

Динамический вектор.
Динамический вектор подобен простому вектору. Доступ к элементам вектора остается прямым и осуществляется с помощью индекса. Тип индекса может быть произвольным дискретным типом. Чаще всего индексы выбираются целочисленные.
Напишем набор методов для динамического вектора с целочисленными индексами и подвижной верхней границей. Считаем, что нижняя граница равна 1 и не может быть изменена.
Конструктор { cоздает пустой вектор}.
Деструктор {уничтожает вектор}.
Сделать пустым.
Пуст?
Верхний индекс число элементов.
Добавить в конец.
Удалить из конца (или изъять из конца).
Доступ для чтения.
Доступ для записи.
Принципы реализации.
Заметим что, реализация динамического вектора может быть достаточно эффективной только на основе массива.
1). Реализация на основе одномерного массива.
В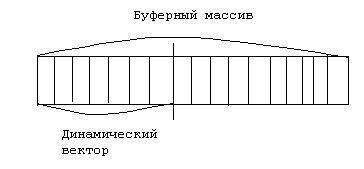 этом случае выделяется буферный массив
в части которого и располагается
динамический вектор. При этом хранится
индекс ячейки в которой расположен
последний элемент вектора. Может
возникнуть ситуация когда весь буферный
массив будет заполнен. В этом случае
придется выделять новый буфер, который
больше предыдущего.
этом случае выделяется буферный массив
в части которого и располагается
динамический вектор. При этом хранится
индекс ячейки в которой расположен
последний элемент вектора. Может
возникнуть ситуация когда весь буферный
массив будет заполнен. В этом случае
придется выделять новый буфер, который
больше предыдущего.
З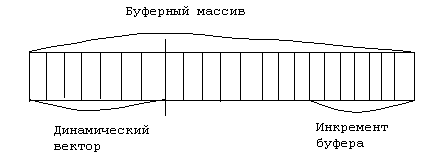 атем
необходимо перекопировать элементы из
старого буфера в новый и дописать
элемент. Величина на которую увеличивается
буфер называется инкрементом буфера.
При этом если в буфере освобождается
слишком много места то можно провести
обратную операцию. После каждой такой
операции старый буфер необходимо
уничтожить.
атем
необходимо перекопировать элементы из
старого буфера в новый и дописать
элемент. Величина на которую увеличивается
буфер называется инкрементом буфера.
При этом если в буфере освобождается
слишком много места то можно провести
обратную операцию. После каждой такой
операции старый буфер необходимо
уничтожить.
В случае использования такой модели можно добавить несколько операций:
А) Дополнительный конструктор (в качестве параметров задается начальная длина буфера и длина инкремента).
Б) Изменение длины инкрементной части.
В) Установить длину буфера (необходимо чтобы избежать массовых операций).
Данная модель реализации крайне неудобна. Она требует большое количество памяти, а также приводит к появлению массовых операций (например, копирование элементов буфера).
2). Модель реализации динамического вектора на основе двумерной таблицы.
В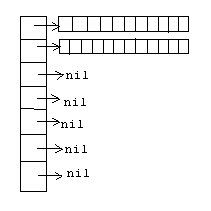 этом случае создается массив указателей,
который указывает на строки, в которых
располагается динамический вектор.
Если в текущей строке нет свободного
места, то для добавления элемента
выделяется память под новую строку и
туда вписывается новый элемент. Удаление
осуществляется в обратном порядке, но
строка не удаляется. Удаление осуществляется
в том случае если строк накопилось
несколько.
этом случае создается массив указателей,
который указывает на строки, в которых
располагается динамический вектор.
Если в текущей строке нет свободного
места, то для добавления элемента
выделяется память под новую строку и
туда вписывается новый элемент. Удаление
осуществляется в обратном порядке, но
строка не удаляется. Удаление осуществляется
в том случае если строк накопилось
несколько.
Если двумерный массив заполнен полностью и необходимо добавить еще один элемент, то создается больший массив указателей. При этом копированию будут подвергаться уже указатель, что позволяет избежать массовости данной операции.
Возникает вопрос, возможно ли использовать более сложные модели (трехмерный, четырех мерный массивы). Да это возможно, но острой необходимости в этом нет. Практически во всех типах программ, где необходимо использование динамического вектора, достаточно одного из двух перечисленных выше типов для обеспечения быстроты работы программы.
Множество
Множество отличается от всех других структур данных прежде всего тем, что все операции происходят в теоретико-множественном смысле. Если добавляется существующий в множестве элемент, то изменения множества не происходит, а при удалении не находящегося в множестве элемента не возникает ошибочной ситуации. Рассмотрим подпрограммы необходимые для работы с множествами.
