

По каждому пункту дать краткие экономико-статистические пояснения и выводы.
Глава 2. Прогнозирование экономической динамики
На основе трендов и моделей сезонной волны
Важным этапом, следующим за проведением анализа динамики показателей хозяйственной деятельности предприятия, является их прогнозирование (от греч. prognosis – знание наперед). Прогнозирование представляет собой вероятностное оценивание будущих значений изучаемых производственно-финансовых показателей предприятия и является главной предшествующей стадией их планирования.
Прогнозы классифицируются по различным признакам. Одна из возможных классификаций приведена на рис. 2.1.

Рис. 2.1 – Классификация прогнозов производственно-финансовых показателей предприятия
Прогнозы, построенные на основе рядов экономической динамики показателей предприятия, обычно относятся к поисковым формализованным прогнозам, которые базируются на существующей тенденции. Что касается других признаков классификации, то они будут отличаться друг от друга в каждом конкретном случае прогнозирования. Характерной особенностью формализованных прогнозов является предварительная формализация имеющейся информации в виде модели или формулы, описывающей основную тенденцию развития уровней изучаемого ряда динамики.
Так, найденные на стадии предварительного анализа средние показатели динамики могут быть использованы в качестве простейших инструментов прогнозирования.
1. Прогноз (YN+L) на основе среднего абсолютного приростаП (см. формулу (1.7)):
YN+L = YN +П × L, (2.1)
где YN – последний (N-й) уровень временного ряда; L – период упреждения
(прогнозирования).
Формула (2.1) дает достаточно точные значения прогноза изучаемого экономического показатели только в случае равномерного развития уровней ряда динамики, т.е. в арифметической прогрессии. Проверка данного условия сводится к проверке приблизительного постоянства цепных абсолютных приростов (ПЦЕП ≈ const).
2. Прогноз на основе среднего темпа ростаТр (см. формулу (1.8)):
YN+L = YN × (Тр )L. (2.2)
Формула (2.2) обычно применяется и дает хорошие прогнозные результаты только в случае равноускоренного развития уровней ряда динамики, т.е. в геометрической прогрессии. Проверка данного условия сводится к проверке приблизительного постоянства цепных темпов роста (ТР ЦЕП ≈ const).
Построенную на этапе аналитического выравнивания трендовую модель (1.11) также часто используют в качестве инструмента прогнозирования будущих значений показателей изучаемого предприятия. При этом в основе прогнозирования лежит экстраполяция найденной тенденции, т.е. распространение выявленных в периоде предыстории (на отрезке времени х = 1, 2, …, N) закономерностей и связей на будущее – на период упреждения L.
Экстраполяция основана на гипотезе об инерционности развития экономических систем, т.е. на предположении о том, что в недалекой перспективе выявленные в прошлом связи и закономерности кардинально не изменятся и будут действовать некоторое время и в будущем. Следует отметить, что такое предположение достаточно реально, особенно для краткосрочного периода, поскольку коренные изменения показателей производственно-финансовой деятельности предприятия обычно требуют значительных усилий, средств и достаточно длительного времени.
Замечание 7. При прогнозировании будущих значений уровней изучаемого ряда экономической динамики необходимо следить, чтобы среди наблюдаемых значений Yi не было так называемых аномальных или резко выделяющихся наблюдений в виде пиков или, наоборот, резких падений уровней ряда. Дело в том, что аномальные наблюдения обычно свидетельствуют о действии каких-то случайных факторов, не характерных для остальных периодов (моментов) времени. Поэтому при их наличии средняя величина Y будет искажена и, как следствие, коэффициенты линейного тренда a0, a1 будут содержать смещение, т.е. систематическую ошибку. Это в конечном итоге повлечет за собой неверную прогнозную оценку, например, сильно завышенную или заниженную.
Существуют объективные взаимосвязи между числом оцениваемых коэффициентов тренда и длиной изучаемого ряда экономической динамики N, а также между величиной N и периодом упреждения L. Доказано, что число N должно в 3-4 раза превышать число оцениваемых коэффициентов тренда. Для линейного уравнения это число равно двум (а0, а1), поэтому, чтобы построить линейный тренд Ŷ = a0 + a1х, необходимо располагать не менее 6-8 уровнями временного ряда. При этом должно выполняться условие: L ≤ N/3, т.е. длина периода упреждения не может превышать трети длины периода предыстории. Нарушение указанных соотношений приводит к получению ненадёжных трендовых моделей и, соответственно, ошибочных прогнозных оценок.
