

3119
.pdfприменить различные способы вращения с последующим анализом их результатов.
Рис. 75. График каменистой осыпи
3. ЛАБОРАТОРНОЕ ЗАДАНИЕ
Задание 1. К таблице из лабораторной работы №6 добавить 2 новых факторных признака.
Задание 2. Выполнить факторный анализ методом главных компонент без вращения факторов. Сделать выводы о количестве главных компонент и об их связи с исходными факторами.
Задание 3. Произвести вращение факторов несколькими методами, сравнить графики факторных нагрузок для каждого случая.
4. УКАЗАНИЯ ПО ОФОРМЛЕНИЮ ОТЧЕТА
Отчет должен содержать:
-наименование и цель работы;
-краткие теоретические сведения;
101
-задание на лабораторную работу;
-результаты выполнения лабораторной работы.
5. КОНТРОЛЬНЫЕ ВОПРОСЫ
1.Что такое факторный анализ? Для чего он применяется?
2.В чем заключается метод главных компонент?
3.Как можно определить число главных компонент в системе STATISTICA?
4.Как определить степень связи главных компонент и исходных факторных признаков исследуемого объекта?
102
Лабораторная работа №8
АНАЛИЗ ДАННЫХ МЕТОДАМИ DATA MINING
ВПАКЕТЕ STATISTICA
1.ОБЩИЕ УКАЗАНИЯ ПО ВЫПОЛНЕНИЮ ЛАБОРАТОРНОЙ РАБОТЫ
1.1.Цель работы
Изучение основных понятий Data Mining; получение практических навыков нахождения анализа данных в пакете
STATISTICA.
1.2.Используемое оборудование и программное обеспечение
Для выполнения лабораторной работы требуется ПЭВМ типа IBM PC с установленной ОС Windows XP и выше, пакет STATISTICA 10 или последующих версий.
2. МЕТОДИЧЕСКИЕ УКАЗАНИЯ ПО ВЫПОЛНЕНИЮ ЛАБОРАТОРНОЙ РАБОТЫ
2.1. Понятие о Data Mining
Одной из основных задач статистического анализа данных является проверка гипотез, выдвигаемых специалистом-аналитиком. Однако в больших объемах информации могут содержаться скрытые закономерности, которые аналитик может пропустить. Для обнаружения таких скрытых знаний применяются специальные методы автоматического анализа, за которыми закрепилось название
Data Mining («добыча данных»).
Основными задачами, решаемыми с помощью методов
Data Mining, являются:
-классификация – определение класса объекта по его характеристикам, при этом множество классов, к которым может быть отнесен объект, заранее известно;
-регрессия – позволяет определить по известным характеристикам объекта значение некоторого его параметра;
103
-поиск ассоциативных правил – нахождение частых зависимостей (ассоциаций) между объектами или событиями; найденные зависимости представляются в виде правил и могут быть использованы как для лучшего понимания природы анализируемых данных, так и для предсказания появления событий;
-кластеризация – поиск независимых групп (кластеров)
иих характеристик во всем множестве анализируемых данных. Одной из наиболее распространенных задач анализа
данных является определение взаимосвязей между двумя или более событиями. Такие зависимости формулируются в виде
ассоциативных правил, используемых как для количественного описания связей между объектами, так и для предсказания появления событий.
Например, поиск ассоциативных правил используется для анализа рыночных корзин - выявления наборов часто покупаемых вместе продуктов, определения профиля клиентов с целью предложения нужных именно им товаров и т.д.
Ассоциативное правило формулируется в виде «если условие, то следствие» и обозначается X Y (если X, то Y).
Основным достоинством правил является их легкое восприятие человеком, однако они не всегда полезны. Выделяют три вида правил:
-полезные правила – содержат информацию, которая ранее была неизвестна, но имеет логичное объяснение; такие правила могут быть использованы для принятия решений, приносящих выгоду;
-тривиальные правила – содержат легко объясняемую информацию, которая уже известна; такие правила не могут принести какой-либо пользы, т.к. отражают или известные законы предметной области или результаты прошлой деятельности;
-непонятные правила – содержат информацию, которая не может быть объяснена; такие правила могут быть получены или на основе аномальных значений, или глубоко скрытых
104
знаний, их использование для принятия решений может привести к непредсказуемым результатам.
Для оценки ассоциативных правил вводится понятие транзакция – некоторое множество событий, происходящих совместно. Типичный пример транзакции – покупка клиентом товаров (одного или нескольких одновременно).
Каждое ассоциативное правило численно характеризуется следующими показателями:
-поддержка – отношение числа транзакций, содержащих как условие правила, так и его следствие, к общему количеству транзакций;
-достоверность – отношение числа транзакций, содержащих и условие, и следствие, к количеству транзакций, содержащих только условие.
Если поддержка и достоверность правила достаточно высоки, то можно с большой вероятностью предсказать, что любая транзакция, включающая условие, также будет содержать и следствие правила.
При поиске ассоциативных правил специалистаналитик задает минимальные значения поддержки и достоверности. Правила, для которых данные характеристики превышают минимально допустимые, называются сильными.