1. Конструктор { Init; } - создание пустого множества
2. Деструктор { Done; } - уничтожение множества
3. Сдеать пустым { DoEmpty; }
4. Пусто? { IsEmpty:boolean; }
5. Добавить { Insert(x:KeyType); } - добавить элемент в множество. Можно сделать функцию,
которая возвращает в качестве результата произошло ли реальное добавление элемента в
множество.
6. Удалить { Del(x:KeyType); } - удалить элемент из множества
7. Принадлежит? { IsPresent(x:KeyType):boolean; } - проверить, принадлежит ли данный
элемент множеству.
8. Взять какой-нибудь { Extract(var x:KeyType); } - взять произвольный элемент из
множества. Следует учитывать, что данная операция должна выполняться достаточно
быстро.
Общее требование ко всем реализациям - операции должны выполняться как можно быстрее. Существует очень много идей реализации множеств. Рассмотрим только некоторые:
самая простая - битовая. Используется в том случае когда мощность множества А конечно
и невелико (пример: мощность множества символов - 256, мощность множества целых чисел
из небольшого диапазона - невелико). В этом случае можно построить функцию
взаимооднозначную функцию h(x): A _ I (где I - множество целых чисел от 0 до M-1
(M - мощность)) Для хранения используют битовую строку.
 Иногда
множество может начинаться с середина
байта, т.е. функция отображает
в число не
от 0. Основное действие, которое делает
конструктор - зануляет байты. Запись
осуществляется путем поиска соответствующего
элементу байта, а затем и бита, и занесение
в него с помощью логического "или"
значения 1. Удаление происходит почти
также, но соответственный бит надо
занулить. Если M - очень мало, то можно
незначительно ускорить работу с
множеством выделяя под элемент не бит,
а байт (правда, тогда на реализацию
множества будет тратится в 8 раз больше
памяти, но зато можно осуществлять
прямой
Иногда
множество может начинаться с середина
байта, т.е. функция отображает
в число не
от 0. Основное действие, которое делает
конструктор - зануляет байты. Запись
осуществляется путем поиска соответствующего
элементу байта, а затем и бита, и занесение
в него с помощью логического "или"
значения 1. Удаление происходит почти
также, но соответственный бит надо
занулить. Если M - очень мало, то можно
незначительно ускорить работу с
множеством выделяя под элемент не бит,
а байт (правда, тогда на реализацию
множества будет тратится в 8 раз больше
памяти, но зато можно осуществлять
прямой
доступ к элементам).
2) реализация на базе массива
Есть несколько возможных видов реализации множеств на базе массивов. Рассмотрим только
некоторые. При данных типах реализации не требуется конечности множества A, но число
участвующих в операциях элементов должно быть конечно.
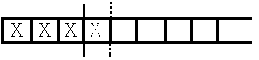 а)
а)
При добавлении необходимо пробежать по всей первой части в поисках добавляемого
элемента. Если он не найден, то добавляем элемент в конец и смещаем индекс
последнего элемента на 1. При удалении элемента мы опять пробегаем все элементы
массива до элемента на который указывает индекс конца массива. Если элемент не
обнаружен, то ничего не делаем, иначе удаляем его, смещая все элементы, стоящие за
ним, вправо. Все операции(за исключением команды "взять какой-нибудь") выполняются
за время пропорциональное числу элементов, поэтому данная форма организации
используется крайне редко и только для маленьких массивов. Подобную организацию
также возможно сделать на базе динамического вектора и списка.
б) на базе отсортированного массива. При такой организации облегчается поиск
элементов. Поиск элементов в отсортированном массиве можно осуществить за
логарифмическое время (например, с помощью метода деления пополам). Но изъятие и
добавление зависят от количества элементов. Такой тип организации используют в тех
программах, в которых сначала добавляется очень много элементов, после этого
множество не изменяется, а идет только проверка на принадлежность множеству.
Основные характеристики:
сортировка (нетривиальная) - за время ~n*log2n
проверка на принадлежность - за время ~ log2n
3) на основе хэш-функции
Есть несколько возможных видов реализации множеств с хэш-функциями. Рассмотрим только
два.