К количественному прогнозу любого экономического показателя выдвигаются два главных требования: точность и достоверность. Точность характеризуется степенью варьирования прогнозного значения ŶN+L, которая измеряется предельной ошибкой прогноза Δ. Чем меньше Δ, тем точнее прогноз, и наоборот. Нулевое значение Δ отвечает так называемому точечному прогнозу (в виде одного числа – точки на числовой оси). Точечный прогноз считается максимально точным.
Достоверность прогноза отображает вероятность совпадения будущего фактического значения YN+L с прогнозным значением ŶN+L. Очевидно, что с ростом предельной ошибки прогноза Δ его достоверность увеличивается, а снижение Δ (рост точности прогноза) приводит к уменьшению достоверности прогноза. Следовательно, точечный прогноз (Δ = 0) имеет минимальную достоверность, т.к. точное совпадение фактического будущего значения YN+L с прогнозным значением ŶN+L является маловероятным. Это означает, что точность и достоверность прогноза находятся между собой в обратно пропорциональной зависимости: рост одного параметра вызывает уменьшение другого, и наоборот.
Точечные прогнозы находятся на базе уравнения тренда путем подстановки вместо Х будущего значения фактора времени х = N + L, которое соответствует периоду упреждения L. Например, для линейного тренда Ŷ = a0 + a1х точечный прогноз имеет следующий общий вид:
ŶN+L = a0 + a1(N + L) . (2.3)
Рассчитаем по данным примера из главы 1 точечный прогноз прибыли предприятия на январь следующего года (L = 1; х = N + L = 12 + 1 = 13):
ŶN+L = 6,619697 + 1,425175×13 = 25,14697 (тыс. грн.)
Таким образом, если выявленные за изучаемый период времени закономерности изменения прибыли предприятия не претерпят серьезных изменений в ближайшем будущем, то в январе следующего года финансовый результат следует ожидать на уровне 25,15 тыс. грн.
Как было отмечено выше, полученный точечный прогноз прибыли ŶN+L отличается максимальной точностью и минимальной достоверностью. Поэтому в практике прогнозирования экономических показателей, в том числе и прибыли, обычно идут на компромисс: на основе точечного прогноза строят интервальный прогноз в виде двух чисел – нижней и верхней границ доверительного интервала с заранее заданной достоверностью Р попадания в него фактического значения YN+L. Границы доверительного интервала прогноза рассчитываются по следующей общей схеме:
ŶN+L ± Δ. (2.4)
Иными словами, в центре доверительного интервала находится точечный прогноз ŶN+L, а его ширина равняется 2Δ. В результате получения доверительного интервала по схеме (2.4) точность прогноза падает, поскольку расширяются его границы, но при этом обеспечивается заранее заданная достоверность прогноза Р.
В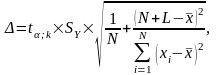 озникает
вопрос: как рассчитать величину предельной
ошибки прогноза Δ? Теория статистического
моделирования и прогнозирования дает
на него следующий ответ. Для линейного
тренда формула предельной ошибки
прогноза с достоверностью Р
= (1 - α)×100
% попадания в доверительный интервал
будущего фактического значения прибыли
имеет следующий вид:
озникает
вопрос: как рассчитать величину предельной
ошибки прогноза Δ? Теория статистического
моделирования и прогнозирования дает
на него следующий ответ. Для линейного
тренда формула предельной ошибки
прогноза с достоверностью Р
= (1 - α)×100
% попадания в доверительный интервал
будущего фактического значения прибыли
имеет следующий вид:
(2.5)
где tα;k – коэффициент доверия (α-квантиль t-распределения
Стьюдента с уровнем значимости α и k = N - m степенями
свободы, m – число оцениваемых коэффициентов модели тренда);
SY – стандартная ошибка тренда;
х – среднее значение фактора времени.
Следует отметить, что уровень значимости α определяется, исходя из необходимой и заранее заданной достоверности Р (в %) из следующего соотношения: α = 1 - Р/100. Например, при необходимой достоверности попадания в доверительный интервал будущего фактического значения YN+L Р = 95 % α = 0,05; при Р = 90 % α = 0,10; при Р = 99 % α = 0,01 и т.д.
Число степеней свободы k = N - m для линейного тренда (m = 2) равняется N - 2. А величина коэффициента доверия (α-квантиль t-распределения Стьюдента) находится с помощью редактора Excel (команда = стьюдраспобр (α; N - m) – Enter).
С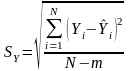 тандартная
ошибка тренда SY
определяется по формуле
