

Управление памятью в современных операционных системах. Савинков А.Ю
.pdfНа верхнем уровне иерархии находится процессорный кэш – наиболее быстрая, но и наиболее дорогая память с минимальным объемом. Объем кэша существенно меньше объема нижележащих уровней памяти. Для ускорения работы процессорный кэш часто реализуется как неотъемлемая часть процессора. В зависимости от типа процессора, в нем может быть представлено несколько уровней кэширования, различающихся назначением (кэш данных или инструкций программы), объемом, быстродействием, алгоритмами управления.
Основная (или оперативная) память представляет средний уровень иерархии. Сейчас это электронная память с довольно высоким быстродействием. Ее объем в современных настольных компьютерах обычно составляет несколько гигабайт, что в тысячи раз превосходит объем кэша, но при этом ОЗУ в несколько раз уступает кэшу по быстродействию.
Нижний уровень иерархии – вторичная память, обычно представлен накопителем на жестком магнитном диске (HDD). В современных компьютерах вместо HDD все чаще встречается твердотельный накопитель (SSD), отличающийся большим быстродействием при одиночных операциях чтения/записи. Типичный объем вторичной памяти порядка единиц терабайт, что в сотни раз больше объема ОЗУ. Но быстродействие вторичной памяти многократно, в тысячи раз, уступает производительности ОЗУ.
За взаимодействие этих уровней памяти и за передачу данных между ними отвечает программноаппаратная подсистема управления памятью, представляющая собой сочетание аппаратных средств в составе процессора и программного кода в составе операционной системы.
11
2.1. Принципы управления иерархической памятью
Для работы иерархической памяти в системе управления памятью должны быть реализованы три дисциплины управления, обеспечивающих перемещение данных между уровнями и размещение данных в адресном пространстве каждого уровня. Эти дисциплины управления обычно называют дисциплинами выборки,
размещения и замещения данных.
Дисциплина выборки данных должна быть реализована на каждом уровне иерархии памяти, для которого существует нижележащий уровень. Дисциплина выборки данных решает, какие именно данные и когда должны быть получены с нижележащего уровня иерархии памяти.
Дисциплина размещения данных должна быть реализована на каждом уровне иерархии памяти. Дисциплина размещения данных определяет диапазон адресов в адресном пространстве своего уровня, который будет использован для размещения новых данных.
Дисциплина замещения данных должна быть реализована на каждом уровне иерархии памяти, для которого существует нижележащий уровень. Дисциплина замещения данных решает, какие именно данные должны быть выгружены на нижележащий уровень в случае нехватки на своем уровне свободного места для размещения новых данных.
Ввиду локализации ссылок, мы можем предположить, что в каждый конкретный момент времени программа использует только небольшую часть из всего объема своих данных и программного кода, и эта небольшая часть может быть локализована и перенесена на верхние уровни иерархии, что обеспечит повышение
12
скорости выполнения программы. Следовательно, дисциплины управления выборкой, размещением и замещением данных на всех уровнях иерархии должны так перемещать и располагать данные на уровнях памяти, чтобы обеспечить группировку на верхних уровнях иерархии памяти кода и данных, активно используемых программой в данное время.
Рассмотрим основные идеи (концепции), используемые при реализации дисциплин управления иерархической памятью.
В общем случае для решения задачи управления любыми ресурсами компьютера сначала необходимо выработать стратегию управления, определяющую цель управления и основные идеи по ее достижению, а затем разработать дисциплину (алгоритм) управления, реализующую (хотя бы приблизительно) заявленную стратегию.
Применительно к задаче управления выборкой данных, решаемой на некотором уровне иерархии, цель управления состоит в том, чтобы исполняющиеся программы как можно чаще находили бы нужные им данные на этом уровне иерархии, без обращений к нижележащему уровню.
Одним из главных вопросов, на который нужно найти ответ для достижения поставленной цели, является вопрос об определении набора данных, необходимых исполняющимся программам. В зависимости от метода определения ответа на этот вопрос, может быть предложено две стратегии выборки, известные как
выборка по требованию и упреждающая выборка.
