

315
.pdfМинистерство образования и науки Российской Федерации
Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования «Пермский национальный исследовательский политехнический университет»
Кафедра «Автоматизация технологических процессов и производств»
РАЗРАБОТКА ИНФОРМАЦИОННОЙ МОДЕЛИ
ИОБМЕН ДАННЫМИ ОБ ИЗДЕЛИИ
ВФОРМАТЕ ISO 10303 STEP
Методические указания к лабораторной работе
Издательство Пермского национального исследовательского
политехнического университета
2013
elib.pstu.ru
Составитель канд. техн. наук, доцент С.Н. Кондрашов
УДК 658.012:004.42 Р17
Рецензент д-р техн. наук, профессор А.Г. Шумихин
(Пермский национальный исследовательский политехнический университет)
Разработка информационной модели и обмен данными Р17 об изделии в формате ISO 10303 STEP : метод. указания к лаборат. работе / сост. С.Н. Кондрашов. – Пермь : Изд-во Перм.
нац. исслед. политехн. ун-та, 2013. – 31 с.
Изложены общие положения, структура и базовые инструменты стандарта ISO 10303 STEP, метод описания – язык концептуальных данных EXPRESS, метод реализации – символьный обменный файл STEP. Описана работа с программными модулями: компиля-
тором Express compiler.exe, загрузчиком словарей Dictionary loader.exe.
Предназначены для студентов специальностей «Автоматизация технологических процессов и производств», «Компьютерные системы качества» очной и заочной форм обучения.
УДК 658.012:004.42
© ПНИПУ, 2013
2
elib.pstu.ru
СОДЕРЖАНИЕ |
|
1. Стандарт ISO 10303 STEP. Основные теоретические |
|
положения.......................................................................................... |
4 |
1.1. Структура стандарта ISO 10303 STEP ...................................... |
5 |
1.2. Базовые инструменты ISO 10303 STEP .................................... |
7 |
1.3. Метод описания: язык концептуальных |
|
схем данных Express................................................................. |
11 |
1.4. Метод реализации: символьный обменный файл STEP........ |
16 |
2. Работа с программными модулями................................................. |
20 |
2.1. Начало работы........................................................................ |
20 |
2.2. Работа компилятора Express compiler.exe ............................ |
20 |
2.3. Работа загрузчика словарей Dictionary loader.exe ............... |
23 |
3. Порядок выполнения работы........................................................... |
25 |
Контрольные вопросы.......................................................................... |
30 |
3
elib.pstu.ru
1. СТАНДАРТ ISO 10303 STEP.
ОСНОВНЫЕ ТЕОРЕТИЧЕСКИЕ ПОЛОЖЕНИЯ
Цель международного стандарта ISO 10303 для компьютерного представления данных о продукте и обмена ими (неофициальное название – Standard for the Exchange of Product data, STEP) – дать механизм описания данных о продукте на всех стадиях его жизненного цикла, не зависящий от конкретной системы. Природа такого описания делает его подходящим не только для нейтрального файла обмена, но и в качестве базиса для реализации и распространения баз данных о продукте, а также для архивирования.
STEP – это стандарт, который предназначен для хранения данных об изделии, в том числе информации о составе изделия, его структуре, геометрических моделях, свойствах и характеристиках. Созданная однажды модель изделия используется многократно. В нее вносятся дополнения и изменения, она служит отправной точкой при модернизации изделия. Модель изделия в соответствии с этим стандартом включает в себя: геометрические данные, информацию о конфигурации изделия, данные об изменениях, согласованиях и утверждениях в проекте.
а |
б |
Рис. 1. Информационная среда: а – непосредственный обмен данными между приложениями; б – обмен данными через нейтральный стандарт
4
elib.pstu.ru
Преимущество единого стандарта состоит в возможности легко организовать информационный обмен между всеми компьютерными системами, которые используются в течение жизненного цикла изделия (рис. 1). В случае отсутствия единого стандарта информационный обмен будет идти между каждой парой компьютерных систем, что имеет существенные недостатки: невозможность создания интегрированной модели изделия; необходимость приобретения большого количества конвертеров форматов – N(N – 1) штук, где N – количество используемых компьютерных систем.
В случае применения стандарта STEP количество конвертеров сокращается до 2N штук. Кроме того, STEP имеет статус международного стандарта, что облегчает взаимодействие с зарубежными партнерами.