тандартная
ошибка тренда SY
определяется по формуле
(2.6)
и рассчитывается автоматически в процессе построения модели тренда (см. первый блок, четвертую строку результатов расчета уравнения регрессии, построенного с помощью стандартной программы «Регрессия» редактора Excel). Она характеризует абсолютную точность найденного уравнения тренда: чем меньше SY, тем более точен тренд, и наоборот.
Третий сомножитель (радикал) в выражении (2.5) отображает выбранную форму математической зависимости между уровнями ряда динамики прибыли предприятия и временем х. В данном случае для линейного тренда выражение под корнем не слишком сложно, но при переходе к криволинейным функциям связи оно существенно усложняется. Следует иметь в виду, что автоматический расчёт величины предельной ошибки прогноза в стандартных программах корреляционно-регрессионного анализа редактора Excel не предусмотрен. А вручную осуществить указанные расчёты при больших m не представляется возможным. Поэтому в реальных экономических исследованиях с этой целью пользуются системой программ STATISTICA.
Проиллюстрируем её применение на примере использования линейного тренда Ŷ = 6,6197 + 1,4252х для построения доверительного интервала прогноза прибыли предприятия на январь месяц следующего года с достоверностью Р = 95 %; 99 %. Для этого после построения регрессионной модели в нижней средней части панели «Результатов множественной регрессии» (Multiple Regression Results) необходимо активизировать опцию «Прогноз зависимой переменной» (Predict dependent var.), предварительно указав уровень значимости и будущее значения фактора времени х = N + L. После команды ОК появляются табл. 2.1, 2.2, в которых точечный прогноз и границы интервального прогноза находятся в 3-х последних строках.
Таблица 2.1 – Точечный прогноз и 95-процентный доверительный
интервал прогноза прибыли предприятия на январь следующего года
Predicting Values for (new.sta) |
|
|||
|
|
|
B-Weight |
|
|
B-Weight |
Value |
* Value |
|
VAR5 |
1,425175 |
13 |
18,52727 |
|
Intercept |
|
|
6,619697 |
|
Predicted |
|
|
25,14697 |
|
-95,0%CL |
|
|
18,05408 |
|
+95,0%CL |
|
32,23986 |
||
Таблица 2.2 – Точечный прогноз и 99-процентный доверительный
интервал прогноза прибыли предприятия на январь следующего года
Predicting Values for (new.sta) |
|
|||
|
|
|
B-Weight |
|
|
B-Weight |
Value |
* Value |
|
VAR5 |
1,425175 |
13 |
18,52727 |
|
Intercept |
|
|
6,619697 |
|
Predicted |
|
|
25,14697 |
|
-99,0%CL |
|
|
15,05814 |
|
+99,0%CL |
|
35,2358 |
||
Таким образом, общий вывод по результатам прогнозирования выглядит так: если выявленные за периоде предыстории закономерности изменения прибыли предприятия не претерпят серьезных изменений в ближайшем будущем, то в январе следующего года его финансовый результат следует ожидать на уровне 25,15 тыс. грн. При этом с достоверностью 95 % точечный прогноз будет находиться в интервале 18,05 – 32,24 тыс. грн., а с достоверностью 99 % в интервале 15,06 – 35,24 тыс. грн. (в табл. CL – confidence level).
Полученные результаты прогнозирования можно представить графически на рис. 2.2.
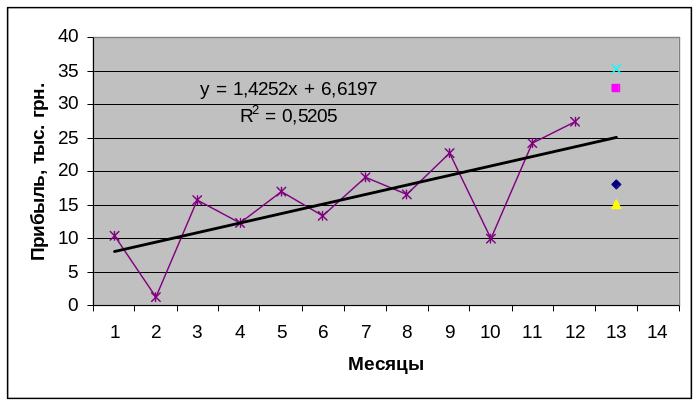
Рис. 2.2 – Фактические, выровненные по линейному тренду и прогнозные (точечные и интервальные) значения прибыли предприятия на 13-й месяц
Визуальный анализ рис. 2.2 показывает, что 95-процентный интервал прогноза прибыли предприятия на январь следующего года (табл. 2.1) является ýже по сравнению с соответствующим 99-процентным доверительным интервалом из табл. 2.2.
Математическое исследование выражения (2.5) показывает, что величина Δ прямо зависит от трех факторов и обратно от одного. А именно:
1. Рост необходимой достоверности прогноза Р = (1 - α) × 100 %, т.е. вероятности попадания в доверительный интервал будущего фактического значения прибыли предприятия приводит к снижению уровня значимости α и к повышению коэффициенту доверия (α-квантиля распределения Стьюдента) и, следовательно, к росту величины предельной ошибки прогноза Δ. Это подтверждает сделанный выше вывод об обратно пропорциональной зависимости между характеристиками достоверности и точности прогнозных оценок. Рис. 2.2 иллюстрирует эту взаимосвязь.
2. Величина стандартной ошибки тренда SY прямо влияет на размер Δ. Очевидно, что чем более точна модель тренда, тем точнее построенный интервальный прогноз. Это означает, что для получения наиболее точных прогнозных оценок прибыли предприятия следует стремиться применять наиболее точные модели трендов с минимальным значением SY.



