

5. Определение вероятностей букв, входящих в каждое сочетание , .
Данные вероятности представлены в таблице 2, и определяются перемножением соответствующих вероятностей появления букв в сообщении.
Из таблицы 2 видно, что вероятности и не равны, следовательно, источник информации является марковским.
6. Определение условных вероятностей.
Условные вероятности определяются по следующей формуле:

Вычисленные вероятности представлены в таблице 3.
Таблица 3.
|
Последующие буквы
|
|||
1 |
3 |
9 |
||
Предыдущие буквы |
1 |
0,24 |
0,36 |
0,36 |
3 |
0,268 |
0,415 |
0,317 |
|
9 |
0,235 |
0,412 |
0,353 |
|

7. Определение информационных характеристик источника и оценка влияния на них неравновероятности и взаимозависимости букв.
Вычислим энтропию источника.
1. В предположении равновероятности и взаимонезависимости букв:
 .
.
2. В предположении неравновероятности и взаимонезависимости букв:

3. В предположении неравновероятности и взаимозависимости букв (марковский):






8. Вычисление относительной избыточности e и информативности сообщения d.

Для Д.И.И. с равной вероятностью и взаимной независимостью букв избыточность равна 0%, а информативность – 100%.
Для Д.И.И. с неравновероятными и взаимонезависимыми буквами:


Для марковского Д.И.И.:
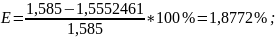

Результаты вычислений объединены и представлены в таблице 4.
Таблица 4.
Наименование параметра |
Тип Д.И.И. |
||
С равной вер-тью |
С неравной вер-тью |
Марковский |
|
Энергия H(A), бит/букву |
1,585 |
1,5563 |
1,5552561 |
Избыточность E,% |
0 |
1,8107 |
1,8772 |
Коэф. инфор-мативности D,% |
100 |
98,1893 |
98,1228 |
9. Определение количества информации J и минимального количества двоичных символов, необходимых для кодирования сообщения.

Для кодирования сообщения равномерным
двоичным кодом необходимо некоторое
число двоичных букв, определяемое как
 ,
причём
,
причём
 Тогда:
Тогда:

Если каждую букву сообщения кодировать 2 битами, то максимальное количество информации, возможное для 100-буквенного сообщения, равно 200 бит.
10. Статистическое кодирование сообщений источника
Цель и принципы статистического кодирования.
Цель статистического кодирования – уменьшение избыточности, вызванной неравновероятностью появления букв.
Принцип кодирования: буквы, которые передаются часто, кодируются коротким комбинациями, а буквы, которые передаются редко – длинными комбинациями.
11. Построение статистического кода для побуквенного кодирования.
Воспользуемся алгоритмом Хаффмена.
Результаты кодирования представлены в таблице 5.
Таблица 5.
-
Граф древовидный
Код комбинации
Число символов кода

3
0,41

1
1
9
0,34
01
2
1
0,25
00
2
Вычислим количество букв статистического кода, необходимого для кодирования стобуквенного сообщения источника:

Остаточная избыточность:

