

3119
.pdfРис. 18. Корреляционное поле зависимости результатов тестирования от среднего балла студентов
Рис. 19. Корреляционное поле зависимости результатов тестирования от посещаемости занятий
По данным диаграммам можно сделать вывод о наличии достаточно сильной положительной линейной зависимости результатов тестирования от среднего балла и об умеренной зависимости от посещаемости занятий.
41
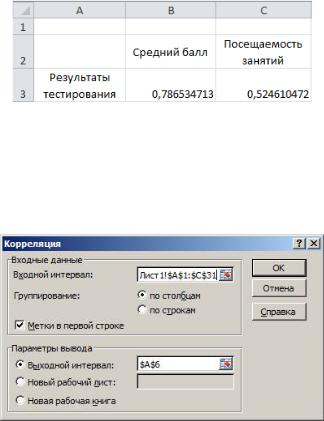
Для точного определения степени зависимости факторов определим парные коэффициенты корреляции с помощью встроенной функции Excel:
=КОРРЕЛ(Лист1!C2:C31;Лист1!A2:A31) =КОРРЕЛ(Лист1!C2:C31;Лист1!B2:B31)
Результаты вычислений представлены на рис. 20. Они подтверждают вывод о достаточно сильной положительной связи между результатами тестирования и средним баллом и об умеренном характере связи результатов тестирования и посещаемости занятий.
Рис. 20. Результаты вычисления парных коэффициентов корреляции
Для вычисления всей корреляционной матрицы может использоваться процедура Корреляция пакета Анализ данных
(рис. 21-22).
Рис. 21. Окно выбора входных параметров процедуры Корреляция пакета Анализ данных
42
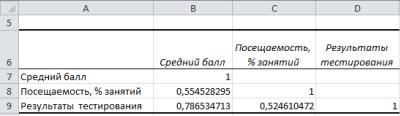
Рис. 22. Корреляционная матрица
Процедура Корреляция возвращает нижнюю левую часть корреляционной матрицы, верхняя правая часть матрицы может быть получена из условия ее симметричности относительно главной диагонали.
2.6. Пример выполнения парного регрессионного анализа в Excel
Определим уравнение регрессии с помощью графического метода. Для этого построим корреляционное поле, отражающее зависимость результатов тестирования от среднего балла и добавим на него линию тренда. Это можно сделать двумя способами:
-выделить диаграмму и выбрать команду Макет / Анализ / Линия тренда / Линейное приближение, затем выделить построенную линию, в контекстном меню выбрать команду Формат линии тренда и в диалоговом окне поставить флажок Показывать уравнение на диаграмме;
-выделить точки на корреляционном поле, в контекстном меню выбрать команду Добавить линию тренда,
выбрать тип Линейная, уставить флажок |
Показывать |
уравнение на диаграмме. |
|
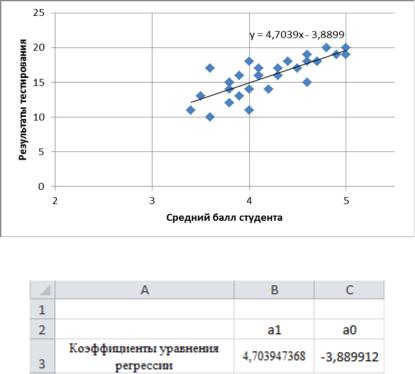
Результат построения линии тренда показан на рис. 23. Построим уравнение парной регрессии для результатов тестирования и среднего балла студента. Вначале воспользуемся функцией ЛИНЕЙН(). Для этого надо выделить две ячейки, в которые будут записаны коэффициенты
43
уравнения, задать вручную или с помощью специального диалогового окна формулу
=ЛИНЕЙН(Лист1!C2:C31;Лист1!A2:A31)
и нажать сочетание клавиш Ctrl+Shift+Enter. Результат работы функции представлен на рис. 24.
Рис. 23. Построение линии тренда на корреляционном поле
Рис. 24. Результат работы функции ЛИНЕЙН()
С учетом найденных значений коэффициентов уравнение регрессии запишется в виде
y 3.8899 4.7039 x.
