

Международная телекоммуникатсионная конферентсия Молодеж и наука Ч.3 2015
.pdfАвтоматизированные системы обработки информации и управления
М.Д. АСЕЕВ, С.А. НЕМЕШАЕВ, А.П. НЕСТЕРОВ Научный руководитель – Б.А. ЩУКИН, д.т.н., профессор
Национальный исследовательский ядерный университет «МИФИ»
ПРИМЕНЕНИЕ КОМБИНИРОВАННЫХ МЕТОДОВ АНАЛИЗА ВРЕМЕННЫХ РЯДОВ ДЛЯ ЗАДАЧ
ФИНАНСОВОГО СЕКТОРА
В докладе рассматриваются различные математические модели прогнозирования временных рядов с целью создания собственной комплексной модели для высокоточного прогноза изменения различных финансовых показателей. Создаваемая модель позволит сократить затраты финансовых организаций и увеличить эффективность использования денежных средств.
Анализ временных рядов – один из наиболее востребованных разделов прикладной статистики. Под временным рядом понимается последовательность значений некоторого протекающего во времени процесса [1]. Примерами таких рядов являются биржевые индикаторы, цены на опционы, цены на недвижимость, объёмы продаж, снятия/внесения наличности банковскими клиентами и т.п.
Основной целью анализа временных рядов является прогнозирование, т.е. предсказание будущих значений на основе настоящих и предыдущих статистических данных [2]. Особенно остро данный вопрос стоит в финансовом секторе. Неэффективно составленный прогноз приводит к большим убыткам финансовых организаций. В связи с этим создание универсальной модели прогнозирования является как никогда актуальным.
Для построения качественного прогноза необходим большой объём статистических данных. Обладая широким диапазоном статистической информации, можно качественно проанализировать основные явления временного ряда: тренд, сезонность, цикличность, случайный шум [3]. Выделение и исследование данных характеристик лежат в основе различных методов статистического анализа.
Впроцессе финансового прогнозирования для расчёта финансовых показателей используются специфические методы, например, построение регрессионных и авторегрессионных моделей, использование стохастических методов и моделей скользящего среднего.
Входе исследования данных о снятиях денежных средств с пластиковых карт крупного коммерческого банка в Екатеринбурге в период с 1
_______________________________________________________________________
ISBN 978-5-7262-2223-3. XIХ конференция «Молодежь и наука» |
211 |

Автоматизированные системы обработки информации и управления
января по 2 сентября 2014 года были использованы следующие математические модели:
Линейные и полиномиальные регрессионные модели;
Модели экспоненциального сглаживания (Брауна, Хольта, ХольтаУинтерса, Тейла-Вейджа);
ARIMA (англ. Autoregressive Integrated Moving Average) – интегри-
рованная модель авторегрессии — скользящего среднего.
Можно сделать вывод, что использование одной конкретной модели прогнозирования не позволяет эффективно предсказывать будущие значения исследуемого временного ряда.
Результаты проведённых расчётов показывают, что можно существенно увеличить эффективность управления денежными потоками данного банка до 35%, а именно повысить качество прогнозирования доставки и вывоза наличности из дополнительных офисов банка, торговых точек.
Всоответствии с проведёнными анализом и исследованиями было принято решение о разработке инновационной модели прогнозирования, учитывающей достоинства и недостатки вышеуказанных методов. Модель строится на основе аддитивного весового критерия, позволяющего провести комбинирование атомарных моделей. Для предсказания динамики спроса в данном случае используются методы работы с большими массивами данных (Big Data) с предобработкой по реконструкции аттрактора, что позволяет определить влияние неявных факторов. Создание комбинированной модели в данном ключе является новым решением и может стать эффективным способом минимизации затрат финансовых организаций.
Вкачестве инструментов анализа данных использовались следующие пакеты:
STATISTICA 13;
Anaconda (дистрибутив языка Python);
RStudio (IDE языка программирования R).
Для реализации комплексной модели была выбрана платформа Java 7 EE, позволяющая создавать надёжные кроссплатформенные приложения.
Список литературы
1.Бабешко, Л.О. Основы эконометрического моделирования: учебное пособие — 5-е изд. — Москва: Ленанд, 2015. — 428 с.
2.Профессиональный информационно-аналитический ресурс, посвящённый машинному обучению, распознаванию образов и интеллектуальному анализу данных [электронный ресурс] // URL: http://www.machinelearning.ru. (дата обращения: 28.11.2015).
212 |
ISBN 978-5-7262-2223-3. XIХ конференция «Молодежь и наука» |