Y
3. С ростом L (выхода за рамки исследуемого ряда динамики прибыли) растет числитель второй дроби (N + L –х)2, которая находится под корнем (2.5), а, следовательно, и величина самой предельной ошибки прогноза Δ (рис. 2.3). Поэтому, наиболее точный прогноз при всех прочих равных условиях можно получить не при экстраполяции тренда, а при его интерполяции, если N + L =х.



а0
x
4
5
3
2
1
0
Рис. 2.3 – Доверительные интервалы прогноза (заштрихованные вертикальные линии) для разных периодов упреждения (L = 1, 2, 3)
4. При росте длины временного ряда N величина 1/N под корнем снижается и в то же время растет число степеней свободы k в первом сомножителе (2.5). Это приводит к уменьшению коэффициента доверия tα;k. Следовательно, повышение длины периода предыстории N при всех прочих неизменных условиях уменьшает размер предельной ошибки Δ.
Приведенные выше рассуждения справедливы для любой линейной и криволинейной модели тренда. Они показывают, что стремление исследователя к получению наиболее достоверных прогнозных оценок ведет к росту предельной ошибки прогноза Δ и падению их точности. И наоборот – менее достоверным оценкам отвечают более точные прогнозы.
Одновременное увеличение достоверности и точности прогнозов производственно-финансовых показателей предприятия можно достичь лишь при увеличении длины ряда динамики N. Поэтому в практике прогнозирования при фиксированном значении N всегда приходится искать компромисс между двумя взаимообратными характеристиками – точностью и достоверностью прогноза.
Очевидно также то, что наиболее точные прогнозы можно получить лишь на основе наиболее точных уравнений трендов, для которых выполняется условие minSY. При этом, чем дальше исследователь стремится заглянуть в будущее (L → ∞), тем менее точными оказываются прогнозные оценки изучаемого экономического показателя предприятия. Будущее всегда неопределённо: большинство параметров экономических систем ведут себя как случайные величины, предвидение которых на длительный период времени сильно затруднено.
Замечание 8. Увеличение длины ряда динамики N возможно осуществить двумя способами: 1) добавить более ранние наблюдения; 2) дезагрегировать наблюдения, т.е. перейти к уровням за более мелкие промежутки времени, например, заменить годовые данные полугодовыми, квартальными, месячными и т.д. Однако при этом возникают новые проблемы и трудности, о которых забывать нельзя. Первый путь вызывает усиление старых тенденций, т.к. увеличивается объем старой информации, относящейся к начальным уровням ряда динамики. Это не совсем желательно, особенно при оперативном и краткосрочном прогнозировании. Второй путь ведёт к фактическому затушёвыванию основной тенденции развития экономической динамики (вспомним один из методов ее выявления – метод укрупнения периодов). Дезагрегирование наблюдений фактически приводит к усилению действия случайных факторов в уровнях ряда динамики и сокрытию его основной тенденции развития.
И все же, среди указанных четырех факторов, влияющих на величину предельной ошибки прогноза Δ (см. формулу (2.5)), существует один, который непосредственно зависит от знаний, опыта и интуиции самого исследователя. Это второй фактор – величина стандартной ошибки тренда SY, определяемая выбором наиболее точной модели тренда.
Очевидно, что если динамика изучаемого экономического показателя характеризуется не прямолинейной, а криволинейной тенденцией развития – наличием экстремумов (максимумов или минимумов), точек перегиба или асимптот, то правильный выбор математической формы тренда может существенно снизить величину SY. Например, в случае нелинейной тенденции динамики показателя прибыли SY ПАРАБОЛА ≈ SY ЛИНЕЙН/4 (см. рис. 2.4).
Правильному выбору математической формы тренда в значительной мере способствует визуальный анализ графика ряда экономической динамики. Сравнение его с графиками известных нелинейных математических функций позволяет осуществить такой выбор (см. рис. 2.5 – 2.7).
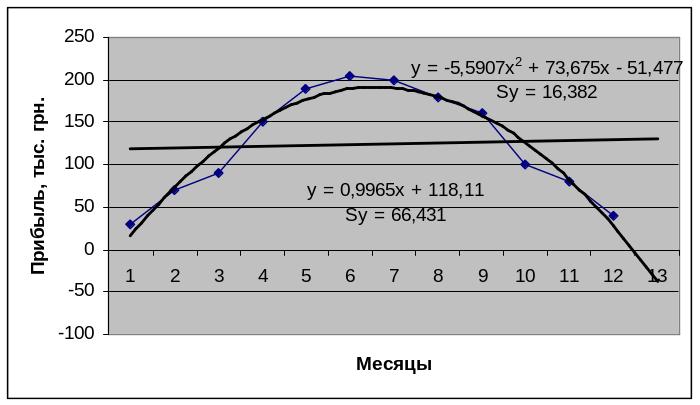
Рис. 2.4 – Стандартные ошибки линейного и параболического трендов
Y




