

ИИиМО_ЛР4
.pdfРисунок 29 – Настройка набора данных (шаг 2)
Рисунок 30 – Настройка набора данных: результат (шаг 3)
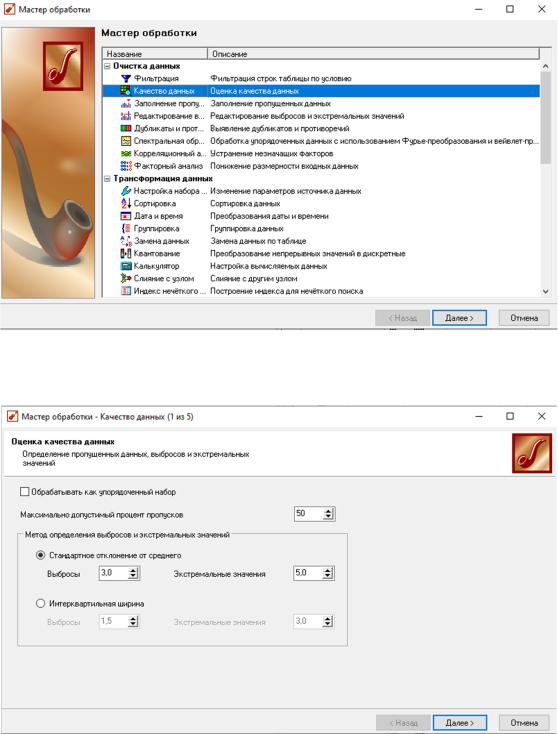
Теперь можно провести аудит данных, для чего применим узел Качество данных в мастер обработки (рис.31-34). Оставим все настройки узла по умолчанию.
Рисунок 31 – Оценка качества данных (шаг 1)
Рисунок 32 – Оценка качества данных (шаг 2)
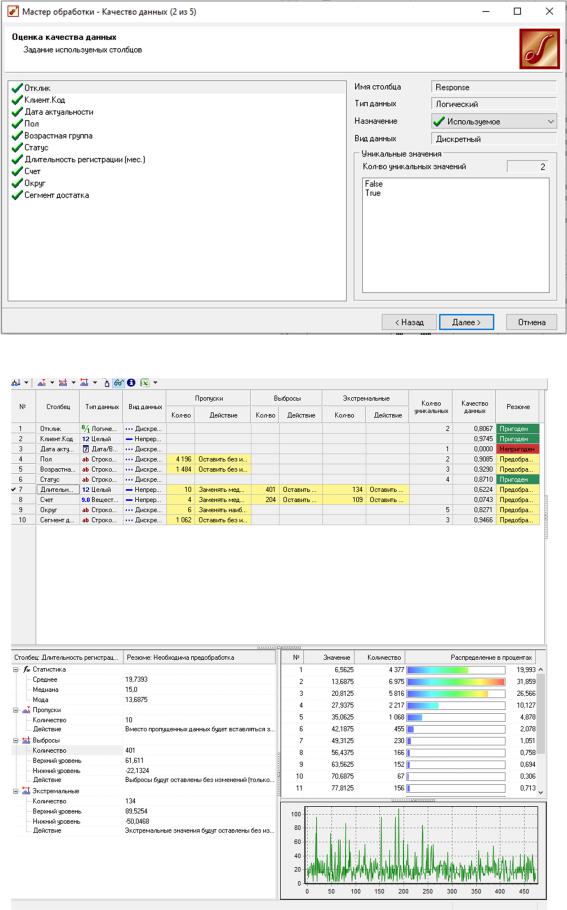
Рисунок 33 – Оценка качества данных (шаг 3)
Рисунок 34 – Оценка качества данных (шаг 4)
В оценке качества данных были обнаружены пропуски, выбросы (выходящие за границы 3-сигма) и экстремальные значения (выходящие за границы 5-сигма). Сначала проанализируем пропуски. В двух столбцах, Пол и Возрастная группа, имеют значительно количество пропущенных значений. Возможно, это связано с какими-то объективными причинами, например, до определенного момента времени возраст не указывался в анкетах клиентов. В любом случае большая доля пропуском не позволяет применять стандартные методы их восстановления. Поэтому оставим их без изменений. Как с ними бороться, будет рассмотрено на шаге Формирование конечных классов. Три других столбца - Длительность регистрации (мес.), Счет и Округ - имеют ничтожно малую долю пропусков от общего количества. Примем предлагаемый для них метод восстановления пропусков - заменять медианой ("Длительность регистрации" и "Счет") и заменять наиболее вероятным ("Округ"). Для того чтобы эти действия были произведены, после узла Качество данных добавим узел Заполнение пропусков, оставив включенным флаг Использовать данные узла оценки качества данных (рис. 35-37). Отобразим данные после заполнения пропусков в виде таблице (рис. 38). Добавлять в сценарий узел Редактирование выбросов не имеет смысла, так как они все остаются без изменений.