Автоматизированные системы обработки информации и управления
К.Д. КРУГЛОВ, Е.С. ЯКОВЛЕВ Научный руководитель – И.В. АШАРИНА, к.т.н., доцент
Национальный исследовательский университет «МИЭТ»
ВЫДЕЛЕНИЕ КОМПЛЕКСОВ В МНОГОМАШИННОЙ ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЕ
В работе представлены способы реализации алгоритмов выделения комплексов, описываемых в [1, 2]. Были разработаны форматы представления входныхвыходных данных и способы представления графовой модели многомашинных вычислительных систем (МВС). Также выполнена программная реализация алгоритмов, обеспечивающих выделение комплексов в динамически реконфигурируемой сети.
Достижение согласованности действий различных ЦВМ системы в условиях возникновения допустимых неисправностей, формулируемое как проблема достижения взаимного информационного согласования
(ВИС) [3], является важнейшим аспектом при организации многозадачных параллельных вычислений в необслуживаемых многомашинных вычислительных системах (МВС). Обеспечение достоверности проводимых вычислений в таких системах гарантируется применением метода репликации задач, выполняемых системой. В работе используется модель
враждебной неисправности ЦВМ.
Комплексом называется группа ЦВМ, выполняющих репликацию задачи. Многокомплексная МВС – это отказоустойчивая МВС, в которой разными комплексами одновременно выполняются различные прикладные задачи, обменивающиеся данными путем использования сред межкомплексного обмена. В [1, 2] описана задача, в следующей постановке: имеется динамически реконфигурируемая сеть, в которой строится система, решающая параллельно несколько взаимодействующих задач. Каждая задача имеет свою степень отказоустойчивости и решается на специально выделенном комплексе, способном обеспечить эту степень отказоустойчивости. Итогом проделанной работы является программа, которая обеспечивает выделение комплексов в динамически реконфигурируемой сети.
Список литературы
1.Ашарина И.В., Лобанов А.В. Выделение структурной среды системного взаимного информационного согласования в многокомплексных системах // Автоматика и телемеханика. 2014. №6. С.115–131.
2.Ашарина И.В., Лобанов А.В. Выделение комплексов, обеспечивающих достаточные структурные условия системного взаимного информационного согласования в многокомплексных системах // Автоматика и телемеханика. 2014. №8. С.146–156.
_______________________________________________________________________
ISBN 978-5-7262-2223-3. XIХ конференция «Молодежь и наука» |
213 |

Автоматизированные системы обработки информации и управления
П.В. НОВИКОВА Научный руководитель – А.Л. САПУНЦОВ, к.эк.н., доцент
Национальный исследовательский ядерный университет «МИФИ»
АВТОМАТИЗИРОВАННЫЙ СИСТЕМНЫЙ АНАЛИЗ РЫНКА ЦЕННЫХ БУМАГ: ВЫЯВЛЕНИЕ СВЯЗИ СДЕЛОК
СОТМЫВАНИЕМ ДЕНЕЖНЫХ СРЕДСТВ
Вданной работе рассматривается пример использования метода главных компонент для определения весомости критериев подозрительности сделок, на рынке ценных бумаг.
Благодаря стремительному развитию информационных технологий, что позволило увеличить скорость осуществления транзакций, всемирный охват и способность к адаптации, рынок ценных бумаг стал очень привлекательным для использования в противозаконных целях, в том числе, для отмывания денег и финансирования терроризма, а также манипулированию в целях повышения или понижения котировок ценных бумаг.
Предметом работы является анализ признаков сделок, вызывающих подозрение в отмывании денежных средств. Объектом исследования является рынок ценных бумаг. Цель исследования: оптимизация процесса выявления подозрительных сделок на рынке ценных бумаг. Данная задача будет решена с применением метода главных компонент, в программной среде MatLab. Будут выявлены все признаки, сопутствующие проведению сделки на рынке ценных бумаг, затем будут проанализированы и исключены менее значимые признаки, и оставлены наиболее весомые. Это можно выполнить методом нахождения главных компонент. Системный анализ позволит минимизировать основные критерии подозрительных сделок до нескольких наиболее значимых признаков, что повысит точность выявления подозрительных объектов.
Список литературы
1.В.А Борокова "Рынок ценных бумаг: Учебное пособие" Питер, 2012г.,- 352с.
2.О.Е Акимова, Е.Г Попкова "Основы финансового мониторинга" Инфра-м, 2014г, -
166с.
3.М.М Прошунин, М.А Татчук "Финансовый мониторинг (противодействие легализации (отмыванию) доходов, полученных преступным путем, и финансированию терроризма): Учебник" БФУ им.Канта, 2014г – 417с.
214 |
ISBN 978-5-7262-2223-3. XIХ конференция «Молодежь и наука» |