a) на базе массива элементов множества
Хэш-функция - это функция h(x):A _ I = 0..N-1, где N>=P (P - максимальное число
элементов которое может включать множество). Насколько большое число N надо взять –
это можно выяснить только путем обстоятельного исследования. В основном берут число
N раза в 2 или 3 превышающее P. При инициализации множества в него заносятся
какие-нибудь значения, которые заведомо не принадлежат множеству (например, если вы
намериваетесь хранить в множестве действительный числа из отрезка [0,1], то в
качестве заполняющего элемента можно взять число 2.0), при этом элементы равные
данному значению считаются пустыми. При добавлении элемента вычисляется значение
хэш-функции и делается попытка обратится к массиву с индексом равным значению
хэш-функции. Если данный элемент пустой, то добавляемый элемент записывается в это
место. Если же клетка оказалась и содержит значение не равное добавляемому
элементу, то идем вправо и записываем число в первую свободную ячейку. Благодаря
использованию хэш-функции добавление элементов осуществляется гораздо быстрее, но
количество пустых промежутков должно быть как можно быстрее, поэтому и число N
выбирается достаточно большим. Удаление осуществляется почти также, но реализовать
его довольно сложно, т.к. необходимо сдвинуть элементы на соответствующие значения
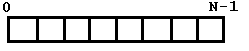 хэш-функции.
хэш-функции.
При таком способе заполнения массива элементы имеют тенденцию заполняться
неравномерно, поэтому часто заполняют массив с помощью квадратичной функции, т.е.
если элемент оказался не пустым, то обратиться ко второму после него, затем к 4, 16
и т.д. При этом надо так подобрать число N, чтобы функция пробегала все ячейки
массива. Кроме этого можно ввести дополнительную хэш-функцию.
б) может возникнуть вопрос - а почему бы не хранить в массиве указатели на структуры
 хранящие
элементы с заданным значение хэш-функции.
хранящие
элементы с заданным значение хэш-функции.
Тогда добавление и удаление можно реализовать проще. На подобных доводах и была
основана следующая реализация - хранение массива указателей на другие структуры. При
использовании данной организации уже не обязательно, чтобы N>=P. Но хэш-функция
должна быть выбрана так, чтобы слабо зависеть от элементов. Например, при хранении
рациональных дробей хэш-функция может быть функцией, берущей остаток от деления
знаменателя на какое-нибудь число. В результате время работы алгоритма достаточно
малое.
4) бинарное дерево
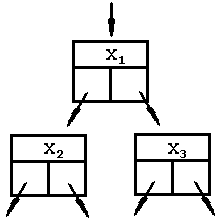 Структура
бинарного дерева изображена на рисунке,
при этом дерево формируется так, чтобы
для любого его узла X2<X1<X3.
Двоичное дерево называется идеально
уравновешенным если для любого его узла
справедливо, что в любом левом и правом
поддереве количество элементов
различается не более, чем на 1. Поиск в
бинарном дереве выполняется за
логарифмическое время зависящее от
числа элементов множества <= глубине
дерева и приблизительно равное log2n.
Вставка и удаление выполняется крайне
сложно, т.к. надо уравновешивать дерево.
Если же используется не сбалансированное
дерево, то добавление упорядоченного
множества элементов (будет нарастать
только одна ветка) приведет к тому , что
поиск будет выполняться за время n. Но
если элементы поступают случайно, то
такого не произойдет. Была доказана
следующая теорема:
Структура
бинарного дерева изображена на рисунке,
при этом дерево формируется так, чтобы
для любого его узла X2<X1<X3.
Двоичное дерево называется идеально
уравновешенным если для любого его узла
справедливо, что в любом левом и правом
поддереве количество элементов
различается не более, чем на 1. Поиск в
бинарном дереве выполняется за
логарифмическое время зависящее от
числа элементов множества <= глубине
дерева и приблизительно равное log2n.
Вставка и удаление выполняется крайне
сложно, т.к. надо уравновешивать дерево.
Если же используется не сбалансированное
дерево, то добавление упорядоченного
множества элементов (будет нарастать
только одна ветка) приведет к тому , что
поиск будет выполняться за время n. Но
если элементы поступают случайно, то
такого не произойдет. Была доказана
следующая теорема:
Теорема: Если элементы, вставляемые в множество, имеют равномерное распределение, то среднее время поиска больше времени поиска в идеально сбалансированном дереве не более, чем на 39 процентов (оценка статистическая).
Определение(Адельсона-Вельского и Ландиса): Дерево называется сбалансированным, если
для любого узла глубина левого поддерева отличается от глубины правого не более, чем
на 1.
Теорема: Глубина сбалансированного дерева может быть больше глубины идеально
сбалансированного дерева не более, чем на 45 процентов (оценка в самом худшем случае).
Время поиска в сбалансированных деревьях логарифмично, так что это достаточно хорошая
структура для хранения множеств. Кроме этого балансировка такого дерева осуществляется
всего за 3-4 операции, что не приводит к заметным увеличениям времени при добавлении и
удалении элементов.
Кроме бинарных деревьев существуют "страничные" деревья (B-деревья). Подробнее о них
можно узнать из книги Вирта "Алгоритмы + структуры данных = программы".