

Миргородская 7сессия / Операционные системы / %D0%9E%D0%A1_%D0%A1%D0%93%D0%A2%D0%A3%20v5
.pdf#include <string.h> #include <unistd.h> #include <pthread.h> #include <semaphore.h>
const int THRNUM = 3, NCKL = 10, LINOUT = 5, BUFLEN = THRNUM * NCKL + 1;
inline void workfun( int n ) {
for( long i = 0; i < n; i++ ) double f = sqrt( 1. + sqrt( (double) rand() ) );
};
char buf[ BUFLEN ];
volatile unsigned ind = 0, nfin = 0; long nrep = 1000;
bool bmutex = false, bsemaphore = false;
static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; static sem_t semaphore, semfinal;
void *thrfunc( void *p ) { int t = (int)p;
if( t != 1 ) {
if( bmutex ) pthread_mutex_lock( &mutex ); if( bsemaphore ) sem_wait( &semaphore );
};
struct timespec tv; tv.tv_sec = 0;
tv.tv_nsec =(long)( 1e+6 ); sem_trywait( &semfinal ); nanosleep( &tv, &tv );
for( int i = 0; i < NCKL; i++ ) { buf[ ind++ ] = t + '0'; workfun( nrep );
};
if( t != 1 ) {
if( bmutex ) pthread_mutex_unlock( &mutex ); if( bsemaphore ) sem_post( &semaphore );
};
if( ++nfin == THRNUM ) sem_post( &semfinal );
};
int main( int argc, char *argv[] ) {
cout << "inverse test, QNX API, vers.1.05L" << endl; int c = 0;
while( ( c = getopt( argc, argv, "hmst:" ) ) != -1 )
131
switch( c ) { case 'h':
cout << "\t" << argv[ 0 ] << " [ h | { m | s } | t = value ]" << endl; exit( EXIT_SUCCESS );
case 'm': bmutex = true; break; case 's': bsemaphore = true; break; case 't':
nrep = 1;
for( int i = 0; i < atoi( optarg ); i++ ) nrep *= 10; break;
default: exit( EXIT_FAILURE );
};
sem_init( &semaphore, 0, 1 );
cout << "repeating number = " << nrep; // << ", debug level = " << ndebug; if( bmutex ) cout << ", lock on mutex";
if( bsemaphore ) cout << ", lock on semaphore"; cout << endl;
struct sched_param param; int polisy;
pthread_getschedparam( pthread_self(), &polisy, ¶m ); pthread_attr_t attr;
for( int i = 0; i < THRNUM; i++ ) { pthread_attr_init( &attr );
pthread_attr_setdetachstate( &attr, PTHREAD_CREATE_DETACHED ); pthread_attr_setinheritsched( &attr, PTHREAD_EXPLICIT_SCHED ); pthread_attr_setschedpolicy( &attr, SCHED_RR ); attr.param.sched_priority = param.sched_priority + i + 1; pthread_create( NULL, &attr, &thrfunc, (void*)i );
};
sem_init( &semfinal, 0, 0 ); sem_wait( &semfinal ); buf[ ind ] = '\0';
cout << buf << endl; exit( EXIT_SUCCESS );
};
Для дочернего потока может потребоваться установить иную по отно-
шению к родителю дисциплину (политику) диспетчеризации (SCHED_FIFO,
SCHED.RR, SCHED_SPORADIC) [17].
132
Fifo – не вытесняющая кооперативная (очередь-приоритет). Выполне-
ния потока не прерывается потоками равного приоритета, пока сам поток не передаст управление.
Round-robin – карусельная, вытесняющая многозадачность, режим квантования времени. Поток работает непрерывно только в течение опреде-
ленного кванта времени. После истечения кванта его вытесняет поток равно-
го приоритета.
Спорадическая – предназначена для установления лимита использо-
вания потоком процессора в течение определенного времени. Потоку зада-
ются параметры: нормальный N, низкий L приоритеты, начальный бюджет C,
период восстановления T, максимальное число пропусков восстановлений.
Когда поток готов, приоритет имеет значение N в течение С, после чего при-
оритет снижается до L, ограниченный временем Т.
