

ПЕРЕДАЧА
СООБЩЕНИЙ
Системы передачи сообщений имеют массу сложных проблем разработки, которых не возникает при использовании семафоров или мониторов, особенно если взаимодействующие процессы проходят на различных машинах, связанных между собой по сети.
К примеру, сообщение может быть утрачено при передаче по сети. Чтобы застраховаться от утраты сообщений, отправитель и получатель должны договориться о том, что как только сообщение будет получено, получатель должен отправить в ответ специальное подтверждение.
Если по истечении определенного интервала времени отправитель не получит подтверждение, он отправляет сообщение повторно.

РЕШЕНИЕ ЗАДАЧИ С ПОМОЩЬЮ ПЕРЕДАЧИ СООБЩЕНИЙ
Будем исходить из предположения, что все сообщения имеют один и тот же размер и что переданные, но еще не полученные сообщения буферизуются автоматически средствами операционной системы.
В этом решении всего используется N сообщений, что аналогично N местам в буфере, организованном в общей памяти.
Потребитель начинает с того, что посылает N пустых сообщений производителю. Как только у производителя появится запись для передачи потребителю, он берет пустое сообщение и отправляет его назад в заполненном виде.
При этом общее количество сообщений в системе остается постоянным, поэтому они могут быть сохранены в заданном, заранее известном объеме памяти.

РЕШЕНИЕ ЗАДАЧИ С ПОМОЩЬЮ ПЕРЕДАЧИ СООБЩЕНИЙ
#define N 100 |
/* количество мест в буфере */ |
void producer(void) |
|
{ |
|
int item; |
|
message m; |
/* буфер сообщений */ |
while (TRUE) { |
|
item = produce_item( ); |
/* генерация информации для помещения в буфер |
*/ |
|
receive(consumer, &m); |
/* ожидание поступления пустого сообщения */ |
build_message(&m, item); |
/* создание сообщения на отправку */ |
send(consumer, &m); |
/* отправка записи потребителю */ |
}
}
void consumer(void)
{
int item, i; message m;
for (i = 0; i < N; i++) send(producer, &m); /* отправка N пустых сообщений */
while (TRUE) { |
|
receive(producer, &m); |
/* получение сообщения с записью */ |
item = extract_item(&m); |
/* извлечение записи из сообщения */ |
send(producer, &m); |
/* возвращение пустого ответа */ |
consume_item(item); |
/* обработка записи */ |
} |
|
} |
|

РЕШЕНИЕ ЗАДАЧИ С ПОМОЩЬЮ ПЕРЕДАЧИ СООБЩЕНИЙ
Если производитель работает быстрее потребителя, все сообщения в конце концов становятся заполненными, ожидая потребителя; производитель должен будет заблокироваться, ожидая возвращения пустого сообщения.
Если потребитель работает быстрее, то получается обратный эффект: все сообщения опустошатся, ожидая, пока производитель их заполнит, и потребитель заблокируется в ожидании заполненного сообщения.

