки PerformansVector,
с сформулированными выводами относительно
точности, так же сохраните screenshot
содержимого вкладки Tree,
с сформулированными выводами относительно
корневого атрибута.
.
Сохраните процесс в папке Proc,
как Practic_1_tree3.
Сохраните в отчете
screenshot
содержимого вкладки PerformansVector,
с сформулированными выводами относительно
точности, так же сохраните screenshot
содержимого вкладки Tree,
с сформулированными выводами относительно
корневого атрибута.
-
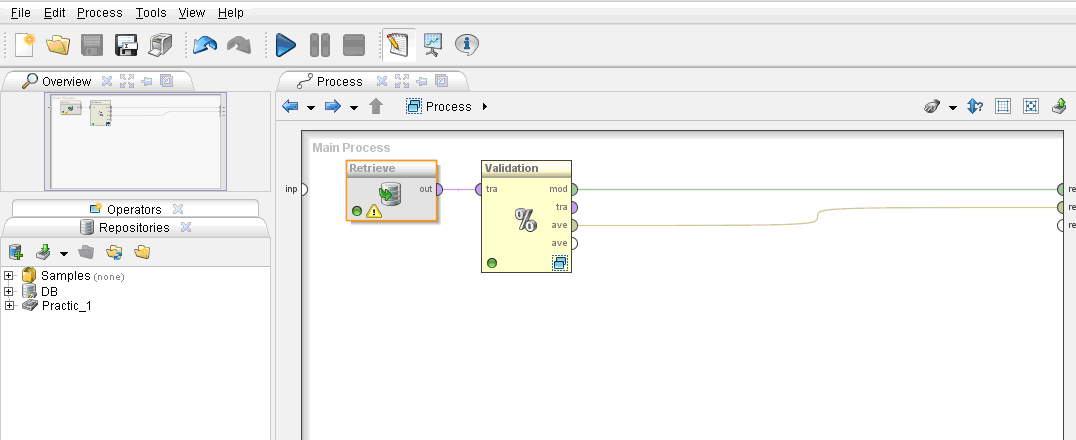
Рассмотрим следующих метод классификации. Метод k-ближайших соседей. Для создания нового процесса нажмите на кнопку
 на
панели инструментов. На первом этапе
необходимо вывести на рабочее поле
операторы Retrieve
и Validation,
создать связи между ними (ниже
представлены пути к оператору)
на
панели инструментов. На первом этапе
необходимо вывести на рабочее поле
операторы Retrieve
и Validation,
создать связи между ними (ниже
представлены пути к оператору)