Все политики диспетчеризации работают с потоками из одной очереди
(всего их для QNX 6.3 - 256), очереди потоков наивысшего из присутствую-
щих в системе приоритетов. Если в системе выполняется поток высокого приоритета, то ни один поток более низкого приоритета не получит управле-
ние до тех пор, пока поток высокого приоритета не будет переведен в блоки-
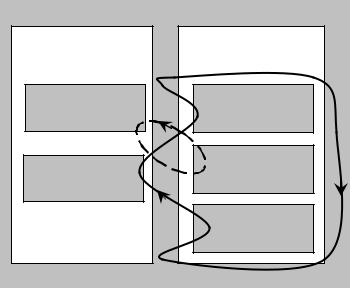
рованное состояние в ожидании некоторого события (рис. 50).
На рис. 50 представлены два процесса (процесс A с PID=671179 и про-
цесс В с PID=620004), каждый из которых создает внутри себя несколько по-
токов с диспечеризацией Round-robin, но с различными приоритетами (10 и 12). Жирной сплошной линией на рис.50 показан порядок, в котором потоки высокого приоритета (12) объединены в циклическую очередь диспетчериза-
ции. Эта активная очередь диспетчеризации (наивысшего приоритета). Пук-
нктирной линией показан порядок потоков в другой очереди (приоритета
10). До тех пор пока все потоки активной очереди (приоритет 12) не окажут-
ся в силу каких-либо обстоятельств в блокированном состоянии, ни один из потоков очереди приоритета 10 не получит ни единого кванта времени.
133
Prio |
Пр/П |
Пр/П |
Пр/П |
10 |
A/1 |
|
|
11 |
|
|
|
12 |
|
|
|
|
А) |
|
|
|
|
|
|
Prio |
Пр/П |
Пр/П |
Пр/П |
10 |
A/1 |
B/2 |
|
11 |
|
|
|
12 |
B/1 |
A/2 |
|
|
Б) |
|
|
|
|
|
|
Prio |
Пр/П |
Пр/П |
Пр/П |
10 |
A/1 |
B/2 |
|
11 |
|
|
|
12 |
B/3 |
A/2 |
B/1 |
Операционная система (RAM) |
||
Процесс А |
Процесс B |
|
Pid=671179 |
Pid=620004 |
|
Поток |
Поток |
|
tid=1, prio= 10 |
tid=1, prio= 12 |
|
Поток |
Поток |
|
tid=2, prio= 10 |
||
tid=2, prio= 12 |
||
|
||
|
Поток |
|
|
tid=3, prio= 12 |
|
В)
Рис. 50 Диспетчеризация процессов
Рассмотрим временные затраты на создание потока на примере про-
граммы p2-2.cc [17]:
//P2-2.cc
include <stdlib.h> #include <stdio.h> #include <inttypes.h> #include <iostream.h> #include <sys/neutrino.h> #include <pthread.h> #include <sys/syspage.h>
static double cycle2milisec ( uint64_t ccl ) { const static double s2m = 1.E+3;
const static uint64_t cps = SYSPAGE_ENTRY( qtime )->cycles_per_sec; //
частота процессора:
return (double)ccl * s2m / (double)cps;
};
void* threadfunc ( void* data ) { pthread_exit( NULL );
};
int main( int argc, char *argv[] ) { uint64_t t = ClockCycles(); pthread_t tid;
pthread_create( &tid, NULL, threadfunc, NULL ); pthread_join( tid, NULL );
t = ClockCycles() - t;
134

cout << "Thread time: " << cycle2milisec( t ) << " msec. [" << t << " cycles]" << endl;
exit( EXIT_SUCCESS );
};
Программа начинается с точки входа – функции main(). Главный поток,
реализуемый функцией main() имеет tid = 1. С помощью функции
ClockCycles() определяется в переменной t имеющей тип данных uint64_t
текущее колисество процессорных циклов, котрое необходимо для определения времни затрачиваемого на создание процесса. На рис.51 пока-
зано выполнение программы p2-2.cc в перспективе System Profiler.
Рис.51. Выполнение программы p2-2.cc в перспективе System Profiler
Функция pthread_create() создает дочерний поток c tid = 2,
реализуемый функцией threadfunc(). Дочерний поток сразу после запуска
135
завершает функцией pthread_exit( NULL ). Во время работы дочернего
потока, родительский ожидает его завершения на функции pthread_join(). Как
только робительский поток разблокируется в переменной t = ClockCycles() - t
определяется количество процессорных затраченных на порожденние потока.
