

2264
.pdf2.ЭМПИРИЧЕСКИЕ РАСПРЕДЕЛЕНИЯ
ИМАТЕМАТИЧЕСКИЙ ФОРМАЛИЗМ
Так как большинство моделей информационного поиска учитывают статистическую природу текстов, остановимся на вопросах статистического распределения текстовых данных. В естественных науках хорошо известны и широко распространены такие статистические распределения, как Гауссово, показательное, биноминальное. Однако, в практике информационного поиска самое большое распространение имеет степенное распределение.
2.1. Эмпирические закономерности
Ниже будут обсуждаться параметры некоторых распределений, присущих многим информационным процессам, с учетом которых можно строить модели одновременно в рамках теории информационного поиска и концепции сложных сетей.
В 1965 году Д. Прайсом был впервые эмпирически обнаружен степенной закон распределения узлов по числу связей. Открытие в социальных сетях явления «тесного мира» С. Милграмом стало решающим фактором развития современной теории сложных сетей.
Важные явления и закономерности были обнаружены и исследованы в социальных сетях друзей и знакомств в последние годы. Оказалось, например, что в сетях друзей действует закон трех рубежей влияния: наше влияние распространяется только на наших друзей и друзей наших друзей. На следующем шаге это влияние уже ничтожно мало. Обратное также справедливо: наибольшее влияние на нас оказывают наши друзья и друзья наших друзей.
Еще на ранних этапах развития теории сложных сетей были детально исследованы законы распространения инфекционных заболеваний в социальных сетях, в том числе в сетях друзей и знакомых. Исследования последних лет
41
показали, что аналогичным образом распространяются в социальных сетях хорошее настроение (happiness) и депрессия, курение, алкоголизм, ожирениямидаже суицидальное
поведение. |
|
|
|
Когда |
при |
измерениях |
какой-либо величины |
вероятность получения того или иного значения обратна пропорциональна некоторой степени этого значения, говорят, что данная величина характеризуется степенным законом. Иногда также говорят о законе Зипфа или распределении Парето. Степенные законы часто встречаются в физике, биологии, науках о Земле и космосе, в экономике и финансах, информатике, демографии и прочих социальных науках.
В качестве основной функции, применяемой при статистическом методе описания, выступает функция распределения, которая определяет статистические характеристики рассматриваемой системы. Знание её изменения с течением времени позволяет описывать поведение системы со временем.
Дня введения понятия функции распределения сначала рассмотрим какую-либо макроскопическую систему, состояние которой описывается некоторым параметром х, принимающим
К дискретных значений: |
Пусть при проведении |
|||
над системой N измерений были получены следующие |
||||
результаты: |
значение |
наблюдалось |
при |
измерениях, |
значение х2 |
наблюдалось соответственно при |
измерениях и |
||
т.д. При этом, очевидно, что общее |
число |
измерений N |
||
равняется сумме всех измерений , в которых были получены
значения |
. |
|
|
|
Увеличение числа проведенных экспериментов до |
||||
бесконечности |
приводит к стремлению отношения |
к |
||
пределу |
|
|
|
|
|
|
|
|
|
42