Более подробные статистические данные можно получить, если использовать процедуру Регрессия из пакета
44
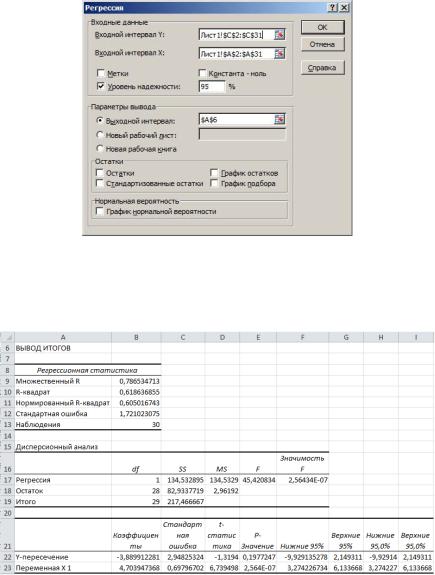
анализа данных. Диалоговое окно с входными параметрами приведено на рис. 25.
Рис. 25. Диалоговое окно задания входных данных для процедуры Регрессия
Результат работы процедуры представлен на рис. 26.
Рис. 26. Результат работы процедуры Регрессия
45
По данной таблице можно сделать следующие выводы: - в последней таблице в столбце Коэффициенты находятся коэффициенты уравнения регрессии: в строке Y находится значение a0, в строке Переменная X1 – значение
a1; в случае множественной регрессии в таблице присутствовали бы еще строки Переменная Х2, Переменная Х3 и т.д., содержащие коэффициенты a2, a3, … перед соответствующими переменными;
-в этой же таблице в столбце P-Значение приведены значимости коэффициентов уравнения регрессии по всем переменным; если значимость коэффициента меньше 0.05, то с вероятностью 95% можно считать данный коэффициент значимым, т.е. результативный признак в сильной степени зависит от проверяемого факторного, если P 0.05, то коэффициент можно считать нулевым (необходимый уровень вероятности задавался во входных данных);
-в таблице Дисперсионный анализ оценивается качество всей модели; величина F – критерий Фишера, используется для проверки адекватности модели; для данного критерия определяется его значимость (столбец Значимость F)
иесли она меньше 0.05, то построенная модель является адекватной с вероятностью 95%;
-значение коэффициента детерминации (R-квадрат) показывает, насколько хорошо построенное уравнение регрессии аппроксимирует исходные данные; чем ближе
значение r2 к 1, тем лучше построенная модель описывает
исследуемое явление, при r2 0.5 принято считать, что точность аппроксимации недостаточна и необходимо улучшение модели (за счет добавления новых факторных переменных, учета нелинейных зависимостей и т.д.).
По исследуемой модели можно сказать, что коэффициент a1 при переменной x1 является значимым; модель в целом является адекватной.
46
3. ЛАБОРАТОРНОЕ ЗАДАНИЕ
Задание 1. К таблице из лабораторной работы №2 добавить два столбца, значения которых, возможно, влияют на уже имеющиеся экспериментальные данные.
Задание 2. |
Проанализировать |
зависимость |
между |
|
факторными и результативными столбцами графически. |
|
|||
Задание 3. |
Вычислить |
коэффициенты |
парной |
|
корреляции с помощью встроенной функции Excel и с помощью пакета Анализ данных.
Задание 4. Определить коэффициенты частной и множественной корреляции с помощью соответствующих формул. Сделать выводы по полученным значениям коэффициентов.
Задание 5. К таблице исходных данных добавить столбец, содержащий порядковую переменную, и определить коэффициент ранговой корреляции Спирмена для порядковой переменной и основной характеристики исследуемого объекта.
Задание 6. Выполнить парный регрессионный анализ: а) выбрать результативный признак и влияющий на
него факторный признак; б) построить для выбранных признаков линию тренда
на корреляционном поле; в) определить коэффициенты уравнения регрессии с
помощью функции ЛИНЕЙН(), записать уравнение регрессии; г) выполнить регрессионный анализ с помощью пакета
Анализ данных; д) сделать выводы о значимости всей модели и
выбранного факторного признака, оценить влияние факторного признака на результативный.