2.2. Решение задач методами Data Mining с помощью пакета STATISTICA
Пакет STATISTICA содержит набор специализированных процедур Data Mining, основными из которых являются:
- Специальная выборка и фильтрация данных (для больших объемов данных) (Feature Selection and Variable Filtering (for very large data sets)) - данный модуль автоматически выбирает подмножества переменных из заданного файла данных для последующего анализа;
105
-Правила ассоциации (Association Rules) - модуль является реализацией так называемого априорного алгоритма обнаружения правил ассоциации;
-Интерактивный углубленный анализ (Interactive DrillDown Explorer) - представляет собой набор средств для гибкого исследования больших наборов данных;
-Обобщенный метод максимума среднего и кластеризация методом К-средних (Generalized EM & k-Means Cluster Analysis) - данный модуль - это расширение методов кластерного анализа, предназначен для обработки больших наборов данных и позволяет кластеризовать как непрерывные, так и категориальные переменные, обеспечивает все необходимые функциональные возможности для распознавания образов;
-Обобщенные классификационные и регрессионные деревья (General Classification and Regression Trees (GTrees)) -
модуль является набором методов обобщенной классификации
ирегрессионных деревьев;
-Критерии согласия (Goodness of Fit Computations)
данный модуль производит вычисления различных статистических критериев согласия как для непрерывных переменных, так и для категориальных;
-Быстрые прогнозирующие модели (для большого числа наблюдаемых значений) (Rapid Deployment of Predictive Models) - модуль позволяет строить за короткое время классификационные и прогнозирующие модели для большого объема данных.
2.3. Пример анализа данных методами Data Mining в
системе STATISTICA
Проведем анализ результатов ЕГЭ для группы абитуриентов. Исходные данные приведены на рис. 76.
106
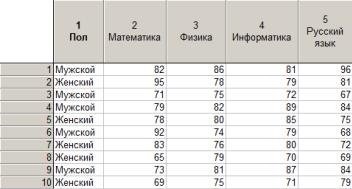
Рис. 76. Фрагмент таблицы с исходными данными
Для получения первоначального представления о распределении переменных и связях между ними проведем интерактивный углубленный анализ (или интерактивное «бурение»). Данный вид анализа позволяет выделить подгруппы, характеризующиеся определенными значениями признаков. Выполним команду Добыча данных / Добыча данных - Проекты / Добытчик данных – Бурение и расслоение данных / Интерактивное бурение (Data Mining / Data Mining – Workspaces / Data Miner – General Slicer/Dicer Explorer with Drill-Down / Interactive Drill Down). В диалоговом окне задания входных переменных (Drill variables) необходимо выбрать переменные, разделив их по типу – классификационные и непрерывные (рис. 77-78).
107
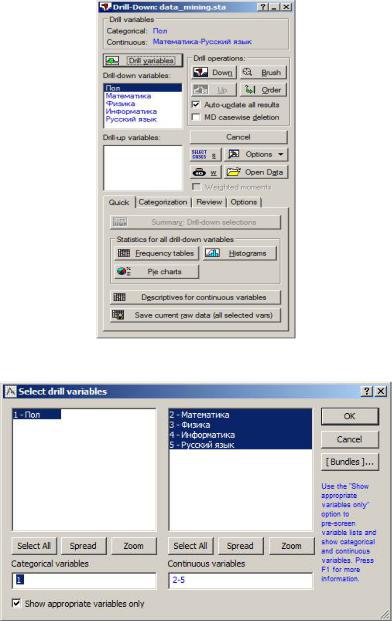
Рис. 77. Диалоговое окно с входными данными
Рис. 78. Диалоговое окно выбора переменных для анализа
108
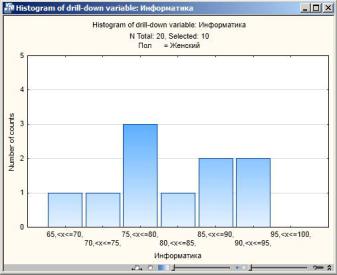
Для выполнения операции «бурения», т.е. выделения отдельных подгрупп из анализируемых данных, надо нажать кнопку Вниз (Down) и выбрать значение первой из входных переменных. В нашем примере выберем пол – Женский. Результаты анализа можно посмотреть в таблицах частот
(Frequency tables), на гистограммах (Histograms) и круговых диаграммах (Pie Charts), отображающих распределение элементов с различными значениями исходных переменных. На рис. 79 приведена гистограмма распределения оценок ЕГЭ по информатике для девушек.
Чтобы провести более глубокий анализ, необходимо еще раз нажать кнопку Вниз и выбрать значение следующей входной переменной. На рис. 80 приведена круговая диаграмма, отображающая распределения баллов ЕГЭ по физике для девушек, получивших по математике от 75 до 80 баллов.
Рис. 79. Гистограмма с результатами анализа
109
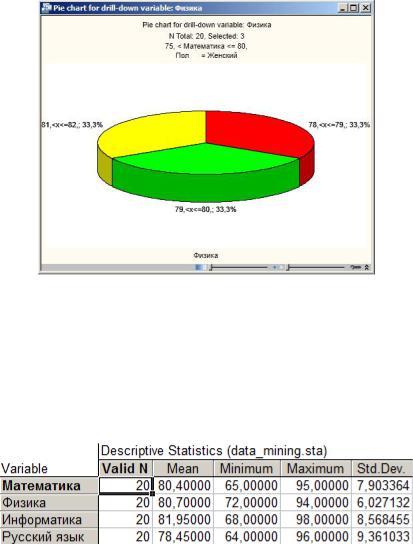
Рис. 80. Круговая диаграмма с результатами анализа
Далее произведем поиск ассоциативных правил в исходных данных. Для этого преобразуем таблицу следующим образом. Вначале определим средние значения баллов по каждому предмету с помощью команды Анализ / Основные статистики и таблицы / Описательные статистики (Statistics / Basic statistics/tables / Descriptive statistics) (рис. 81).
Рис. 81. Таблица с основными статистическими показателями
Далее добавим к исходной таблице 4 столбца, каждый элемент которых будет равен 1, если оценка для абитуриента больше среднего балла по соответствующему предмету, и 0 – в
110