БАРЬЕРЫ
Предназначены для групп процессов, в отличие от задачи производителя-потребителя, в которой задействованы всего два процесса.
Некоторые приложения разбиты на фазы и следуют правилу, согласно которому ни один из процессов не может перейти к следующей фазе, пока все процессы не будут готовы перейти к следующей фазе. Добиться выполнения этого правила можно с помощью барьеров, поставленных в конце каждой фазы. Когда процесс достигает барьера, он блокируется до тех пор, пока этого барьера не достигнут все остальные процессы.
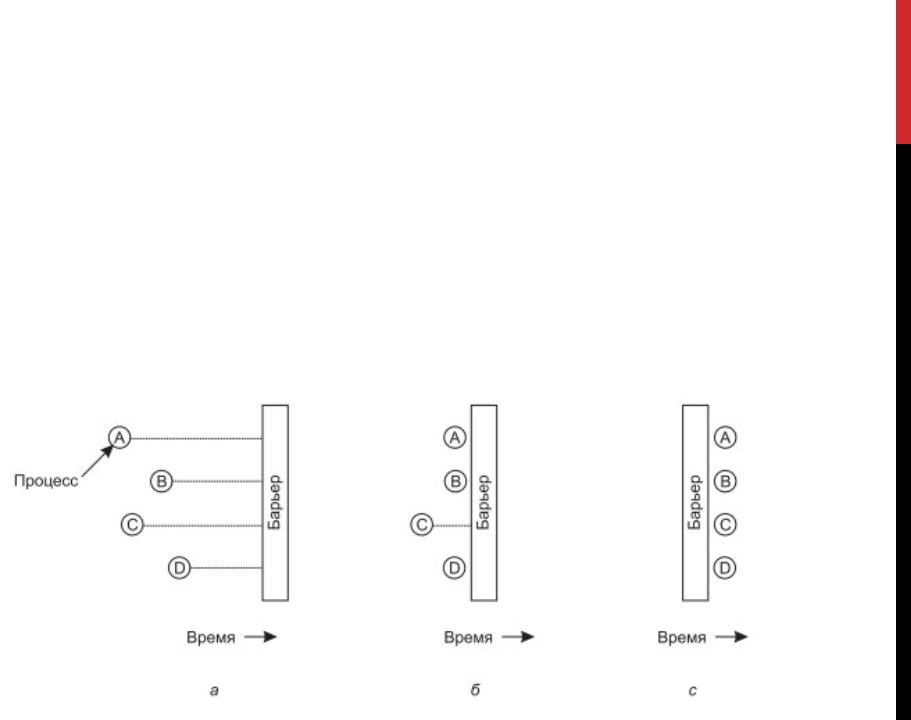
БАРЬЕРЫ
На рисунке а показаны четыре процесса, приближающихся к барьеру. Это означает, что они еще заняты вычислениями и не достигли завершения текущей фазы. Через некоторое время первый процесс заканчивает все вычисления, необходимые для завершения первой фазы работы. Он выполняет примитив barrier, вызывая обычно библиотечную процедуру. Затем этот процесс приостанавливается. Чуть позже первую фазу своей работы завершают второй и третий процессы, которые также выполняют примитив barrier. Эта ситуация показана на рисунке б. И наконец, как показано на рисунке в, когда последний процесс, C, достигает барьера, все процессы освобождаются.

БАРЬЕРЫ

РАБОТА БЕЗ БЛОКИРОВОК:
ЧТЕНИЕ — КОПИРОВАНИЕ — ОБНОВЛЕНИЕ
Самые быстрые блокировки — это отсутствие всяких блокировок.
Вопрос в том, можно ли разрешить одновременный доступ для чтения и записи к общим структурам данных без блокировки. Если говорить в общем смысле, то ответ, конечно же, будет отрицательный.
Представим себе, что процесс А сортирует числовой массив, в то же время процесс Б вычисляет среднее значение. Поскольку A перемещает значения по массиву, процессу Б некоторые значения могут попасться несколько раз, а некоторые не встретиться вообще. Результат может быть каким угодно, но, скорее всего, неправильным.

РАБОТА БЕЗ БЛОКИРОВОК: ЧТЕНИЕ
— КОПИРОВАНИЕ — ОБНОВЛЕНИЕ
В некоторых случаях можно позволить процессу, ведущему запись, обновить структуру данных, даже если ею пользуются другие процессы.
Здесь важно обеспечить, чтобы каждый считывающий процесс читал либо старую, либо новую версию данных, но не некую непонятную комбинацию из старой и новой версий.

ЧТЕНИЕ — КОПИРОВАНИЕ
— ОБНОВЛЕНИЕ
В операционной системе Linux поддержка RCU присутствует начиная с версии ядра 2.5. Основные функции RCU API:
•rcu_read_lock() — объявляет о входе потока-читателя в критическую секцию;
•rcu_read_unlock() — объявляет о выходе потока- читателя из критической секции;
•rcu_syncronize() — вызывая эту функцию, поток- писатель ожидает, пока все читатели, имевшие доступ к старой версии структуры данных, не прекратят чтение. После этого писатель может свободно удалить устаревшую копию.