


634 Spatial Sound
SAOC possesses a high coding efficiency. MPS and SAOC allow for a 5.1-channel signal coding at a low bit rate of 48 kbit/s. SAOC enables the independent manipulation of the gain, equalization, and effect of each object. Because its coding and transmission are independent from reproduction, SAOC is appropriate for different reproduction manners (different numbers and configurations of loudspeakers or headphones). SAOC is applicable to teleconferences, personalized music remixed in interactive reproduction, and games.
As stated in Section 13.4.1, general audio coding techniques are different from speech coding techniques. They were developed separately. Audio compression and coding are realized by removing the physical and perceptual redundancy in signals. Speech coding is usually based on the time-varying filter (linear prediction) model of the human vocal system. MPEG specified the standard of MPEG-D Unified Speech and Audio coding (USAC) [ISO/IEC 23003-1 (2012); Neuendorf et al., 2013] to adapt to the applications of digital radio, streaming multimedia, audio book, mobile devices. The USAC combines the enhanced HE-AAC v2 audio coding technique and speech coding technique AMR-WB+ into a unified system. According to the signal component, USAC flawlessly transits between two coding modes. HE-AAC v2 is improved in many aspects, including a time-warped MDCT, additional 50% window lengths of 512 and 1,024 samples (block lengths of 256 and 512 samples) for MDCT with 50% overlap, enhanced SBR bandwidth extension, unified stereo coding. USAC distinguishes from MPS in the following aspects:
1.In addition to interchannel level difference and interchannel correlation, interchannel phase difference is added as the side information of the USAC.
2.In contrast to MPS in which residual signals are coded independently from the downmixing signals, the USAC couples the coding of downmixing and residual signals closely to improve the transmission quality.
3.At higher bit rates, because the core coder can discretely handle a wider bandwidth and code multiple channels, the tools of SBR and parametric coding can be not used. In this case, complex prediction stereo coding is used to improve the efficiency of stereo coding.
The USAC can operate at a bit rate as low as 8 kbit/s for mono signal. Within the bit rate ranging from 8 kbit/s for mono to 64 kbit/s for stereophonic sound, the quality of the USAC exceeds that of HE-AAC v2.
13.5.6 MPEG-H 3D audio
Multichannel spatial surround sound with height in Chapter 6 is next-generation spatial sound technique and system. Various multichannel spatial surround sound systems have been proposed. These systems differ in performance and complexity. The prospect of these systems depends on their acceptability by consumers. The diversity of systems and formats causes serious problems of compatibility in program making, coding, and reproduction. Therefore, the standard for multichannel spatial sound should be developed.
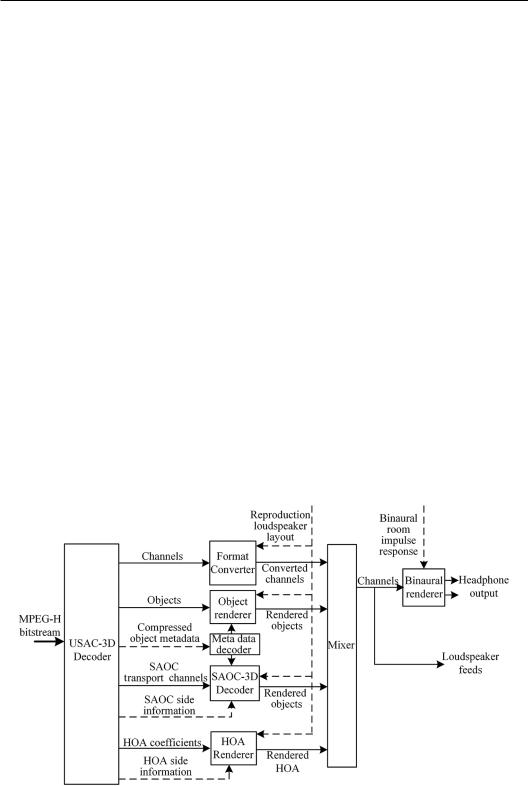
MPEG-H 3D Audio is a coding technique and standard for new-generation spatial sounds. It has the advantages of high flexibility, quality, and efficiency [ISO/IEC 23008-3 (2015); Herre et al., 2014, 2015]. It was called for proposal in 2013 and published in 2015. The MPEG-H 3D Audio coding supports channel-based, objected-based, and higher-order Ambisonic signal inputs. After decoding is completed, it supports various reproduction methods, such as 2-channel, 5.1-channel to 22.2-channel, or even more channel reproduction. It also supports headphone presentation. The reproduction methods are basically independent from the input format, which avoids the problem of compatibility among different spatial sound systems. Therefore, MPEG-H 3D Audio is a universal standard that unites different

636 Spatial Sound
