


Storage and transmission of spatial sound signals 637
component, along with the time-varying directional parameter, can be transmitted as audio stream. Ambient components mainly contain nondirectional information. Because the spatial resolution of human hearing to ambient components is relatively low, they can be handled by lower-order Ambisonics to improve the coding efficiency. However, because the Ambisonic representation or signals of ambient components may be highly correlated, the spatial unmasking of quantization noise may occur after decoding. Similar to the MS stereo coding in Section 13.4.5, the Ambisonic representation is decorrelated by transforming it to a different spatial domain for perceptual coding to avoid this problem.
The decoding of Ambisonic signals is an inverse course of coding. Based on Ambisonic data from the USAC 3D core decoding, decorrelated ambient components are first transformed to the HOA representation. The HOA representation of predominant components is also resynthesized from the coded data. The HOA representations of predominant and ambient components are then combined to form HOA-independent signals. According to the practical loudspeaker configuration, HOA-independent signals are linearly decoded into loudspeaker signals. A matrix that preserves the constant power (energy) is used in decoding.
4.SAOC-3D decoding and rendering (Murtaza et al., 2015)
MPEG-H 3D Audio also supports parametrically coded channel signals and audio objects, e.g., an extended spatial audio object coding called SAOC-3D. In comparison with the original SAOC in Section 13.5.5, the SAOC-3D is extended in the following aspects.
•SAOC-3D in principle supports an arbitrary number of downmixing channels, while original SAOC supports a two-channel downmixing at most.
•SAOC-3D supports the direct decoding/rendering to multichannel outputs for arbitrary loudspeaker configurations, including the enhanced decorrelation to output signals. SAOC only support by using a MPEG surround as a rendering engine.
•Some SAOC tools, such as residual coding, are unnecessary and thus omitted in MPEG-H 3D Audio.
5.Binaural rendering
The mixed outputs in Figure 13.23 are for loudspeaker reproduction. They can be converted to signals for headphone presentation by binaural synthesis in Section 11.9.1. That is, the signal intended for each loudspeaker is convolved with a pair of binaural room impulse responses and then mixed to simulate transmission from loudspeakers to two ears in a listening room. Binaural rendering is vital in mobile devices.
6.Loudness and dynamic range control
7.Some loudness normalization and dynamic range information are embedded into the MPEG-H 3D Audio bit stream for loudness and dynamic range control in the decoder.
Subjective experiments indicated that MPEG-H 3D Audio exhibits an excellent quality at a bit rate of 1.2 Mbit/s or 512 kbit/s and shows good quality at a bit rate of 256 kbit/s. MPEG-H 3D Audio with a lower bit rate is being developed.
13.6 DOLBY SERIES OF CODING TECHNIQUES
Since the 1980s, Dolby Laboratories has developed a series of digital audio compression and coding techniques. These techniques have been widely used. However, the details of some of these techniques have not been published. This section outlines the basic principle of these techniques that have been published.
638 Spatial Sound
13.6.1 Dolby digital coding technique
The Dolby AC-1 developed in the early time is a stereophonic coding technique. It uses adaptive delta modulation (ADM) and combines with analog compounding. It is not a perceptual coding technique. The Dolby AC-2 developed in the 1980s is a coding technique for stereophonic and multichannel sound. It is a perceptual coding technique that consists of four single-channel coders/decoders (Fielder and Robinson, 1995; Brandenburg and Bosi, 1997).
Dolby Digital (AC-3) is a multichannel audio coding technique introduced in 1991. It was originally intended for 35 mm film soundtrack in a commercial cinema and subsequently specified as the audio coding standard of HDTV in USA. It has also been used widely for audio coding in DVD-Video (Davis, 1993; Davis and Todd, 1994; Todd et al., 1994; ETSI TS 102 366 V1.4.1, 2017; ATSC standard Doc.A52, 2012). Dolby Digital supports the sampling frequencies of 32, 44.1, and 48 kHz. It allows 5.1-channel coding (and mono, stereophonic, and threeand four-channel coding) with a bit rate ranging from 32 kbit/s to 640 kbit/s. A typical bit rate for 5.1-channel coding is 384 kbit/s. At this bit rate, Dolby Digital provides a good perceived audio quality (ITU-R Doc.10/51-E, 1995; Wüstenhagen et al., 1998; Gaston and Sanders, 2008).