-
Необходимо загрузить данные в оператор Retrieve для этого нажав на
 в панели Parametes
укажите путь к папке Data
в панели Parametes
укажите путь к папке Data -
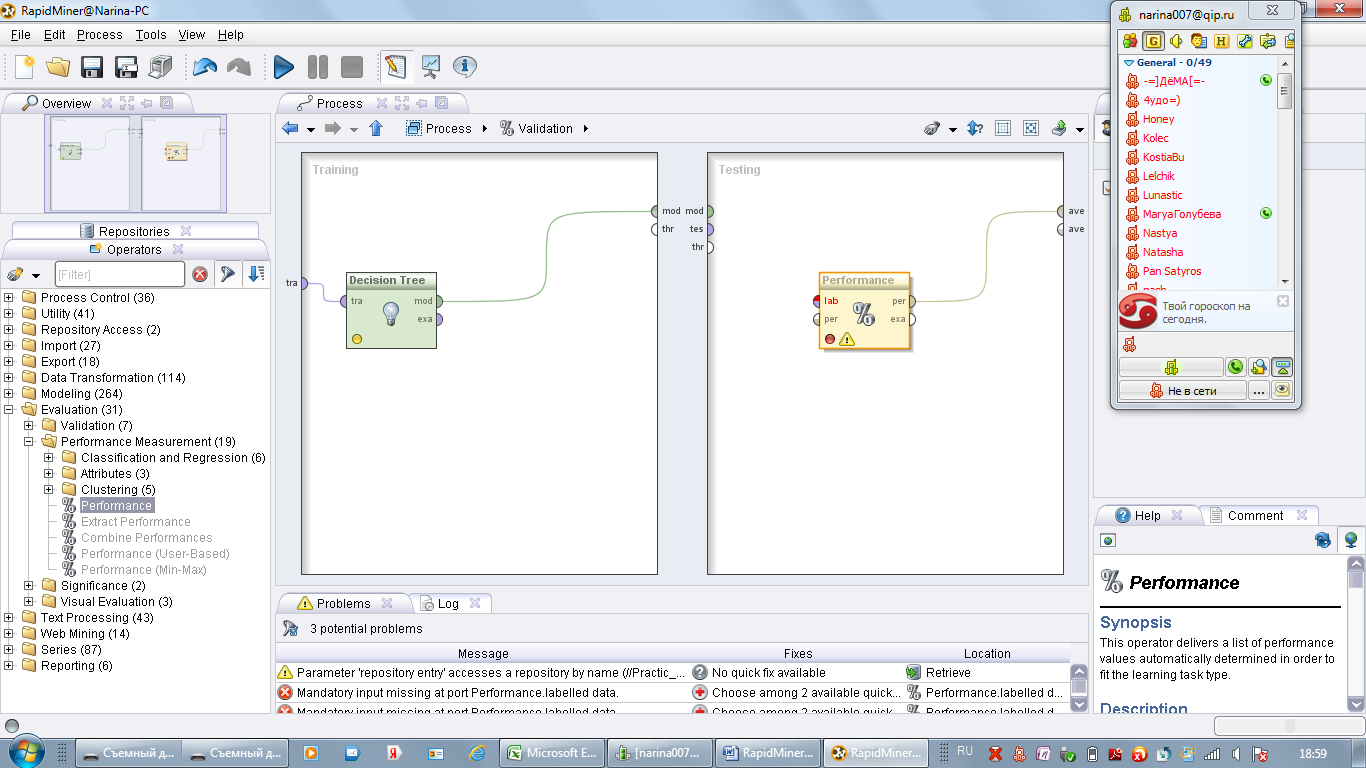
Двойным щелчком откройте оператор Validation. Данный оператор состоит из двух разделенных панелей. В первой панели исходные данные происходит обучение модели, во второй модель тестируется.
В первое поле необходимо перенести оператор для построения модели k-NN. Во второе Apply Model и Performance.
Apply Model- оператор применения построенного дерева к тестовой выборки
Performance- используется для визуализации результатов, результатом работы данного оператора является таблица в которой отражена точность определения того или иного класса.

-
Установите связи между операторами согласно рисунку представленному ниже, запустите процесс, сохранив его в папке Proc, как Practic_1_k-NN

-
Сохраните в отчете screenshot содержимого вкладки PerformansVector, с сформулированными выводами относительно точности.