Затем результаты выводятся на экран через поток и родительский поток
завершается функцией exit( EXIT_SUCCESS ).
На результаты этого теста значительно влияет приоритет, подкоторым
выполняется программа. Для запуска пограммы p2-2.cc из командной строки
может использоваться команда nice и сторока запуска будет выглядеть так
#nice –n-19 p2-2. При одиинаковых приоритетах программ p2-1.cc и p2-2.cc
создание потока выполняется в 20 раз быстрее чем процесса
Теперь рассмотрим скрость переключения потоков на примере
программы p5t.cc [17]. Она организована аналогично программе p5.cc. На
рис.52 показано выполнение программы p5t.cc в перспективе System Profiler.
// P5t.cc
#include <stdlib.h> #include <stdio.h> #include <inttypes.h> #include <iostream.h> #include <unistd.h> #include <pthread.h> #include <errno.h> #include <sys/neutrino.h>
unsigned long N = 1000; // количество циклов static pthread_barrier_t bstart;
void* threadfunc ( void* data ) { pthread_barrier_wait( &bstart ); uint64_t t = ClockCycles();
for( unsigned long i = 0; i < N; i++ ) sched_yield();
t = ClockCycles() - t; // задает количество потоков, которое будет создано delay( 100 );
cout << pthread_self() << "\t: cycles - " << t << "; on sched - " << ( t / N ) / 2 << endl;
return NULL;
};
136
int main( int argc, char *argv[] ) { int opt, val;
while ( ( opt = getopt( argc, argv, "n:" ) ) != -1 ) { switch( opt ) {
case 'n' :
if( sscanf( optarg, "%i", &val ) != 1 )
cout << "parse command line error" << endl, exit( EXIT_FAILURE ); if( val > 0 ) N = val;
break; default :
cout << "parse command line failed" << endl, exit( EXIT_FAILURE ); break;
}
};
const int T = 2; pthread_t tid[ T ];
if( pthread_barrier_init( &bstart, NULL, T ) != EOK ) cout << "barrier init error", exit( EXIT_FAILURE ); for( int i = 0; i < T; i++ )
if( pthread_create( tid + i, NULL, threadfunc, NULL ) != EOK ) cout << "thread create error", exit( EXIT_FAILURE );
for( int i = 0; i < T; i++ ) pthread_join( tid[ i ], NULL ); exit( EXIT_SUCCESS );
};
Программа начинается с точки входа – функции main(). Если при за-
пуске программы в командной строке задано количество повторений цикла с
ключом n, то с помощью функций getopt() и sscanf() оно преобразуется в
новое значение переменной n. Затем функцией pthread_barrier_init( &bstart,
NULL, T ) создается барьер для синхронизации запуска двух дочерних пото-
ков. Главный поток создает два дочерних потока функцией pthread_create()
с tid=2 и tid=3, а затем ожидает их завершения на функции pthread_join().
Каждый дочерний поток при запуске блокируется на функции
pthread_barrier_wait( &bstart ). Когда последний дочерний поток создан, то
все блокированные на барьере &bstart потоки одновременно разблокируются
и становятся готовыми к выполнению. В переменных t (своей для каждого
дочернего потока) имеющей тип данных uint64_t функцией ClockCycles()
определяется текущее колисество процессорных циклов.
137
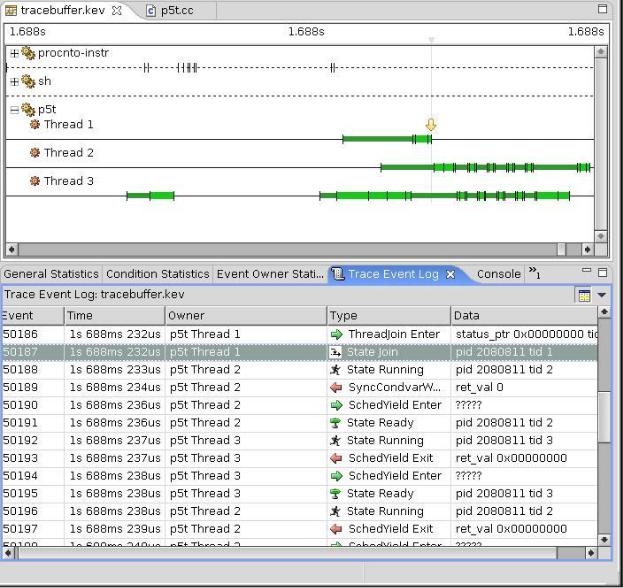
Рис.52. Выполнение программы p5t.cc в перспективе System Profiler
Затем в каждом из дочерних потоков запускается n раз for-цикл, где выполняется единственная функция sched_yield(). Она переводит вызвавший ее поток из состояния выполнения в состяние готовности к выполнению
(хотя квант времени выделенный для работы этого потока еще не истек) и
запускает передиспетчеризацию потоков.