Рисунок 35 – Заполнение пропущенных данных (шаг 1)
Рисунок 36 – Заполнение пропущенных данных (шаг 2)
Рисунок 37 – Заполнение пропущенных данных (шаг 3)
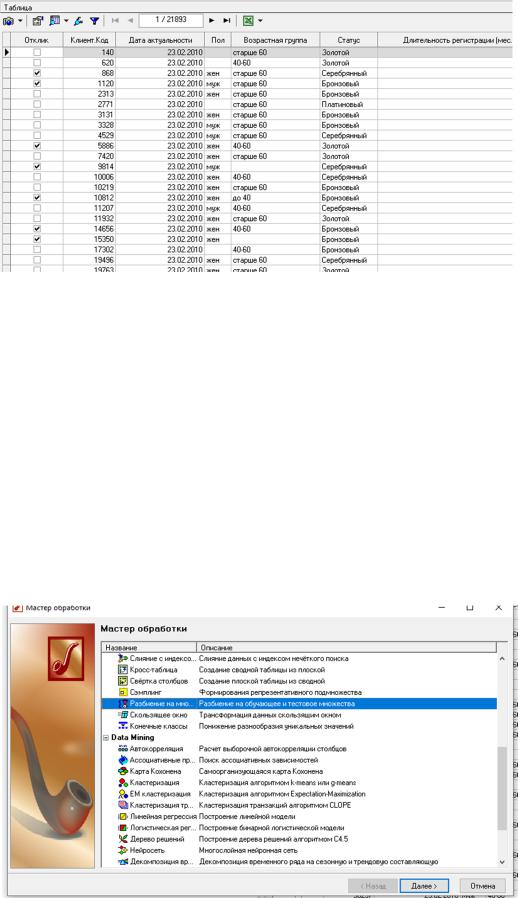
Рисунок 38 – Заполнение пропущенных данных: результаты Далее разбиваем исходное множество клиентов на две выборки -
обучающую и тестовую. Для этого используем узел Разбиение на множества (рис. 39). В самих узлах моделирования тоже присутствует шаг разбиения, но он нам не подходит, поскольку понадобится сложный сэмплинг - со стратификацией. Иными словами, требуется обеспечить одинаковую долю откликов в обеих выборках (рис.40). На следующем шаге укажем, по какому полю будем осуществлять стратификацию – Отклик (рис.41). В специальном визуализаторе можно оценить качество и успешность разбиения на множества путем сравнения с исходным набором (рис.42).