a1 > 0, a0 > 0
Y

a0



a1 > 0, a0 < 0
a0




х
х
(-a0/a1)2
(-а0/а1)2
X
0
X
0


а1 < 0, а0 > 0
a0
a0

а1 < 0, а0 < 0
б)
a)
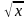
Рис. 2.5 – Графики функции Y = а0 + а1
Y
Y

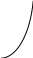

Y
Y
а1 > 0, а0 > 0

а1+а0
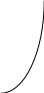

а1 < 0, а0 > 0
а1+а0



ln(-а0/а1)
х
а1 > 0, а0 < 0
0
X

а1+а0

х
ln(-а0/а1)
0
X
а1+а0

а1 < 0, а0 < 0
б)
a)
Рис. 2.6 – Графики линейной экспоненты Y = а0 + а1ех
Д ля динамики экономических показателей, описываемых функцией
Y = а0+ а1 , характерен замедленный рост (рис. 2.5, а) или замедленное снижение (рис. 2.5, б), в то время как экспонента (рис. 2.6, а и б) хорошо аппроксимирует лавинообразно развивающиеся процессы, т.е. динамику с ускорением.
При моделировании и прогнозировании развития типа «жизненный цикл товара» отлично зарекомендовали себя так называемые S-образные кривые (синусоида, логистическая функция, кривая Гомперца и др. (рис. 2.7).


Y

ехр(а2)







ехр(-1+а2)
0 < а1 < 1, а0 < 0

ехр(а0+а2)

ln(-1/а0)/ln(а1)
0
x
Рис. 2.7 – График функции Гомперца Y = ехр(а0а1х + а2)