-
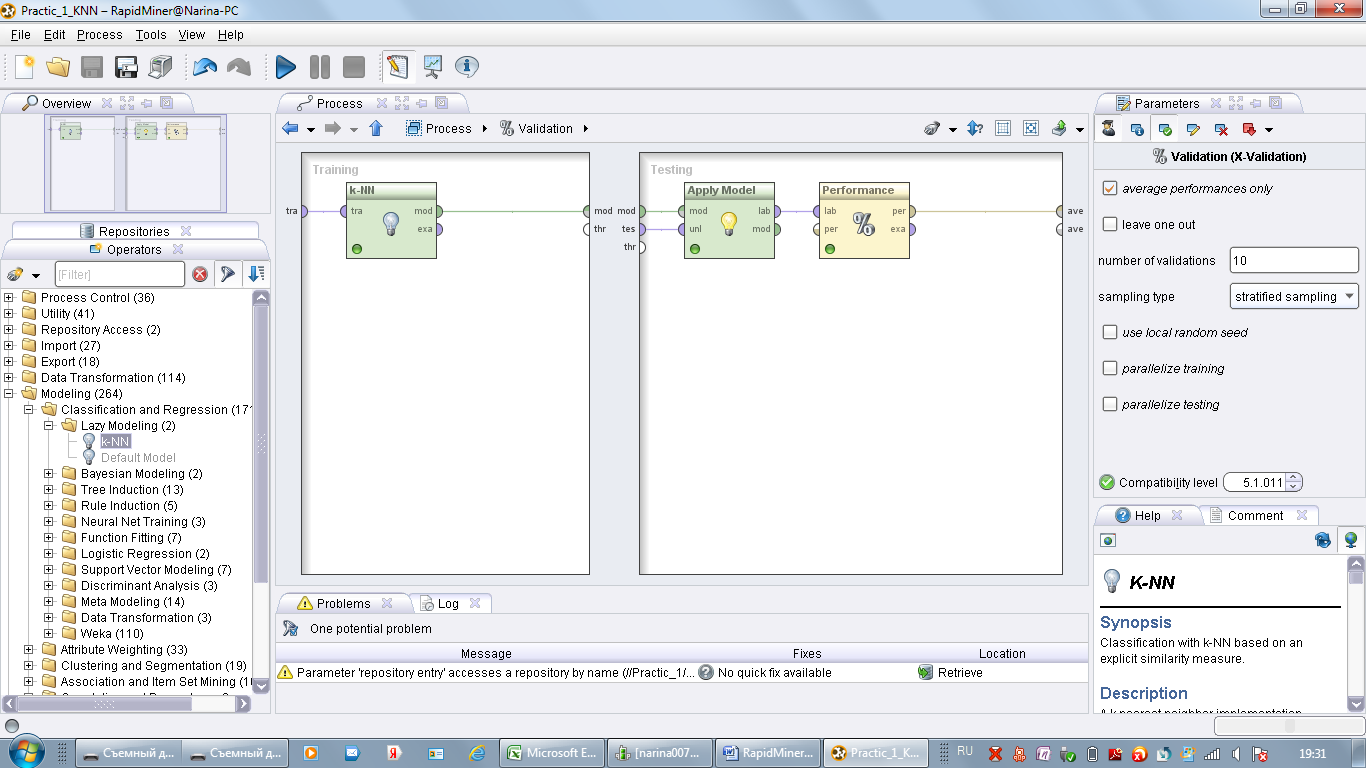
Двойным щелчком откройте оператор Validation. Щелчком мыши сделаете активным модель k-NN. Обратите внимание на панель Parameters