1.1. Структура стандарта ISO 10303 STEP
Структуру STEP можно условно представить схемой, состоящей из трех уровней (рис. 2):
1.Первый уровень является ядром стандарта и содержит инструментарий STEP, с помощью которого задаются остальные компоненты, а также реализуется информационный обмен.
2.На втором уровне находится базовое представление информации об изделии, независимое от предметной области. Оно включает в себя базовую информационную модель изделия, заданную
спомощью инструментария STEP.
3.Наконец, третий уровень содержит представление информации об изделии, специфичное для конкретной предметной области. Оно характеризует информационную модель изделия для конкретной предметной области и опирается как на инструментарий STEP (первый уровень), так и на базовую модель изделия (второй уровень).
5
elib.pstu.ru
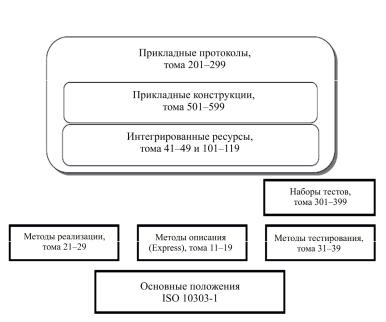
Рис. 2. Структура стандарта ISO 10303 STEP
Методы описания предназначены для всех информационных моделей в STEP. Они позволяют задать структуру данных, которой описывается изделие. Основа методов описания – язык концепту-
альных схем данных Express (ISO 10303-11).
Методы реализации используются для представления модели изделия в соответствии со STEP. Они позволяют организовать обмен или хранение информации, представленной с помощью методов описания STEP. Экземпляры данных могут быть представлены в символьном обменном файле STEP в соответствии с ISO 10303-21 или в некотором источнике данных (репозитории STEP) в соответствии с ISO 10303-22, чаще всего – в двоичном виде и в виде фай-
лов XML.
Каждая из трех форм представления знака имеет свои преимущества и недостатки:
6
elib.pstu.ru
|
Символьный |
Файл XML |
Репозиторий |
|
обменный файл |
данных STEP |
|
|
|
||
|
Независимость |
Доступность |
Хорошие возмож- |
|
от программной |
для программной |
ностикомпью- |
|
и аппаратной |
обработки боль- |
тернойобработки |
|
платформ, дос- |
шим количеством |
|
Преимущества |
тупность для |
браузеров без |
|
|
чтения и редакти- |
использования |
|
|
рования вручную |
специализирован- |
|
|
|
ных инструмен- |
|
|
|
тов STEP |
|
|
Сложность про- |
Неполное ото- |
Зависимость |
Недостатки |
граммной обра- |
бражение всех |
от программной |
ботки |
особенностей мо- |
и аппаратной |
|
|
|
делей STEP |
платформ |
Методология тестирования определяет основные принципы тестирования различных программных средств на соответствие стандарту STEP.
Интегрированные ресурсы задают базовое представление информации об изделии, независимые от предметной области. Они являются основой при построении протокола применения.
Протокол применения определяет специфичное для конкретной предметной области представление информации об изделии как основу для обмена данными, построенную на базе интегрированных ресурсов STEP.
1.2. Базовые инструменты ISO 10303 STEP
Все данные формата ISO 10303 STEP предназначены для программной обработки, следовательно, они должны быть формализованы. Рассмотрим принятые в STEP средства формализации определений данных (методы описания) и средства формализации представлений экземпляров данных (методы реализации). Для формального описания синтаксиса языка Express и обменного файла STEP будет использоваться синтаксическая нотация Вирта (Wirth Syntax Notation – WSN).
7
elib.pstu.ru
Встандарте ISO 10303 STEP синтаксическая нотация Вирта принята в качестве инструмента, применяемого для всех используемых в стандарте формальных грамматик.
Грамматика определяется четырьмя компонентами:
– Vt-алфавит, символы которого называются терминальными – это либо предопределенные имена, либо цепочки – последовательности символов в кавычках или апострофах;
– Vn-алфавит, символы которого называются нетерминальными. Каждый нетерминальный символ состоит из одного или более терминальных и/или нетерминальных символов, сочетание которых определяется правилами грамматики.
Vt и Vn не имеют общих символов. Полный алфавит (словарь) грамматики V определяется как объединение Vt и Vn.
P – набор порождающих правил (выводов), каждый элемент которых состоит из пары (а, b), где a находится в Vt, а b – в Vn, а – левая часть правила, b – правая, т.е. цепочки, построенные из символов алфавита V. Правило записывается как а = b.
