

ИИиМО_ЛР4
.pdfЛабораторная работа № 4
Методы классификации
Основная цель
Обучающийся должен получить следующие знания, умения и навыки: изучить понятие и методы классификации; научиться реализовывать метод классификации с помощью логистической регрессии, используя различные инструменты (например, ПП «Deductor Studio»).
Задание:
1.Реализовать бинарную классификацию с помощью логистической регрессии. Исходные данные должны иметь не менее 300 наблюдений,
зависимая переменная должна принимать бинарные значения (0 и 1), независимые данные могут быть как количественными, так и качественными. Проанализировать изменения в классификации в зависимости от способа разделения исходного множества на тестовое и обучающее и параметров метода, параметров отбора переменных в регрессионные модели, параметров построения регрессионной модели, параметров калибровки лог-регрессионной модели, параметров преобразования. Реализация метода в ПП «Deductor Studio» представлена в методических указаниях.
Пример реализации в R:
https://drive.google.com/file/d/1jnjI0jIIZCusXawQjpHNtoTr7ULsoUJ
J/view?usp=sharing
Пример реализации в Python представлен в файле logreg.py.
Данные можно найти в следующих источниках:
https://www.kaggle.com/datasets
http://www.gks.ru/
Если вы выполняете работу в ПП «Deductor Studio», тогда результатом выполнения задания являются проект в формате *.ded, исходный файл с данными, и отчет, содержащий следующую информацию: ход выполнения работы с описанием и скриншотами выполнения, результаты выполнения (интерпретация полученных результатов, выводы по анализу изменения классификации в зависимости от различных параметров.
Если вы выполняете работу с использованием R или Python, тогда результатом выполнения задания являются рабочие файлы реализации, исходный файл с данными, и отчет, содержащий следующую информацию: ход выполнения работы с описанием и скриншотами выполнения, результаты выполнения (интерпретация полученных результатов, выводы по анализу изменения классификации в зависимости от различных параметров.
В отчете необходимо указать ссылку на исходные данные.
Для успешной защиты лабораторной работы студенты должны предоставить проект (например, папка с рабочими файлами Deductor, исходные данные к модели в формате *.txt или *.csv) и отчет к нему, ответить на заданные вопросы преподавателя.
Требования к оформлению отчета:
Способ выполнения текста должен быть единым для всей работы. Шрифт
– Times New Roman, кегль 14, межстрочный интервал – 1,5, размеры полей: левое – 30 мм; правое – 10 мм, верхнее – 20 мм; нижнее – 20 мм. Сокращения слов в тексте допускаются только общепринятые.
Абзацный отступ (1,25) должен быть одинаковым во всей работе. Нумерация страниц основного текста должна быть сквозной. Номер страницы на титульном листе не указывается. Сам номер располагается внизу по центру страницы или справа.
Методические указания к выполнению
Для выполнения данного задания необходимо скачать программный продукт с сайта https://basegroup.ru/deductor/download. С методическими рекомендациями по работе в приложении (Руководство аналитика Deductor 5.3) можно ознакомиться на сайте https://basegroup.ru/deductor/manual/guide- analyst-530.
Классификация с помощью логистической регрессии
Решение задач предсказательной аналитики требует высокой квалификации от пользователя. Требуется хорошо владеть не только методами преобразования данных, но и знать аналитические алгоритмы.
Довольно много бизнес-задач сводятся к построению модели бинарного классификатора (будут просрочки по кредиту или нет, покинет клиент компанию или останется и т. д.). Популярным и хорошо изученным математическим инструментом для создания бинарных классификаторов является логистическая регрессии. Кроме того, данный инструмент позволяет получать вероятностные оценки наступления интересующего события и оценивать качество модели специальными метрикам - AUC, KS, Gini и другие.
Рассмотрим демо-пример Скоринг отклика (логистическая регрессия)
в ПП «Deductor Studio» (рис.19).
Рисунок 19 – Открытие демо-примера «Скоринг отклика (логистическая регрессия)
В данном примере демонстрируется популярная задача - скоринг отклика - оценка реакции потребителя на направление ему предложения. В качестве математического инструмента для моделирования выбрана логистическая регрессия.