-
На панели Parameters по умолчанию число k-соседей рано 1. Измените исходные данные на 3. То есть количество ближайших соседей будет рано трем. Запустите процесс, сохранив его в папке Proc, как Practic_1_k-NN2
-
Сохраните в отчете screenshot содержимого вкладки PerformansVector, с сформулированными выводами относительно точности.
-
Измените исходные данные на 6. То есть количество ближайших соседей будет рано шести. Запустите процесс, сохранив его в папке Proc, как Practic_1_k-NN3
-
Сохраните в отчете screenshot содержимого вкладки PerformansVector, с сформулированными выводами относительно точности.
-
Сравните выводы относительно точности при k=1, k=3, k=6. В каком случае точность выше. Отразите это в отчете.
-
Рассмотрим следующих метод классификации. Метод Нейронная сеть. Для создания нового процесса нажмите на кнопку
 на
панели инструментов. На первом этапе
необходимо вывести на рабочее поле
операторы Retrieve
и Validation,
создать связи между ними (ниже
представлены пути к оператору)
на
панели инструментов. На первом этапе
необходимо вывести на рабочее поле
операторы Retrieve
и Validation,
создать связи между ними (ниже
представлены пути к оператору)
-
Двойным щелчком откройте оператор Validation. Данный оператор состоит из двух разделенных панелей. В первой панели происходит обучение модели, поместите ниже представленные операторы
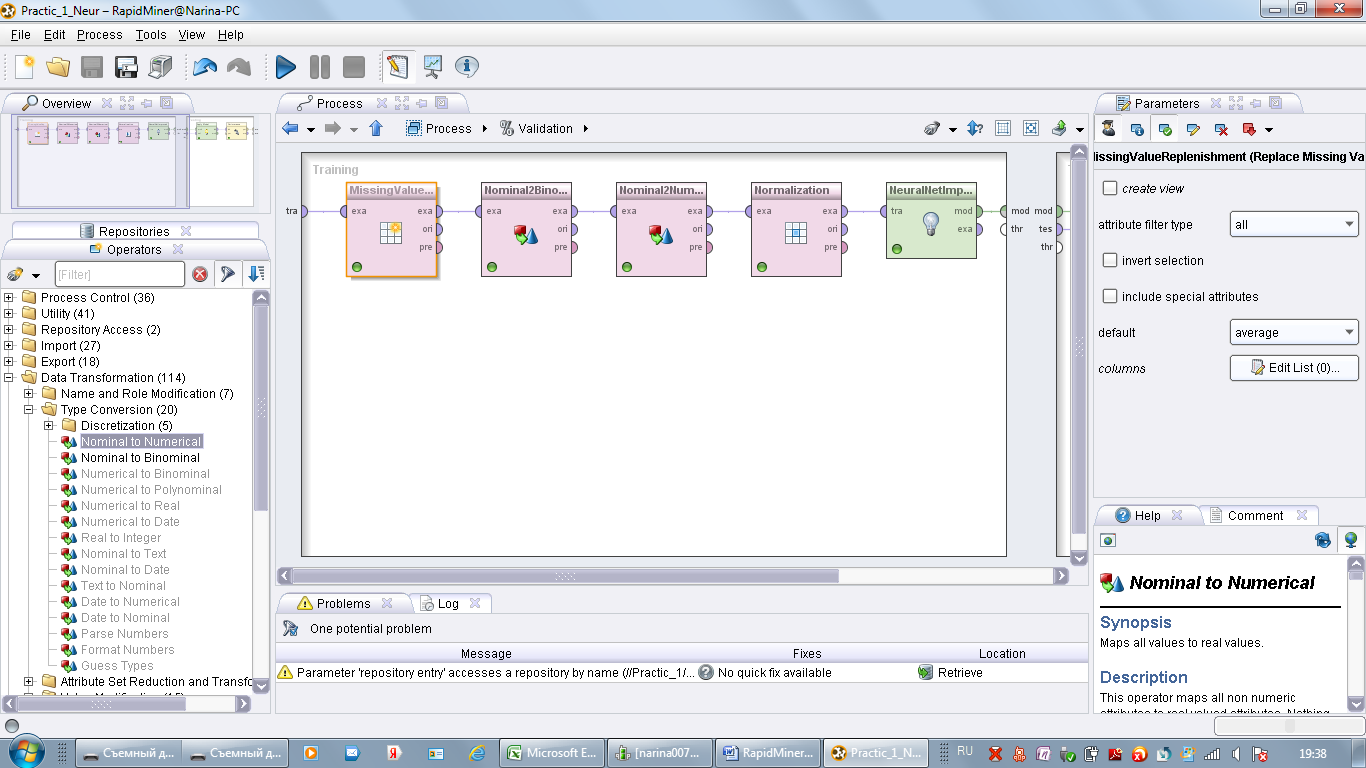



-
Во второй панели исходные данные тестируется. Поместите ниже представленные операторы во второй панели.



-
Сохраните в отчете screenshot содержимого оператора Validation. Запустите процесс, нажав на кнопку
 .
Сохраните процесс в папке Proc,
как Practic_1_Neur.
Сохраните в отчете
содержимое вкладки PerformansVector, с
сформулированными выводами относительно
точности. Перейдите
с вкладки PerformansVector на ImprovedNeuralNet
.
Сохраните процесс в папке Proc,
как Practic_1_Neur.
Сохраните в отчете
содержимое вкладки PerformansVector, с
сформулированными выводами относительно
точности. Перейдите
с вкладки PerformansVector на ImprovedNeuralNet

-
Сохраните в отчете screenshot содержимого вкладки а ImprovedNeuralNet с сформулированными выводами относительно точности.