However, the configurations of loudspeakers are diversiform or even nonstandard. Format converter aims to convert a set of channel-based signals for reproduction with practical loudspeaker configuration, especially to convert the signals for reproduction with a larger number of channels (such as 22.2-channel) to signals for reproduction with a smaller number of channels (such as 5.1-channel). The principle is similar to that of downmixing in Section 8.2. To ensure the reproduction quality, MPEG-H 3D Audio generates optimized downmixing matrix automatically. It supports optionally transmitted downmixing matrix to preserve the artistic contents of original signals. In addition, it uses equalization filters to preserve the timbre and uses advanced active downmixing algorithm to avoid downmixing artifacts.
The format conversion module involves two parts: rule-based initialization and active downmix algorithm. In a decoder, rule-based initialization derives the optimized downmixing matrix that converts channel-based inputs to the signals of loudspeakers in practical configuration. Derivation is implemented by iteration according to a set of tuned mapping rules for each input channel. Each rule specifies rendering of one input channel to one or more output channels. When an input channel is just consistent with an output channel (loudspeaker), the input is mapped to that output channel to avoid using the phantom source method.
In Section 8.2, for multichannel-correlated inputs with interchannel time difference, or for inputs derived from different filtered versions of the same signals, downmixing directly may lead to comb-filtering and thus timbre coloration. An active downmixing algorithm analyzes the correlation between input signals and aligns the phases if necessary to address this problem. Frequency-dependent normalization is applied to the gain of downmixing to preserve the overall power spectra of signals after downmixing. Moreover, adaptive downmixing algorithm should not alter the uncorrelated input signals.
2.Object-based rendering
USAC-3D core decoding yields object signals and object metadata. In addition to the spatial positions of objects (virtual sources), metadata of other characteristics of objects are included (Fug et al., 2014). Given the configuration of loudspeakers, the decoder feeds object signals to loudspeakers according to certain panning/mixing rules. Time-varying position data describe the spatial trajectory (or parameter equation) of a virtual source. Therefore, time-varying panning enables the simulation of a moving virtual source. The VBAP in Section 6.3 is used in MPEG-H 3D Audio for virtual source rendering. The three active loudspeakers in a spherical triangle are chosen according to the object metadata and practical loudspeaker configuration, and the gains of loudspeaker signals are calculated. However, most practical configurations lack loudspeakers below the horizontal plane. In these cases, imaginary (virtual) loudspeakers are needed for the VBAP.
3.Higher-order Ambisonics
In Chapter 9, the independent signals of higher-order Ambisonics (HOA), which are the time-varying components or coefficients of the spatial harmonic decomposition of a sound field, represent the temporal and spatial information of sound field. In reproduction, independent signals are linearly decoded to loudspeaker signals. The linearly decoded matrix depends on the configuration of loudspeakers. To improve the performance of coding, MPEG-H 3D Audio does not directly transmit the independent signals of Ambisonics. Instead, it applies a two-stage coding process to HOA data, e.g., spatial coding of components and multichannel perceptual coding.
The independent signals of HOA are decomposed into predominant and ambient components. Predominant components, which include directional sounds, can be coded as a set of plane wave incidence from certain directions. Therefore, each predominant