После завершения цила каждый поток определяет в своей переменной t = ClockCycles() - t количество процессорных затраченных на выполнение циклов. Делает задержку на 0,2 секунды и выводит на экран через поток вывода cout результаты своей работы.
138
Это симметричный тест для потоков аналогичный тому, как это дела-
лось для переключения контекстов процессов. Результаты отмечают очень высокую устойчивость при изменении объему вычислений на 4 порядка, од-
нако по своим величинам значения для потоков почти в 2 раза меньше, чем для процессов.
Завершение потока
При завершении потока различают два случая:
1)«естественное» завершение выполнения потока из кода самого потока;
2)завершение потока извне, из кода другого потока или по сигналу.
Для этого действия, в отличии от «естественного » завершения, используется термин – отмена.
Завершение потока происходит при достижении функцией потока сво-
его естественного конца и выполнения оператора return или выполнения по-
током вызова void pthread_exit(). Если поток принадлежит к категории ожи-
даемых, он может возвратить результат своей работы другому потоку, ожи-
дающему его завершения на вызове pthread_join(). Если поток отсоединен-
ный, то по его завершении все системные ресурсы, задействованные пото-
ком, освобождаются немедленно. Для последнего потока процесса вызов void pthread_exit() эквивалентен exit().
Отмена потока значительно более сложная задача. Это связанно с тем,
что необходимо корректно завершить все системные объекты (файловые дискрипторы, блоки динамической памяти, примитивы синхронизации и др.),
связанные с отменяемым потоком.
Для отмены (принудительного завершения) потока используется вызов int pthread_cancel(pthread_t thread);
где в качестве параметра указывается TID отменяемого потока. Однако этот вызов не отменяет поток, а только запрашивает завершение потока. Поток может отказаться выполнять любые отмены, вызвав из своей функции пото-
ка: int pthread_setcancelstate(int state, int* oldstate).
Завершение потока состоит из следующих этапов:
139
выполняются все процедуры завершения, занесенные ранее в стек за-
вершения вызовами pthread-cleanup_push();
выполняются деструкторы собственных данных потока;
отменяемый поток завершается;
процесс отмены – асинхронный с точки зрения вызывающего pthread_cancel() кода, поэтому вызывающий отмену поток должен до-
ждаться завершения потока на вызове pthread_join().
3.5. Управление потоками и процессами в QNX6
Микроядро QNX обеспечивает управление памятью и защиту адресно-
го пространства 1 процесса от других с помощью блока управления памятью.
С помощью них ос может завершить процесс сразу после возникновения ошибки доступа к памяти. Ос узнает о месте ошибочной инструкции и может запустить символьный отладчик, начиная с этой инструкции микроядро де-
лит физическую память на страницы размером 4 кб. Процессор использует набор из множества таблиц страниц, хранящихся в системной памяти. Эти таблицы служат для описания того, как виртуальный адрес выделяется про-
цессором для доступа к физизической памяти [19]. Во время выполнения по-
тока в таблице страниц заносятся данные о том, как адреса памяти, исполь-
зующиеся потоком, отображаются в физической памяти системы. Для сохра-
нения высокой производительности процессор выполняет кэширование час-
то используемых сегментов памяти. В QNX предусмотрено управление на уровне таблиц страниц. С ними связаны биты, определяющие атрибуты каж-
дой страницы. Страницы могут лишь различаться по степени доступа. Па-
мять выполняет процесс со страницы «только чтение» для кода и «чтение и запись» для данных. Когда применяется операция приостановки одного, и
выполнения другого приоритетов, она указывает блок управления памятью применить для потока другой набор таблиц страниц. Если меняется контекст
140