

5335
.pdf61
P1 = 0.5:2.5;
Y = sim(net, P1);
plot(P1,V, ′+k′, ′MarkerSize′, 10, ′LineWidth′, 2)
Y = sim(net, 0:0.5:3) – для нового входа;
net = newgrnn(P, T, 0.1) – параметр SPREAD = 0.1; Y = sim(net, 0:0.5:3)% – сравнить результаты.
Задание 4. Построить обобщённую регрессионную сеть для решения задачи
аппроксимации и экстраполяции нелинейной зависимости, восстанавливаемой по экспериментальным точкам, выполнив следующие команды:
P = [1 2 3 4 5 6 7 8 ]; |
– экспериментальные; |
T = [0 1 2 3 2 1 2 1 ]; |
– данные в 8 точках; |
SPREAD = 0.7; |
– значение меньше шага Р, равного 1; |
net = newgrnn(P, T, SPREAD) net.layers{1}.size, net.layers{2}.size - 8 и 8; A = sim(net, P);
plot(P, T, ′*k′, ′MarkerSize′, 10), hold on
plot(P, A, ′ok′, ′MarkerSize′, 10) |
– аппроксимация; |
|
P2 = -1: 0.1: 10; |
– диапазон Р2 больше диапазона Р; |
|
A2 = sim(net, P2); |
|
|
plot(P2, A2, ′-k′, ′LineWidth′, 2) |
– экстраполяция; |
|
hold on, |
|
|
plot(P, T, ′*k′, ′MarkerSize′, 10) |
– сравнить точки. |
|
Пример выполнения Лабораторной работы 5
Функция newrb создаёт радиальную базисную сеть и имеет следующий синтаксис:
net=newrb(P, T, goal, spread),
где P – матрица Q входных векторов размерности R на Q;
T – матрица Q векторов целевых классов S на Q;
goal – средняя квадратичная ошибка, по умолчанию 0,0;
62
spread – разброс радиальной базисной функции, по умолчанию 1,0.
Радиальные базисные сети используются для аппроксимации функций. Функция newrb конструирует скрытый слой из радиальных базисных нейронов и использует значение средней квадратичной ошибки.
В среде Matlab создание радиальной базисной сети выглядит так: net=newrbe(P, T, spread).
Функция newrbe проектирует радиальную базисную сеть с нулевой ошибкой для заданных векторов.
Нейронная сеть регрессии – это вид радиальной базисной сети, которая часто используется для аппроксимации функций и быстро строит сеть для аппроксимации:
net=newgrnn(P, T, spread).
Вероятностная нейронная сеть – это вид радиальной базисной сети, как и нейронная сеть регрессии, данные сети используются для решения задач классификации. Выглядит она так:
net=newpnn(P, T, spread).
Создание и обучение нейронной сети регрессии
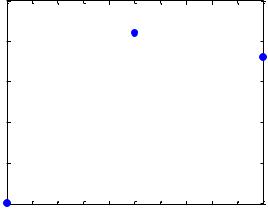
P=[1 2 3]; T=[3.0 5.1 4.8]; Spread=0.8;
net=newgrnn(P, T, Spread); A=sim(net, P); \\ имитация работы НС
plot(P, T, '.', 'markersize', 30); – см. рисунок 34.
5.5
5
4.5
4
3.5
3 |
|
|
|
|
|
|
|
|
|
|
1 |
1.2 |
1.4 |
1.6 |
1.8 |
2 |
2.2 |
2.4 |
2.6 |
2.8 |
3 |
Рисунок 34 – Аппроксимируемая функция
63
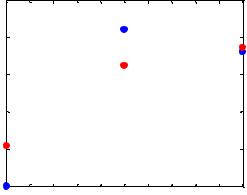
hold on; \\ установка режима добавления графиков на координатные оси plot(P, A, '.', 'markersize', 30, 'color', [1 0 0]); – см. рисунок 35.
5.5
5
4.5
4
3.5
3 |
|
|
|
|
|
|
|
|
|
|
1 |
1.2 |
1.4 |
1.6 |
1.8 |
2 |
2.2 |
2.4 |
2.6 |
2.8 |
3 |
Рисунок 35 – Необученная НС регрессии
cla reset; \\ очистка координатных осей p=4.5; \\ установка нового входа
a=sim(net, p); \\ получение отклика НС регрессии plot(P, T, '.', 'markersize', 30);
axis([0 9 -1 4]); \\ установка диапазонов осей X и Y hold on;
plot(p, a, '.', 'markersize', 30, 'color', [1 0 0]); title('Новый входной вектор');
xlabel('P and p'); ylabel('T and a'); cla reset;
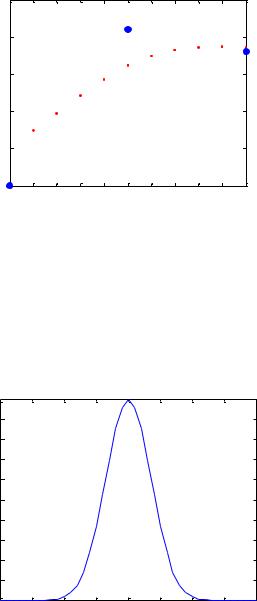
P2=0 : .2 : 9; \\ определить последовательность векторов P2
Сымитируем отклик сети для различных значений, чтобы увидеть результат
аппроксимации (рисунок 36).