Автоматизированные системы обработки информации и управления
М.А. МЯЛИН, Д.А. ХИМОЛОЗКО Научный руководитель – Л.Г. ГАГАРИНА, д.т.н., профессор
Национальный исследовательский университет «МИЭТ»
ИССЛЕДОВАНИЕ ПРОБЛЕМЫ КОНТРОЛЯ ПРОЦЕССА РАЗРАБОТКИ ПРОГРАММНОГО
ОБЕСПЕЧЕНИЯ В РАСПРЕДЕЛЕННЫХ СИСТЕМАХ
На примере системы непрерывной интеграции Jenkins рассмотрена оптимизация процесса разработки программного обеспечения для распределённой системы с балансировкой нагрузки, проведением регулярных тестов, оценки качества кода и построений программных артефактов.
Тестирование является неотъемлемой частью жизненного цикла разработки программного обеспечения (ПО). При этом стоит понимать, что тестирование крайне желательно проводить в условиях, близких к реальным, чтобы иметь возможность обнаружить ошибки, которые не проявляются во время разработки. Всё вышесказанное входит в концепцию, которая называется «непрерывная интеграция».
Существует метод разработки ПО, использующий централизованную систему контроля версий с последующим ручным тестированием на устройстве разработчика. Такой способ создаёт неудобства при разработке в команде и исключает возможность автоматизации процесса тестирования, поэтому возрастает актуальность концепции «непрерывной интеграции».
«Непрерывная интеграция» — это практика разработки ПО, которая заключается в выполнении частых автоматизированных сборок проекта для скорейшего выявления и решения интеграционных проблем. Переход к непрерывной интеграции позволяет снизить трудоёмкость тестирования
исделать его более предсказуемым за счет наиболее раннего обнаружения
иустранения ошибок и противоречий.
В результате использования системы непрерывной интеграции решается проблема изменений и правок, внесенных разными разработчиками, появляется возможность объективно оценивать результаты разработки и проводить регулярное тестирование.
Балансировка нагрузки (Load Balancing) применяется для оптимизации выполнения распределённых (параллельных) вычислений с помощью распределённой (параллельной) ВС. Балансировка нагрузки предполагает равномерную нагрузку вычислительных узлов (процессора многопроцес-
_______________________________________________________________________
ISBN 978-5-7262-2223-3. XIХ конференция «Молодежь и наука» |
215 |

Автоматизированные системы обработки информации и управления
сорной ЭВМ или компьютера в сети). При появлении новых заданий программное обеспечение, реализующее балансировку, должно принять решение о том, где (на каком вычислительном узле) следует выполнять вычисления, связанные с этим новым заданием. Кроме того, балансировка предполагает перенос (migration – миграция) части вычислений с наиболее загруженных вычислительных узлов на менее загруженные узлы.
Однако при выполнении распределенного приложения возникает конфликт между сбалансированным распределением объектов по процессорам и низкой скоростью обменов сообщениями между процессорами. Если логические процессы распределены между процессорами таким образом, что издержки на коммуникацию между ними сведены к нулю, то некоторые процессоры (компьютеры) могут простаивать, в то время как остальные будут перегружены.
В другом случае, "хорошо сбалансированная" система потребует больших затрат на коммуникацию. Следовательно, стратегия балансировки должна быть таковой, чтобы вычислительные узлы были загружены достаточно равномерно, но и коммуникационная среда не должна быть перегружена.
Реализация распределённой системы имитации требует разработки алгоритмов синхронизации объектов (или процессов), функционирующих на различных узлах ВС. Алгоритмы синхронизации мы уже обсуждали ранее. Эффективность реализации этих алгоритмов, в свою очередь, зависит от равномерности распределения (балансировки) вычислительной нагрузки по узлам ВС во время функционирования распределённой программной системы, каковой является, в частности, распределённая система имитации.
Список литературы
1.Continuous integration / Wikipedia URL: https://en.wikipedia.org/wiki/Continuous_integration.
2.Jenkins Continuous Integration Cookbook / Alan Mark Berg – 2012.
3.Continuous integration / Lib.Custis URL: http://lib.custis.ru/Continuous_Integration.
4.Косяков, М.С. Введение в распределённые выисления / М.С. Косяков – СПб: НИУ ИТМО, 2014. – 155 с.
216 |
ISBN 978-5-7262-2223-3. XIХ конференция «Молодежь и наука» |