Крупная розничная сеть начинает продвижение новой линии органической косметики. Руководство сети хочет определить, какие клиенты более склонны к приобретению продуктов новой линии. Сеть имеет программу поощрения постоянных клиентов, благодаря чему каждый постоянный клиент имеет скидочную карту. В качестве первоначального плана стимулирования покупателей розничная сеть провела несколько акций по распространению специальных купонов на приобретение органических продуктов, после чего собрала данные, в которых были зафиксированы покупки новой продукции. Требуется на основе этих данных спрогнозировать отклик для всей клиентской базы, чтобы минимизировать
ресурсы, связанные с рассылкой будущих персональных предложений клиентов, и делать это только тем клиентам, которым интересна новая продукция.
В итоге в распоряжение аналитику доступно 21893 записи. По какому принципу они были отобраны из всей базы рассылок, неизвестно. Однако имеется достоверный факт, что отклик на предложение составляет в среднем величину 3,7%.
Известно, что качество построенной модели во многом определяется полнотой проведенного аудита данных и их последующей предобработкой. Поэтому перед моделированием проанализируем качество данных.
Предобработка будет включать в себя следующие шаги:
импорт исходных данных;
аудит данных;
корреляционный анализ;
формирование конечных классов.
Далее производится непосредственно моделирование. Оно включает в себя: построение скоринговой карты отклика; оценка качества модели.
Исходные данные представлены в файле Клиенты.ddf. Это набор данных, с информацией о клиентах торговой сети и их реакцию на адресные предложения о приобретении новой линии продуктов: пол клиента; возрастная группа покупателя; статус скидочной карты (бронзовая, платиновая и др.); число месяцев с момента получения скидочной карты; общая сумма потраченных средств; географическая принадлежность; сегмент совокупного семейного дохода покупателя.
Результирующий признак – количество купленных товаров из группы новых товаров.
Перед началом работы необходимо выполнить импорт данных из этих файлов. Для этого вызовем мастер импорта на панели Сценарии.
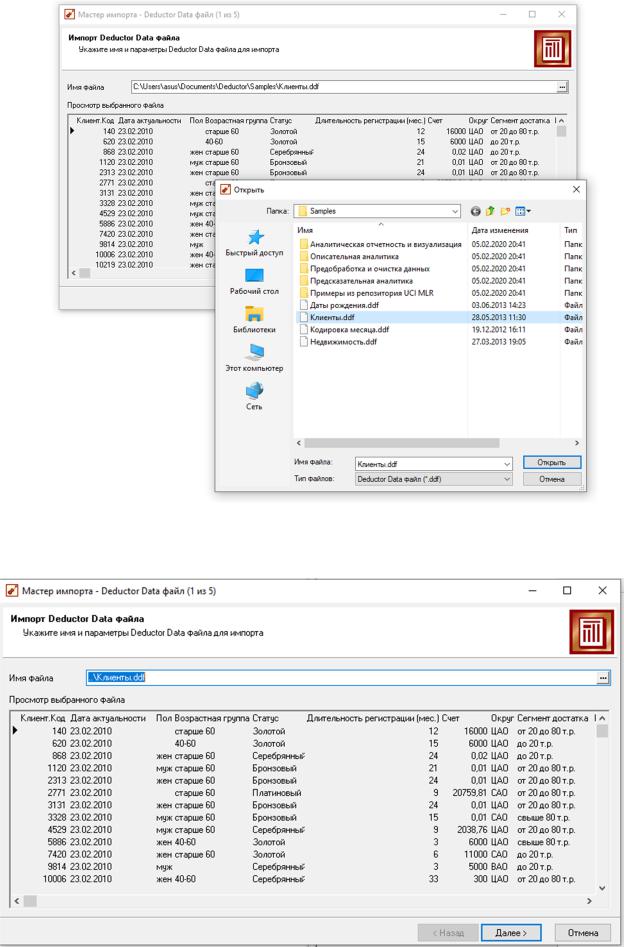
Рисунок 20 – Импорт данных (шаг1)
Рисунок 21 – Импорт данных (шаг 2)

Параметры для данных представлены в таблице 1.