A2=sim(net, P2);
plot(P2, A2, '.', 'linewidth', 30, 'color', [1 0 0]);
hold on;
plot(P, T, '.', 'markersize', 30);
axis([0 9 -1 4]);
64
title('Аппроксимируемая функция'); xlabel('P and P2');
ylabel('T and A2');
Аппроксимируемая функция
5.5
5
4.5
T and A2
4
3.5
31 |
1.2 |
1.4 |
1.6 |
1.8 |
2 |
2.2 |
2.4 |
2.6 |
2.8 |
3 |
|
|
|
|
|
P and P2 |
|
|
|
|
|
Рисунок 36 – Аппроксимация точек с помощью НС регрессии
Использование радиальной базисной нейронной сети для аппроксимации функций
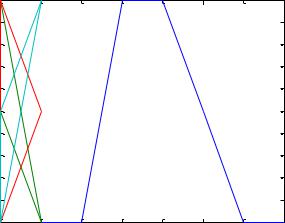
p=-4 : .2 : 4; \\ определение диапазонов значений РБФ a=radbas(p); \\ вычислениеРБФ на диапазоне р
plot(p, a);
1 |
|
|
|
|
|
|
|
|
0.9 |
|
|
|
|
|
|
|
|
0.8 |
|
|
|
|
|
|
|
|
0.7 |
|
|
|
|
|
|
|
|
0.6 |
|
|
|
|
|
|
|
|
0.5 |
|
|
|
|
|
|
|
|
0.4 |
|
|
|
|
|
|
|
|
0.3 |
|
|
|
|
|
|
|
|
0.2 |
|
|
|
|
|
|
|
|
0.1 |
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
-4 |
-3 |
-2 |
-1 |
0 |
1 |
2 |
3 |
4 |
Рисунок 37 – Радиальная базисная функция
P=-1 : .1 : 1;
T=[-.6662 -.3766 -.1129 .2111 .6565 .3301 .3649 .2006 -.1913 -.3994 -.5022 -.4531 -
.1133 .0866 .3333 .4955 .3488 .2833 -.1112 -.6685 -.3255]; plot(P, T, '*');
title('Обучающая выборка');
xlabel('P and P2');
ylabel('T and A2');

65
Обучающая выборка
|
0.8 |
|
|
|
|
0.6 |
|
|
|
|
0.4 |
|
|
|
T |
0.2 |
|
|
|
|
|
|
|
|
Вектор |
0 |
|
|
|
|
|
|
|
|
|
-0.2 |
|
|
|
|
-0.4 |
|
|
|
|
-0.6 |
|
|
|
|
-0.8 |
|
|
|
|
-1 |
-0.8 |
-0.6 |
-0.4 |
-0.2 |
0 |
0.2 |
0.4 |
0.6 |
0.8 |
1 |
Входной вектор P |
|
|
|
|||
Рисунок 38 – Аппроксимируемая функция, заданная как набор точек
goal=0.02;
spread=1;
net=newrb(P, T, goal, spread); \\ создание РБФ
X=-1 : .01 : 1; \\ определение вектора входов
Сымитируем работу сети.
Y=sim(net, X); hold on; plot(X, Y); hold off;
|
|
|
|
Обучающая выборка |
|
|
|
|||
|
0.8 |
|
|
|
|
|
|
|
|
|
|
0.6 |
|
|
|
|
|
|
|
|
|
|
0.4 |
|
|
|
|
|
|
|
|
|
T |
0.2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Вектор |
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-0.2 |
|
|
|
|
|
|
|
|
|
|
-0.4 |
|
|
|
|
|
|
|
|
|
|
-0.6 |
|
|
|
|
|
|
|
|
|
|
-0.8 |
|
|
|
|
|
|
|
|
|
|
-1 |
-0.8 -0.6 |
-0.4 |
-0.2 |
0 |
0.2 |
0.4 |
0.6 |
0.8 |
1 |
|
|
|
|
Входной вектор P |
|
|
|
|||
Рисунок 39 – Результат аппроксимации с помощью РБНС |
||||||||||
66
Использование вероятностной нейронной сети для классификации
векторов
P=[1 2 3 4 5 6 7]; \\ определение входов
Tc=[1 1 3 3 2 1 1]; \\ определение желаемых входов
T=ind2vec(Tc); \\ конвертирование индексов в векторы, содержащие 1 в
индексных позициях net=newpnn(P, T); \\ создание ВНС
Y=sim(net, P);
Yc=vec2ind(Y); \\ конвертирование номеров классов в векторы plot(P, Tc, Y, Yc); – см. рисунок 40.