S принадлежит Vn и называется начальным символом (аксиомой). Этот символ – отправная точка в получении любого предложения языка.
Внотации Вирта приняты следующие обозначения:
–знак равенства «=» означает вывод. Определено, что элемент слева должен быть комбинацией элементов справа. Любые пробелы, появляющиеся между элементами вывода, не являются значащими, если они появляются не внутри литерала;
–вывод завершается точкой «.»;
–фигурные скобки «{…}» означают нуль или более повторе-
ний;
–квадратные скобки «[…]» означают необязательный пара-
метр;
–вертикальная линия «|» означает логическое ИЛИ;
–скобки «(…)» показывают приоритет операций. В частности,
там, где скобки включают в себя элементы, разделенные вертикаль-
8
elib.pstu.ru
ными линиями, один из элементов должен быть выбран в сочетании с любой другой операцией, например A(B|C|D) = AB|AC|AD.
Рассмотрим формальную грамматику, описывающую вещественные числа. Вещественное число записывается как знак, за которым следует значение. Знак и значение являются нетерминальными символами, т.е. входят в множество Vn.
вещественное_число = [знак] значение. – WSN-1.
Знак является необязательным элементом, поскольку положительные вещественные числа, как правило, записываются без знака числа, поэтому записывается в квадратных скобках. Он раскрывается как один из двух литералов «+» и «–», которые определяют сами себя и далее не раскрываются, т.е. входят в множество терминальных символов Vt:
знак = «+» | «–». – WSN-2.
Значение вещественного числа состоит в общем случае из целой части, дробной части и экспоненты. Наличие экспоненты допускается не во всех системах, работающих с вещественными числами, но поскольку мы рассматриваем самый общий случай, охватывающий все возможные варианты, введем экспоненту во множество нетерминальных символов Vn. Тогда вывод для значения имеет вид
значение = [целая_часть] [дробная_часть] [экспонента]. –
WSN-3.
Как видим, из данного вывода следует возможность существования пустых значений (все символы являются необязательными). Во избежание этого можно сделать более сложный, но более корректный вывод:
значение = целая_часть | дробная_часть | экспонента | (целая_часть дробная_часть) | (дробная_часть экспонента) | (целая_часть экспонента) | (целая_часть дробная_часть экспонен-
та). – WSN-4.
Далее по порядку раскроем нетерминальные символы. Целая часть представляется следующим выводом:
9
elib.pstu.ru
целая_часть = {цифра}. – WSN-5.
Если принять, что в целой части обязательно должна быть хотя бы одна цифра, то имеем второй вариант вывода:
целая_часть = цифра {цифра}. – WSN-6.
дробная_часть = «.» {цифра}. – WSN-7.
На случай, если символ экспоненты будет представлен как буквой нижнего регистра, так и буквой верхнего регистра, приведем для экспоненты наиболее полный вывод. Здесь учитывается также то, что может отсутствовать знак экспоненты, хотя в большинстве грамматик, описывающих вещественные числа, он является обязательным:
экспонента = «e» | «E» [знак] цифра {цифра}. – WSN-8.
Остается сделать вывод для символа «цифра». Такой вывод очевиден, но для полноты грамматики его стоит привести:
цифра = «0» | «1» | «2» | «3» | «4» | «5» | «6» | «7» | «8» | «9». –
WSN-9.
Приведем общие определения, которые будут использоваться в грамматиках текста языка EXPRESS и в символьном обменном файле.
Прежде всего, это цифры:
digit = «0» | «1» | «2» | «3» | «4» | «5» | «6» | «7» | «8» | «9». – WSN-10.
В некоторых случаях допускается использование только букв верхнего регистра, поэтому имеет смысл дать отдельные определения для букв верхнего (upper) и нижнего (lower) регистров и общее определение чувствительной к регистру буквы (letter):
upper = «A» | «B» | «C» | «D» | «E» | «F» | «G» | «H» | «I» | «J» | «K» | «L» | «M» | «N» | «O» | «P» | «Q» | «R» | «S» | «T» | «U» | «V» | «W» | «X» | «W» | «Z». – WSN-11.
lower = «a» | «b» | «c» | «d» | «e» | «f» | «g» | «h» | «i» | «j» | «k» | «l» | «m» | «n» | «o» | «p» | «q» | «r» | «s» | «t» | «u» | «v» | «w» | «x» | «w» | «z». – WSN-12.
letter = upper | lower. – WSN-13.
10
elib.pstu.ru