Таблица 1 – Параметры данных
Наименование |
Тип данных |
Вид данных |
Назначение |
данных |
|
|
|
Клиент.Код |
Целый |
Непрерывный |
Информационное |
Дата актуальности |
Дата/Время |
Дискретный |
Информационное |
Пол |
Строковый |
Дискретный |
Информационное |
Возрастная группа |
Строковый |
Дискретный |
Информационное |
Статус |
Строковый |
Дискретный |
Информационное |
Длительность |
Целый |
Непрерывный |
Информационное |
регистрации (мес.) |
|
|
|
Счет |
Вещественный |
Непрерывный |
Информационное |
Округ |
Строковый |
Дискретный |
Информационное |
Сегмент достатка |
Строковый |
Дискретный |
Информационное |
Кол-во покупок |
Целый |
Непрерывный |
Информационное |
нового товара |
|
|
|
В результате выполнения данного узла становится доступен для дальнейшей обработки набор данных с клиентами.
Рисунок 22 – Результат импорта данных Первое, что требуется сделать — это сформировать целевую
переменную. Для прогнозирования вероятности отклика на событие

необходима бинарная переменная, а у нас имеется целочисленная Количество покупок нового товара (имя - SALES), то при помощи следующего выражения в калькуляторе мы сформируем требуемую бинарную переменную Отклик (рис. 23-27).
Рисунок 23 – Формирование целевой переменной (шаг 1)
Рисунок 24 – Формирование целевой переменной (шаг 2)
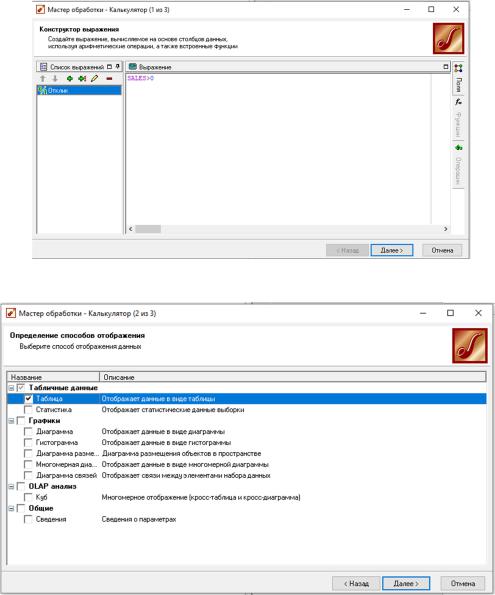
Рисунок 25 – Формирование целевой переменной (шаг 3)
Рисунок 26 – Формирование целевой переменной (шаг 4)
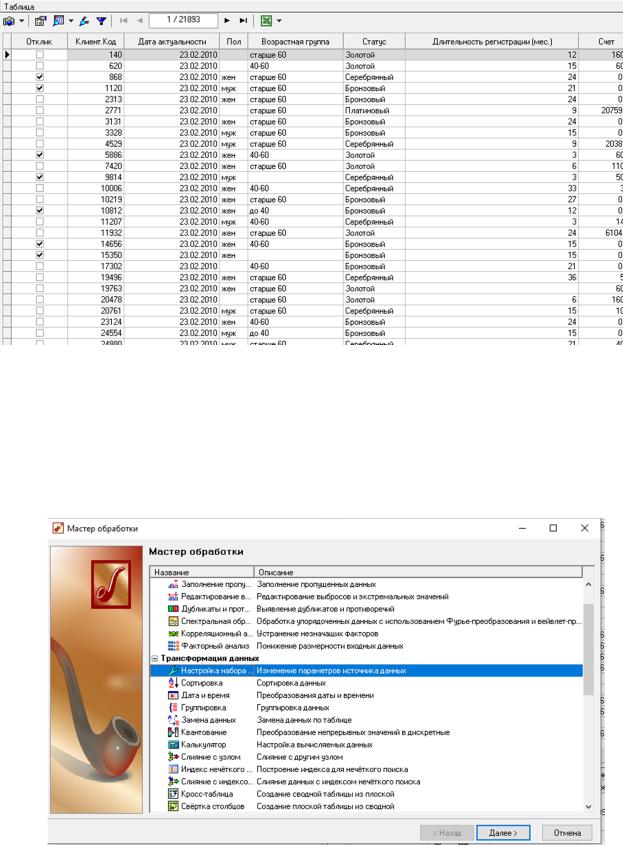
Рисунок 27 – Результат формирования целевой переменной Проведем настройку набора данных (рис.28-30). Изменить назначение
столбца Кол-во покупок нового товара на неиспользуемое. У переменной Отклик тип данных – логический, вид данных – дискретный, назначение – информационное. Отобразим данные в виде таблице.
Рисунок 28 – Настройка набора данных (шаг 1)