Рисунок 39 – Разбиение на множества (шаг 1)
Рисунок 40 – Разбиение на множества (шаг 2)
Рисунок 41– Разбиение на множества (шаг 3)
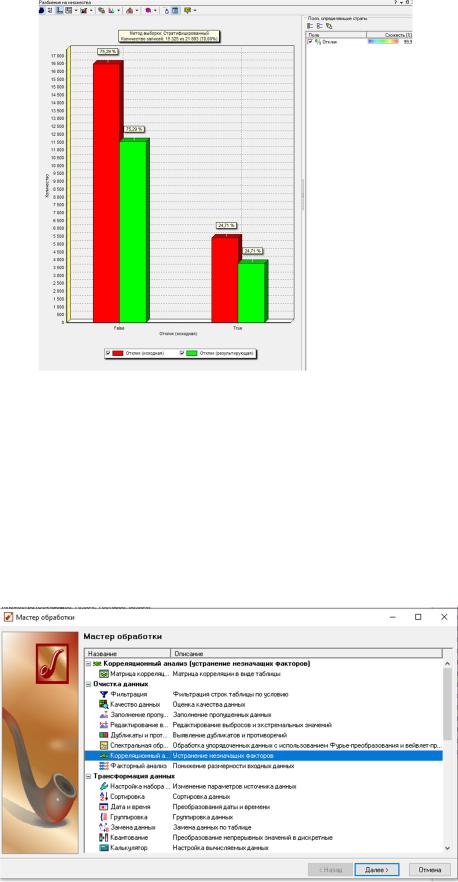
Рисунок 42 – Разбиение на множества (шаг 3)
В наборе данных присутствуют два непрерывных поля - Длительность регистрации (мес) и Счет, значит, можно провести корреляционный анализ для того, чтобы проверить гипотезу о наличии линейных связей между ними и выходным полем Отклик. Выберем узел Корреляционный анализ (рис. 4347) и назначим входные и выходное поле. Проанализируем результаты в визуализаторе (рис.47).
Рисунок 43 – Корреляционный анализ (шаг 1)
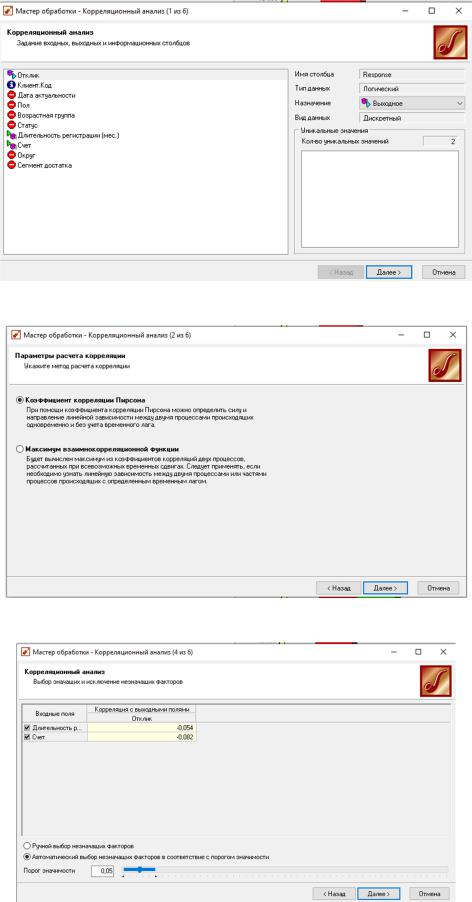
Рисунок 44 – Корреляционный анализ (шаг 2)
Рисунок 45 – Корреляционный анализ (шаг 3)
Рисунок 46 – Корреляционный анализ (шаг 4)
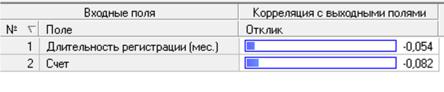
Рисунок 47 – Корреляционный анализ: результаты
По значениям коэффициента корреляции можно сделать вывод, что линейной связи нет.
Следующим шагом является – формирование конечных классов. Формирование конечных классов относится к техникам двумерного анализа, который, в отличие от одномерного, позволяет одновременно исследовать взаимоотношения двух переменных (входной и выходной - переменной отклика), и в той или иной форме проверять гипотезы о причинных связях между ними. С двумерным анализом связано понятие "classing" - сокращение числа разнообразных значений признака. Classing есть не что иное как сокращение числа разнообразных значений признака, которое обычно связывают с изменением интервала дискретизации значений. Задача заключается в уменьшении числа значений исходного набора данных за счет их объединения в пределах некоторого интервала с использованием информации о целевой переменной. В результате такого преобразования число значений признака должно уменьшиться без существенного ущерба для информативности данных. Во многих случаях дополнительным выигрышем от такой обработки является упрощение описания исследуемых объектов.
Двумерный анализ основан на количественной оценке предсказательной силы пременной - WoE-анализ и информационные индексы.
Формирование конечных классов (Fine&Coarse Classing) как процесс категоризации позволяет выявить наиболее общие тенденции в данных, построить устойчивые предиктивные модели бинарного отклика. Для