Величина |
называется вероятностью |
измерения |
|||
значения . |
|
|
|
|
|
Вероятность |
представляет |
собой |
величину, |
||
которая может принимать значения в интервале 0 < |
< 1. |
||||
Значение |
= 0 соответствует случаю, когда ни при одном |
||||
измерении |
не наблюдается |
значение |
и, следовательно, |
||
система не |
может |
иметь |
состояние, |
характеризующееся |
|
параметром . Соответственно вероятность
возможна только, если |
при всех измерениях наблюдалось |
|
только значение . В |
этом случае, система находится в |
|
детерминированном состоянии с параметром . |
||
Сумма вероятностей |
нахождения системы во всех |
|
состояниях с параметрами |
равна единице: |
|
Рассмотренный нами случай, когда параметр, характеризующий систему, принимает набор дискретных значений не является типичным при описании систем.
Рассмотрим статистическое описание, применимое для случая, когда измеренный параметр х может иметь любые значения в некотором интервале . Причем, указанный интервал может быть и не ограниченным какими либо
конечными значениями |
и |
. В частности параметр х в |
||
принципе может изменяться от |
до + . |
|
|
|
Пусть в результате измерений было установлено, что |
||||
величина х с вероятностью |
попадает |
в интервал |
||
значений от х до х + dx. Тогда можно ввести функцию |
, |
|||
характеризующую плотность |
распределения |
вероятностей |
||
(probability density function (PDF)): |
|
|
||
43
Эта функция в физике обычно называется функцией
распределения. |
|
|
Функция |
распределения |
должна удовлетворять |
условию: |
, так как |
вероятность попадания |
измеренного значения в интервал от х до х + dx не может быть отрицательной величиной. Вероятность того, что измеренное значение попадет в интервал < х < равна
Соответственно, вероятность попадания измеренного значения в весь интервал возможных значений равна единице:
(2.1)
Выражение (2.1) называется условием нормировки функции распределения.
Когда при измерениях какой-либо величины вероятность получения того или иного значения обратна пропорциональна некоторой степени этого значения, говорят, что данная величина характеризуется степенным законом. Иногда также говорят о законе Зипфа или распределении Парето.
Рассмотрим кумулятивные распределения социальных систем различного рода. Все они следуют степенному распределению по меньшей мере в некоторой части диапазона.
Что впервые было замечено Прайсом [30], число цитирований, сделанных на те или иные научные статьи, соответствует степенному распределению (рис. 2.1). Данные взяты из «Индекса научного цитирования», составленного Реднером [31] для статей, опубликованных в 1981 году. Диаграмма представляет кумулятивное распределение числа
44

цитирований статей, сделанных с момента публикации статей до июня 1997 года.
Рис. 2.1. Число цитирований научных статей, которые были опубликованы в 1981 году, сделанных с момента
публикации до июня 1997 года
Кумулятивное распределение числа «хитов», полученных вебсайтами (то есть, серверами, а не отдельными веб-страницами) в течение одного дня, совершенных некоторым подмножеством пользователей интернет-провайдера AOL. (рис. 2.2). Сайтом, получившим с большим отрывом больше всего хитов является yahoo.com. Данные исследования Адамика и Губермана [30].
Рис. 2.2. Число хитов 60 тыс. пользователей интеренетпровайдера AOL, полученных веб-сайтами в течение одного
дня 1 декабря 1997 года
45
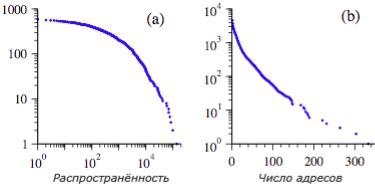
Как мы видим, степенные распределения удивительно широко распространены, однако они являются не единственной формой «широких» распределений. Поскольку могло сложиться впечатление, что все интересные распределения являются сте-пенными, позвольте подчеркнуть, что существует немало нату-ральных величин, обладающих скошенными влево распре-делениями, которые тем не менее не являются степенными распределениями. Вот несколько примеров (рис. 2.3):
Рис. 2.3. Кумулятивные распределения некоторых величин, распределения которых охватывают несколько порядков, но при этом не соответствуют степенному закону. (a) Число наблюдений североамериканских птиц, принадлежащих 591 виду по данным North American Breeding Bird Survey 2003.
(b) Число записей в адресных книгах электронной почты 16881 пользователей большой университетской компьютерной системы [32]
2.1.1. Распределение Парето
Анализируя общественные процессы, В. Парето (V. Pareto) рассмотрел социальную среду как пирамиду, на вершине которой находятся люди, представляющие элиту.
46
Парето в 1906 году установил, что около 80 процентов земли в Италии принадлежит лишь 20 процентам ее жителей. Он пришел к заключению, что параметры полученного им распределения приблизительно одинаковы и принципиально не различаются в разных странах и в разное время. Парето также установил, что точно такая же закономерность наблюдается и в распределении доходов между людьми, которое описывается
уравнением |
, где |
– величина дохода, |
- |
количество людей с доходом, равным или превышающим |
, |
||
и - параметры распределения. В математической статистике это распределение получило имя Парето, при этом
предполагаются естественные |
ограничения на |
параметры: |
. Распределению |
Парето присуще |
свойство |
устойчивости, т.е. сумма двух случайных переменных, которые имеют распределение Парето, также будет распределена по Парето. Замеченное распределение, называемое «законом Парето» или «принципом 80/20», применимо в очень многих областях. Например, при информационном поиске достаточно определить 20% важнейших ключевых слов, чтобы найти 80% необходимых документов, а затем расширить поиск или воспользоваться опцией "найти похожие" для полного решения задачи. Еще один пример: 80% посещений веб-сайта приходится лишь на 20% его веб-страниц.
При построении систем массового обслуживания, в том числе и информационно-поисковых систем, необходимо учитывать тот факт, что наиболее сложным функциональным возможностям системы, на реализацию которых уходит 80 и больше процентов трудозатрат, будут пользоваться не более чем 20 процентов пользователей данной системы.
Перейдем к более строгой формулировке закона Парето. Предположим, что последовательность соответствует размерам доходов отдельных людей. После
ранжирования этой последовательности по убыванию
получается |
новая последовательность |
(элементы |
расположены в порядке убывания). |
47