Задание 7. Провести множественный регрессионный анализ:
а) выбрать результативный и влияющие на него 2 факторных признака;
б) выполнить регрессионный анализ с помощью пакета Анализ данных, записать уравнение регрессии;
47
в) сделать выводы о значимости всей модели и отдельных факторных признаков.
4.УКАЗАНИЯ ПО ОФОРМЛЕНИЮ ОТЧЕТА
Отчет должен содержать:
- наименование и цель работы; - краткие теоретические сведения;
- задание на лабораторную работу; - результаты выполнения лабораторной работы.
5.КОНТРОЛЬНЫЕ ВОПРОСЫ
1.Что такое корреляционный анализ? Какие значения могут принимать коэффициенты корреляции и какие выводы они позволяют сделать?
2.Какой коэффициент используется для определения корреляции между порядковыми переменными?
3.Как можно определить коэффициенты корреляции в
Excel?
4.Что такое регрессионный анализ? Чем парная регрессия отличается от множественной?
5.Какая встроенная функция Excel предназначена для вычисления коэффициентов линейного уравнения парной регрессии?
6.Какие характеристики можно найти с помощью процедуры Регрессия пакета анализа данных? Какие выводы можно по ним сделать?
48
Лабораторная работа №4 ДИСПЕРСИОННЫЙ АНАЛИЗ ДАННЫХ В EXCEL
1. ОБЩИЕ УКАЗАНИЯ ПО ВЫПОЛНЕНИЮ ЛАБОРАТОРНОЙ РАБОТЫ
1.1. Цель работы
Изучение основных понятий дисперсионного анализа и методов его реализации в Microsoft Excel; получение практических навыков выполнения дисперсионного анализа и интерпретации его результатов.
1.2. Используемое оборудование и программное обеспечение
Для выполнения лабораторной работы требуется ПЭВМ типа IBM PC с установленной ОС Windows XP и выше, математический пакет Microsoft Excel 2007 и выше.
2. МЕТОДИЧЕСКИЕ УКАЗАНИЯ ПО ВЫПОЛНЕНИЮ ЛАБОРАТОРНОЙ РАБОТЫ
2.1. Основные понятия дисперсионного анализа
Дисперсионный анализ – это метод статистического анализа, применяемый для исследования влияния на результативную переменную одного или нескольких качественных признаков.
В зависимости от числа рассматриваемых факторных переменных дисперсионный анализ может быть однофакторным и многофакторным.
Однофакторный дисперсионный анализ устанавливает значимость влияния факторного признака на результативный. При этом проверяется гипотеза о равенстве средних значений в нескольких независимых выборках. Если гипотеза не подтверждается, то проверяемый признак существенно влияет на результативный, в противном случае зависимостей не найдено. Для проверки гипотезы обычно используется критерий Фишера.
49
Общая дисперсия выборки 2 подразделяется на часть,
объясняющую различия между группами 2A (межгрупповая дисперсия) и часть, объясняющую различия между единицами совокупности внутри группы 2z (внутригрупповая дисперсия):
2 2A 2z .
Межгрупповая дисперсия объясняет изменчивость значений выборки с разными значениями факторного признака, а внутригрупповая дисперсия объясняет вариацию результативной переменной при одинаковых значениях факторов из-за неучтенных в модели воздействий.
Пусть исследуется влияние фактора А на вариацию признака Y, при этом переменная А принимает k значений, называемых уровнями фактора. На каждом уровне получено по m значений признака Y. Тогда вся совокупность из n k m наблюдений может быть записана в виде табл. 3.
|
|
|
|
Таблица 3 |
|
|
|
|
|
|
|
Уровни |
Отдельные значения признака Y |
|
|||
фактора A |
|
||||
|
|
|
|
|
|
1 |
y11 |
y12 |
… |
y1m |
|
2 |
y21 |
y22 |
… |
y2m |
|
… |
… |
… |
… |
… |
|
k |
yk1 |
yk2 |
… |
ykm |
|
Двухфакторный дисперсионный анализ устанавливает значимость влияния двух факторных признаков на результативный.
Пусть исследуется влияние факторов А и В на вариацию признака Y, при этом переменная А имеет a уровней, а В - b уровней. При каждом сочетании уровней двух факторов получено по m значений признака Y. Например,
50