

3501
.pdf

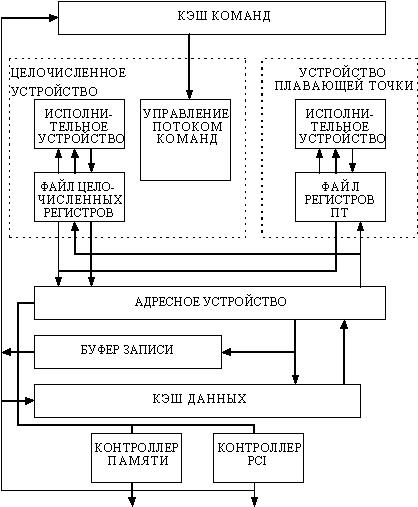
Рис. 215. Основные компоненты процессора Alpha 21066
Кэш-память команд представляет собой кэш прямого отображения емкостью 8 Кбайт. Команды, выбираемые из этой кэш-памяти, могут выдаваться попарно для выполнения в одно из исполнительных устройств. Кэш-память данных емкостью 8 Кбайт также реализует кэш с прямым отображением. При выполнении операций записи в память данные одновременно записываются в этот кэш и в буфер записи. Контроллер памяти или контроллер ввода/вывода шины PCI обрабатывают все обращения, которые проходят через расположенные на кристалле кэш-памяти первого уровня.
565
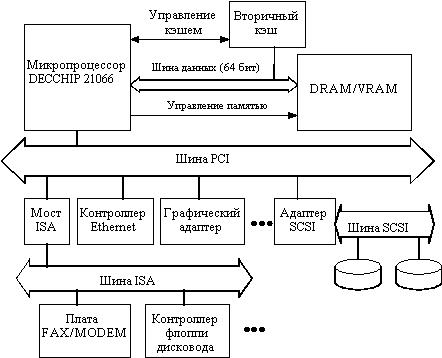
Рис. 216. Пример построения системы на базе микропроцессора Alpha
21066
Конструкция поддерживает до четырех банков динамической памяти, каждый из которых может управляться независимо, что дает определенную гибкость при организации памяти и ее модернизации. Один из банков может заполняться микросхемами видеопамяти (VRAM) для реализации дешевой графики. Контроллер памяти прямо работает с видеопамятью и поддерживает несколько простых графических операций.
Высокоскоростная шина PCI имеет ряд привлекательных свойств. Помимо возможности работы с прямым доступом к памяти и программируемым вводом/выводом она допускает специальные конфигурационные циклы, расширяемость до 64 бит, компоненты, работающие с питающими напряжениями 3.3 и 5 В, а также более быстрое тактирование. Базовая реализация шины PCI поддерживает мультиплексирование адреса и данных и работает на частоте 33 МГц, обеспечивая максимальную скорость передачи данных 132 Мбайт/с. Шина PCI непосредственно управляется микропроцессором. На рис. 216 показаны некоторые высокоскоростные периферийные устройства: графические адаптеры, контроллеры SCSI и сетевые адаптеры, подключенные непосредственно к шине PCI. Мостовая
567