Предположим, что – общее число людей, у которых доход составляет не менее , т.е. . Тогда правило Парето можно переписать в таком виде:
Отсюда:
Рассматривается |
|
сумма первых |
||||
значений величины |
, то есть общая величина дохода |
|||||
наиболее богатых людей – |
составляет: |
|||||
|
|
|
|
|
|
|
где
Переходя от дискретных величин к непрерывным (предполагая, что ), имеем:
В безразмерных переменных |
- и |
последнее равенство имеет вид (см. рис. 2.4): |
|
Величина в нашем примере – относительное количество дохода, получаемого первыми по рангу людьми, доля которых (относительно всех людей) равна .
48
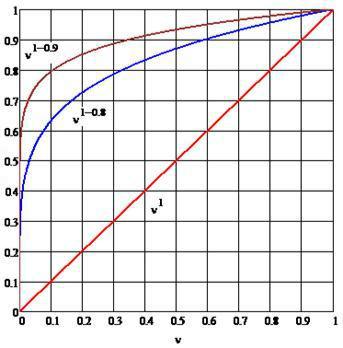
Для последних двух случаев, представленных на рис. 2.4, - 20% людей имеют - 80% доходов (близкие к этим значениям явления наблюдаются в реальной жизни).
Рис. 2.4. Распределение Парето для различных значений параметров: зависимость для трех случаев –
(доходы всех одинаковы) и
2.1.2. Законы Ципфа
Дж. Ципф (G. Zipf) изучал использование статистических свойств языка в текстовых документах и выявил несколько эмпирических законов, которые представил как эмпирическое доказательство своего «принципа наименьшего количества усилий». Он экспериментально показал, что распределение слов естественного языка подчиняется закону, который часто называют первым законом
49

Ципфа, относящимся к распределению частоты слов в тексте. Этот закон можно сформулировать таким образом. Если для какого-нибудь довольно большого текста составить список всех слов, которые встретились в нем, а потом ранжировать эти слова в порядке убывания частоты их появления в тексте, то для любого слова произведение его ранга и частоты появления
будет величиной постоянной: |
, |
где |
– частота |
встречаемости слова в тексте; |
– ранг |
слова в списке; – |
|
эмпирическая постоянная величина (коэффициент Ципфа). Для славянских языков, в частности, коэффициент Ципфа составляет приблизительно
0,06-0,07.
Приведенная зависимость отражает тот факт, что существует небольшой словарь, который составляет большую часть слов текста. Это главным образом служебные слова. Например, приведенный в [42] анализ романа «Том Сойер», позволил выделить 11.000 английских слов. При этом было обнаружено двенадцать слов (the, and, и др.), каждое из которых охватывает более 1 % лексем в романе. Закон Ципфа был многократно проверен на многих массивах. Ципф объяснял приведенное выше гиперболическое распределение «принципом наименьшего количества усилий» предполагая, что при создании текста меньше усилий уходит на повторение некоторых слов, чем на использование новых, т.е. на обращение к «оперативной памяти, а не к долговременной».
Ципф сформулировал еще одну закономерность, так называемый второй закон Ципфа, состоящий в том, что частота и количество слов, которые входят в текст с данной частотой, также связанны подобным соотношением, а именно:
где – количество различных слов, каждое из которых используется в тексте раз;
– константа нормирования.
50