3 |
|
|
|
|
|
|
|
|
2.8 |
|
|
|
|
|
|
|
|
2.6 |
|
|
|
|
|
|
|
|
2.4 |
|
|
|
|
|
|
|
|
2.2 |
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
1.8 |
|
|
|
|
|
|
|
|
1.6 |
|
|
|
|
|
|
|
|
1.4 |
|
|
|
|
|
|
|
|
1.2 |
|
|
|
|
|
|
|
|
1 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
Рисунок 40 – Вероятностная нейронная сеть |
||||||||
2.6. Лабораторная работа 6
Тема: Изучение сетей Кохонена и алгоритма обучения без учителя
Цель работы – изучить алгоритм обучения без учителя на примере задачи кластеризации, алгоритм «победителя» Кохонена.
Теоретические сведения
Исследование самоорганизующихся слоев Кохонена Самоорганизующаяся карта Кохонена (англ. Self-organizing map — SOM)
— соревновательная нейронная сеть с обучением без учителя, выполняющая задачу визуализации и кластеризации. Метод был предложен финским учёным
67
Тойво Кохоненом в 1984 году. Самоорганизующийся слой Кохонена – это однослойная нейронная сеть с конкурирующей передаточной функцией compet,
которая анализирует выходные значения нейронов слоя и выдаёт в качестве результата наибольшее из этих значений (значение нейрона-победителя).
Инициализация весов входов производится с помощью функции средних значений
W = midpoint (S,PR),
где S – число нейронов в слое Кохонена; |
|
||||
PR – матрица размера Rx2, задающая диапазоны p j |
, p j изменения R |
||||
|
|
|
|
min |
max |
элементов входного вектора; |
|
||||
W – матрица весов размера SxR для входов слоя, столбцы которой имеют |
|||||
|
p j |
p j |
. |
|
|
значение |
min |
max |
|
||
|
2 |
|
|
||
|
|
|
|
|
|
Инициализация весов смещений нейронов слоя |
производится с |
||||
помощью функции равных смещений |
|
||||
B = initcon(S,PR),
которое каждому нейрону задаёт одно и то же смещение, равное exp(1)*S.
Например, для S=5 это смещение равно 5*2.71828=1.359740*101.
Взвешивание входов слоя Кохонена реализуется в виде отрицательного евклидова расстояния между каждой строкой Wi матрицы весов W и каждым столбцом Pj матрицы входов P, которое вычисляется функцией negdist(W,P).
Суммирование взвешенных входов со смещениями производится функцией
netsum.
Формирование самоорганизующегося слоя Кохонена осуществляется функцией
net = newc(PR,S,KLr,clr),
где KLr – параметр функции настройки весов, значение по умолчанию,
которого равно 0.01;
clr – параметр функции настройки смещений, значение по умолчанию,
которого равно 0.001.
Эта функция формирует однослойную сеть с R нейронами и R входами.
68
Веса входов устанавливаются равными половине диапазона соответствующего вектора входа для всех нейронов. Также для всех нейронов устанавливается одно и то же смещение, равное e*s. Выходы нейронов поступают на конкурирующую передаточную функцию compet, которая определяет победителя. Номер активного нейрона-победителя I* определяет ту группу (кластер), к которой наиболее близок входной вектор.
Для того чтобы сформированная таким образом сеть решала задачу кластеризации данных, необходимо предварительно настроить её веса и смещения по обучающей последовательности векторов с помощью функций настройки learnk и learncon соответственно, используя процедуру адаптации adapt или процедуру обучения train.
Функция learnk рассчитывает приращение весов dW в зависимости от вектора входа P, выхода а, весов w и параметра скорости настройки lr в
соответствии с правилом Кохонена:
lr * ( p' w), a j |
0; |
|
dw |
0, a j 0. |
|
|
|
|
Таким образом, вектор веса, |
наиболее |
близкий к вектору входа, |
модифицируется так, чтобы расстояние между ними стало ещё меньше.