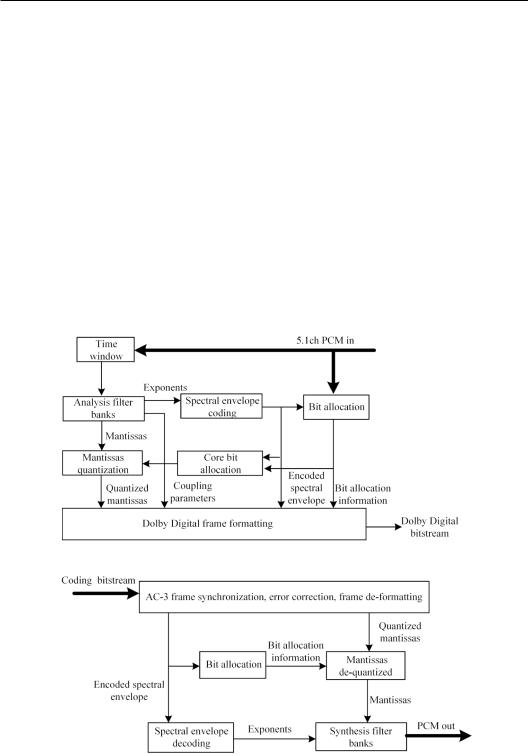
Figure 13.24 (a) illustrates the block diagram of Dolby Digital coding. After a time window, PCM input samples are transformed into time-frequency coefficients by analyzing filter
(a) Coding
(a) Decoding
Figure 13.24 Block diagram of Dolby Digital coding/decoding (a) Coding; (b) Decoding (adapted from ETSI TS 102 366 V1.4.1, 2017).

Storage and transmission of spatial sound signals 639
bands. Coefficients are normalized so that their maximal absolute magnitudes do not exceed 1. Each normalized coefficient is represented by a binary exponent and a mantissa and subsequently coded. For example, the exponent for a 16-bit binary number 0.0010 1100 0011 0001, which represents the number of “0” after the decimal point, is 2 in the decimal system or 10 in the binary system; and the mantissa is 10 1100 0011 0001 in the binary system. Binary exponents represent a rough variation in the spectral envelop and the binary mantissas represent the detail variations in the spectra. In a coder, the core bit allocation for mantissas is determined by a spectral envelope and a psychoacoustic model. The final stream involves the coded audio data, synchronous data, bitstream information, and additional data.
Figure 13.24 (b) shows the block diagram of Dolby Digital decoding. Decoding is an inverse course of coding. Various data are extracted. Mantissas are de-quantized according to bit allocation information. Spectral coefficients are reconstructed from exponents and mantissas from which PCM signals are restored using synthesis filter bands.
Some technical details of Dolby Digital coding/decoding are outlined as follows:
1.Analysis filter bands
Analysis filter bands are implemented by MDCT. The size of MDCT determines the time-frequency resolution. Dolby Digital dynamically chooses the size of MDCT. The PCM input is underground 8 kHz high-pass filters, and high-frequency energy is estimated. Stationary and transient signals are detected by comparing the resultant highfrequency energy with a pre-determined threshold.
Stationary signals require a higher-frequency resolution; therefore, MDCT with a long window (512 samples) is used. Each PCM block is overlapped by 50% with its two neighbors to avoid theartifacts caused by the abrupt transition between the border of two adjacent blocks; that is, 512 audio samples for MDCT are constructed by taking 256 samples from the previous block and 256 samples from the current block. The 512-point MDCT yields 256 spectral coefficients because of the odd symmetric relation in Equation (13.4.7). A Kaiser–Bessel window is used to improve the frequency selectivity and reduce the influence of the block border. At a sampling frequency of 48 kHz, the frequency and time resolutions of MDCT with a long window are 187.5 Hz and 5.33 ms. Transient signals require a high time resolution; therefore, MDCT with a short window (256 samples) is used. Each PCM block is also overlapped by 50% with its two neighbors. The 256-point MDCT yields 128 spectral coefficients. At a sampling frequency of 48 kHz, the frequency and time resolutions of MDCT with a short window are 375 Hz and 2.67 ms.