Автоматизированные системы обработки информации и управления
В.А. ФЕДОРОВА Научный руководитель – О.Л. ГОЛИЦЫНА, к.т.н., доцент
Национальный исследовательский ядерный университет «МИФИ»
АЛГОРИТМ РАСЧЕТА СЕМАНТИЧЕСКОЙ БЛИЗОСТИ ДЕСКРИПТОРОВ
Рассматриваются подходы к измерению семантической близости между дескрипторами поисковых образов с использованием парадигматических связей в политематической лексикографической БД.
Меры семантической близости широко применяются в области обработки естественного языка [1]. Расчет семантической близости дескрипторов тезауруса в основном учитывает длину пути, соединяющего дескрипторы (с учетом или без ассоциативных связей), или положение дескрипторов в иерархии [1-3].
Внастоящей работе решалась задача сопоставления поисковых образов, представленных множествами дескрипторов тезауруса, с целью построения их пересечения с учетом меры семантической близости дескрипторов. Индексирование проводилось с использованием лексикографической БД, содержащей тезаурусы различных предметных областей: науковедение, информатика, лингвистика, экономика и др.
Всвязи с тем, что тезаурусы, входящие в состав базы данных, имеют неравномерное иерархическое развитие, оказалось неэффективным применять меры, не позволяющие адекватно рассчитать семантическую близость для коротких иерархических цепочек [4].
Мера, предложенная в [3], позволяет рассчитывать семантическую близость даже для иерархических цепочек, состоящих из двух дескрипторов. Для расчета вводится множество суперпонятий  , содержа-
, содержа-
щее само понятие , а также всех его предков в иерархической цепочке этого понятия – :
где m – маршрут, соединяющий понятия и , в котором используются переходы ,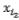 ,…,
,…, к вышестоящим понятиям.
к вышестоящим понятиям.
Мера семантической близости рассчитывается при этом как отношение числа общих суперпонятий к числу всех суперпонятий дескрипторов:
_______________________________________________________________________
ISBN 978-5-7262-2223-3. XIХ конференция «Молодежь и наука» |
217 |

Автоматизированные системы обработки информации и управления
Однако при формировании множества суперпонятий в лексикографической БД необходимо было учесть существование полисемии, порожденной объединением тезаурусов нескольких предметных областей [4]. Были сформулированы и реализованы в алгоритме правила построения иерархических цепочек для дескрипторов, входящих более чем в один тезаурус.
При построении пересечения двух поисковых образов A и B как мно-
жеств дескрипторов |
|
рассчи- |
|
тывается |
матрица семантической близости |
размерности |
: |
, |
где |
. Множество дескрипто- |
|
ров пересечения формируется из тех дескрипторов, для которых выполняется условие: 
Такой алгоритм определяет достаточное значение меры семантической близости для включения дескрипторов в пересечение не через фиксированное пороговое значение, а на основании контекста, задаваемого дескрипторами каждого поискового образа. Так, для пар дескрипторов «Инновационный менеджмент» – «Наука управления», «Инновационный менеджмент» – «Стратегическое управление», «Стратегическое управление»
– «Государственное управление», «Коммерческий кредит» – «Денежные средства», «Заемный капитал» – «Коммерческий кредит», «Заемный капитал» – «Источник финансирования» получены ненулевые значения мер семантической близости. Однако сформулированному ограничению удовлетворяют только пары дескрипторов «Инновационный менеджмент» – «Стратегическое управление», «Коммерческий кредит» – «Заемный капитал». Также в пересечении оказались такие пары понятий, как «Сырьевые ресурсы» – «Стратегические ресурсы», «Муниципальный бюджет» – «Бюджетная система», «Техническое перевооружение» – «Приоритеты развития», «Фонд заработной платы» – «Материальные ресурсы», «Высшее образование» - «Образование взрослых».
Список литературы
1.Лукашевич Н.В., Добров Б.В. Разрешение лексической многозначности на основе тезауруса предметной области //Компьютерная лингвистика и интеллектуальные технологии: Тр. междунар. конф. «Диалог 2007». –М.,2007-с.400-406
2.Lin D. An information-theoretic defenition of similarity // Proc. Of the Int’l Conference on
Machine Learning - 1998
3.Maedche A., Zacharias V. Clustering Ontology-Based Metadata in the Semantic Web / Proceedings PKDD-2002, LNAI 2431, 2002. — P. 348-360
4.Голицына, О.Л. Сравнительный структурно-статистический анализ лексики и связей информационно-поисковых тезаурусов/О.Л. Голицына, Н.В. Максимов //Научнотехническая информация. Сер. 2, Информационные процессы и системы.-2015.-№ 6. С. 14-28
218 |
ISBN 978-5-7262-2223-3. XIХ конференция «Молодежь и наука» |