Результат такого обучения заключается в том, что победивший нейрон,
вероятно, выиграет конкуренцию и в том случае, когда будет представлен новый входной вектор, близкий к предыдущему, и его победа менее вероятна, когда будет представлен вектор, существенно отличающийся от предыдущего. Когда на вход сети поступает всё большее и большее число векторов, нейрон,
являющийся ближайшим, снова корректирует свой весовой вектор w. В
конечном счёте, если в слое имеется достаточное количество нейронов, то каждая группа близких векторов окажется связанной с одним из нейронов слоя.
В этом и заключается свойство самоорганизации слоя Кохонена.
Одно из ограничений всякого конкурирующего слоя состоит в том, что некоторые нейроны оказываются незадействованными, или “мертвыми”. Это происходит оттого, что нейроны, имеющие начальные весовые векторы,
значительно удаленные от векторов входа, никогда не выигрывают
69
конкуренции, независимо от продолжительности обучения. Для ликвидации нечувствительности таких нейронов используют положительные смещения,
которые добавляются к отрицательным расстояниям удаленных нейронов.
Функция learncon производит такую корректировку смещений следующим образом.
В начале процедуры настройки сети всем нейронам присваивается одинаковый характер активности C0 = 1/S. В процессе настройки эта величина для активных нейронов увеличивается, а для неактивных нейронов уменьшается:
ΔC = lr (a −c) .
Нетрудно убедиться, что для всех нейронов, кроме нейрона победителя,
приращения отрицательны. Функция learcon рассчитывает приращения вектора смещений следующим образом:
b =exp(1−log(c)) −b .
Увеличение смещений для неактивных нейронов позволяет расширить диапазон покрытия входных значений, и неактивный нейрон начинает формировать кластер, что улучшает кластеризацию входных данных.
Самоорганизующаяся карта Кохонена – это однослойная нейронная сеть без смешения с конкурирующей функцией compet, имеющая определённую топологию размещения нейронов в N-мерном пространстве. В отличие от слоя Кохонена карта Кохонена после обучения поддерживает такое топологическое свойство, когда близким входным векторам соответствуют близко расположенные активные нейроны.
Первоначальная топология размещения нейронов в карте Кохонена формируется при создании карты с помощью функции newsom, одним из параметров которого является имя топологической функции gridtop, nextop
или randtop, что соответствует размещению нейронов в узлах либо прямоугольной, либо гексагональной сетки, либо в узлах сетки со случайной топологией.
Расстояния между нейронами и векторами входов вычисляются с помощью
70
следующих функций:
dist – евклидово расстояние d=sqrt((posi-pj).^2); boxdist – максимальное координатное смещение
d=max(abs(posi-pj));
mandist – расстояние суммарного координатного смещения
d=sum(abs(posi-pj));
linkdist – расстояние связи
|
|
p j ) 1;% евклидово пространство; |
|||||
1, dist( posi |
|||||||
|
2, k, dik1 |
d kj 1;% один |
|
|
промежуточный; |
||
|
|
|
|||||
|
3, k1 , k2 , di k1 d k k |
|
|
|
d k j 1; |
||
dij |
|
1 |
|
21 |
1 |
||
|
|
|
|||||
.......... .......... .......... .......... .......... .......... .......... .......... ... |
|||||||
|
N , (k1 , k2 ...kn ), di k1 d k k |
|
... d knj 1; |
||||
|
|
||||||
|
|
1 |
|
2 |
|
||
|
|
|
|
|
|||
|
|
S, в остальных |
|
|
случаях |
||
|
|
|
|
|
|
|
|
Формирование самоорганизующейся карты Кохонена осуществляется функцией
net=newsom(PR,[d1, d2,…],tfcn, dfсn, olr, osteps, tlr, tnd)),
где Pr – массив размера R*2 минимальных значений векторов входа;
d1, d2…– число нейронов по i-й размерности карты. По умолчанию – двумерная карта с числом нейронов 5*8;
tfсn – функция топологии карты, по умолчанию nextop; dfcn – функция расстояния, по умолчанию linkdist;
olr – параметр скорости обучения на этапе размещения, по умолчанию 0.9; osteps – число циклов обучения на этапе подстройки, по умолчанию 1000; tlr – параметр скорости на этапе подстройки, по умолчанию 0.02; tnd –
размер окрестности на этапе подстройки, по умолчанию 1. Настройка карты Кохонена производится по каждому входному вектору независимо от того, применяется метод адаптации или метод обучения. В любом случае функция learnsom выполняет настройку карты нейронов.
Прежде всего, определяется нейрон-победитель и корректируется его вектор весов и векторы соседних нейронов согласно соотношению