2.Exponent coding strategy
The exponents of spectral coefficients represent the rough variation in spectra. Dolby Digital coding allows a range of exponent values from 0 to 24 (in the decimal system). Spectral coefficients with an exponent value more than 24 (or the corresponding spectral coefficients less than 2−24) are set to 24. A differential coding is used to code the exponent within a block. The first exponent of a full-bandwidth channel (or lowfrequency effect, LFE channel) is coded with a 4-bit absolute value, corresponding to a variation from 0 to 15. Successive exponents at the ascending frequency are differentially coded and represented by one of five possible values ±2, ±1, and 0 corresponding to ±12, ±6, and 0 dB variation in magnitude, respectively. Differential exponents are combined into groups in the block. According to the bit rate and required frequency
resolution, grouping is formed by one of three exponent coding strategies, namely, D15, D25, and D45 modes, where the index “5” denotes five quantization levels of differential exponents, and index “1,” “2,” or “3” denotes the number of spectral coefficients that
640 Spatial Sound
share the same differential exponent. For example, in the D15 mode, three spectral coefficients are combined into a group, each spectral coefficient requires a differential exponent, and each differential exponent can take one of the five possible values. Therefore, there are 5 × 5 × 5 = 125 variations in differential exponents in D15 strategy. In this case, 7 bits is needed to code these variations, or 2.33 bit is required to code a differential exponent. Similar, in D25 and D45strategies, 2.17 and 0.58 bits are respectively needed to a differential exponent. The bit rate and frequency resolution descend in the order of D15, D25, and D45. The Dolby Digital coder chooses an optimal exponent coding strategy for each audio block. For stationary signals, a set of differential exponents can be shared by six MDCT blocks at most.
3.Mantissa quantization and adaptive bit allocation
As stated, Dolby Digital uses a spectral envelop and a psychoacoustic model to determine the core bit allocation for mantissa coding. In contrast to other coding methods (such as MPEG-1 layers I/II), Dolby Digital coder employs a forward-backward- adaptive psychoacoustic model. The decoder also includes a core backward-adaptive model. Core bit allocation uses a psychoacoustic model based on certain assumptions on the masking properties of signals. Some parameters of the model are also transmitted by the data stream. Therefore, the actual psychoacoustic model in a decoder can be adjusted by the coder. The coder can perform an ideal bit allocation based on a complicated but accurate psychoacoustic model and compares the results with the core bit allocation. If core bit allocation can better match the ideal bit allocation by changing some parameters, the coder does so and finishes the bit allocation. Otherwise, the coder sends some information to the decoder.
4.Channel coupling and re-matrixing
At a very low bit rate, the aforementioned compression and coding algorithms may not satisfy the bit rate requirement. In this case, spectral coefficients at high frequencies are combined into a single coupling channel to transmission. The coupling channel is formed by a vector summation of the spectral coefficients from all channels in coupling. This process is an extension of intensity stereo coding in Section 13.4.5. Channel coupling is based on the psychoacoustic principles that low-frequency ITD dominates lateral localization; at a high frequency, only the energy envelop contributes to localization. Dolby Digital decomposes signals into 18 subband components and applies the channel coupling above some subbands. Similar to original channels, spectral coefficients in the coupling channel are represented by binary exponents and a mantissa and coded. The coder calculates the powers of original signals and coupled signal. The resultant power ratio between the original signal and the coupled signal is evaluated for each input channel and each subband and transmitted as side information parameters. The decoder distributes the coupling channel signal to the output channels according to the side information parameters.
In re-matrixing, MS coding for a pair of channels with high correlation is used. It is applied to stereophonic signal coding. Its principle is outlined in Section 13.4.5.
In addition to the aforementioned technical details, Dolby Digital possesses some user features.
1.Loudness control
The level of dialog varies in different programs. Switching between different programs directly causes a variation in perceived loudness. Dolby Digital stream includes a code for dialog level normalization, which enables users to set the gain in reproduction according to the required level.