Автоматизированные системы обработки информации и управления
Е.В. ФИЛАТКИН Научный руководитель – В.П. РУМЯНЦЕВ, к.т.н., доцент
Национальный исследовательский ядерный университет «МИФИ»
ПОСТРОЕНИЕ ПРОГНОСТИЧЕСКОЙ МОДЕЛИ ОГРАНИЧЕНИЙ ДЕЯТЕЛЬНОСТИ ПРЕДПРИЯТИЯ НА ОСНОВЕ ЖУРНАЛОВ СОБЫТИЙ ИНФОРМАЦИОННЫХ СИСТЕМ
Работа рассматривает подход к прогнозированию появления узких мест в деятельности предприятия путем анализа журнала событий информационных систем.
В последнее время в различных компаниях быстро растет использование информационных систем. Новые системы ориентированы на поддержку функционирования процессов компании, в них вовлечены человеческие, программные и другие ресурсы. Это такие системы как ERP, CRM, WFM, SCM и др. Они способны накапливать в журналах событий объективную информацию о деятельности компании, которые в свою очередь можно использовать для построения и идентификации прогностических моделей. Первые работы по прогнозированию с использованием журналов событий стали появляться в начале 2000-х, в рамках сравнительно новой дисциплины «process mining» - глубинного анализа процессов построенных по журналам событий. [1]
Основными атрибутами журналов событий являются (см. рисунок 1):
Идентификатор случая (case): хранит случаи (кейсы), для которых выстраиваются последовательности событий журнала.
Деятельность, работа (activity): хранит работы, выполняемые в рамках событий журнала.
Ресурс, инициатор (resource, originator): хранит основных действующих лиц событий журнала (тех, кто выполняет действия в рамках событий журнала).
Отметка времени (timestamp): хранит дату и время регистрации событий журнала.
Прочее (other data): сюда попадает вся оставшаяся в журнале информация.
Таким образом, каждая строка в таком журнале соответствует отдельному событию. В свою очередь, каждое событие несет в себе информацию о породившем его случае, выполненного в рамках его деятельности и
_______________________________________________________________________
ISBN 978-5-7262-2223-3. XIХ конференция «Молодежь и наука» |
219 |

Автоматизированные системы обработки информации и управления
времени его регистрации. Подобные журналы событий можно рассматривать как совокупности случаев, а отдельные случаи — как последовательности ссылающихся на них событий.
caseID |
activityID |
originator |
timestamp |
other data |
case 1 |
activity A |
Иван |
09.12.2015: 10.01 |
… |
case 2 |
activity A |
Алексей |
09.12.2015: 10.24 |
… |
case 3 |
activity A |
Елена |
09.12.2015: 14.45 |
… |
case 3 |
activity B |
Михаил |
10.12.2015: 9.39 |
… |
case 1 |
activity B |
Михаил |
10.12.2015: 12.50 |
… |
case 1 |
activity C |
Иван |
10.12.2015: 16.14 |
… |
case 3 |
activity D |
Ольга |
11.12.2015: 11.03 |
… |
… |
… |
… |
… |
… |
Рис. 1. Пример журнала событий
Благодаря временным меткам в журнале событий можно отследить динамику изменения как самого процесса, так и сопутствующих атрибутов (other data). Также, в зависимости от правил регистрации работ в журнале событий, можно выявить ограничения или узкие места, так называемые бутылочные горлышки в работе ресурсов или инициаторов работ (resource, originator). Узкое место – это процесс в цепочке процессов, ограничения в пропускной способности которого ограничивают пропускную способность всей цепи. В данном случае, узким местом называется ресурс, который по различным причинам не имеет возможность обработать работу вовремя, т.е. до момента появления следующей работы. Таким образом, образуются очереди из входящих работ. [2]
Зная производительность труда каждого ресурса, зная динамику изменения входящих работ, можно определить тот момент времени в будущем, когда наступят проблемы. Для построения прогностической модели необходимо отфильтровать журнал событий и разделить его на обучающую и тестовую выборку.
Список литературы
1.Van der Aalst W. M. P. Process mining: discovery, conformance and enhancement
of business processes. Springer, 2011.
220 |
ISBN 978-5-7262-2223-3. XIХ конференция «Молодежь и наука» |