Выборка по требованию предусматривает перемещение данных на вышележащий уровень иерархии
13
памяти только после попытки обращения к этим данным со стороны исполняющейся программы.
Упреждающая выборка предполагает использование специальных алгоритмов прогнозирования, которые могли бы заранее предсказать, какие именно данные скоро потребуются программе, чтобы заблаговременно получить эти данные с нижних уровней иерархии.
Каждая из этих стратегий имеет свои преимущества и недостатки.
Выборка по требованию реализуется с минимальными накладными расходами и исключает ошибочный перенос лишних данных на верхние уровни иерархии, но при первом обращении к новым данным, отсутствующим в памяти уровня, необходимо приостанавливать выполнение программы на время поиска и перемещения данных, что является главным недостатком такого подхода.
Упреждающая выборка потенциально способна обеспечить более высокую скорость выполнения программ, поскольку при использовании упреждающей выборки выполнение программ существенно реже будут приостанавливаться в ожидании загрузки данных после неудачных попыток обращения к памяти. Но при использовании упреждающей выборки возникает два отрицательных момента:
необходимость прогнозирования будущих обращений к памяти со стороны исполняющихся программ ведет к дополнительным накладным расходам;
прогнозирование не может быть выполнено абсолютно точно, поэтому некоторые данные могут отсутствовать в памяти на момент обращения к ним, в то
14
время как другие, не нужные данные будут ошибочно выбраны.
Для повышения достоверности прогнозирования будущих обращений к памяти, некоторые современные операционные системы накапливают и хранят в специальных файлах статистику обращений к памяти по каждой программе, которая когда-либо запускалась на компьютере, чтобы использовать эту информацию для прогнозирования обращений к памяти при последующих запусках этих программ.
Рассмотрим теперь задачу размещения данных. Для решения этой задачи необходимо найти в адресном пространстве уровня-получателя свободный участок для размещения новых данных, при этом полагается, что на уровне-получателе есть достаточно свободной памяти. Если же это не так, и свободной памяти недостаточно, то необходимо сначала обратиться к задаче замещения, для выгрузки части данных на нижележащие уровни.
Различают связное и несвязное распределение памяти. Связное распределение памяти предполагает, что весь необходимый объем памяти будет выделен единым фрагментом. Несвязное же распределение позволяет набирать требуемый объем памяти из нескольких не примыкающих друг к другу фрагментов. Очевидно, что связное распределение памяти реализовать сложнее. Кроме того, в силу особенностей архитектуры процессоров и сложившихся методов программирования, в реальных системах почти всегда требуется выполнять связное распределение.
Существует несколько подходов к решению задачи связного распределения памяти, но в любом случае, алгоритм размещения должен поддерживать некоторую структуру данных (карту памяти), позволяющую
15
учитывать распределение свободных и занятых областей памяти в адресном пространстве. При этом решение задачи размещения данных сводится к просмотру списка свободных областей и выбору одной свободной области, пригодной для размещения данных. Если размер этой выбранной области окажется больше, чем требуется для размещения данных, то ее остаток отделяется и образует новую свободную область, которая заносится в карту памяти.
В зависимости от правила поиска свободной области для размещения новых данных, различают три стратегии распределения памяти:
стратегия первого подходящего – для размещения новых данных выбирается первый же встреченный свободный участок достаточного размера;
стратегия наиболее подходящего – для размещения новых данных выбирается самый маленький свободный участок, способный вместить эти данные;
стратегия наименее подходящего – для размещения новых данных выбирается самый большой свободный участок.
Каждая из указанных стратегий имеет свои преимущества и недостатки, ограничивающие их практическую применимость. Рассмотрим их более внимательно.
Основным преимуществом стратегии первого подходящего является высокая скорость выделения памяти
–это единственная из трех рассматриваемых стратегий, не требующая просмотра всего списка свободных блоков: просмотр списка свободных блоков прекращается, как только будет найден блок достаточного размера.
Основным недостатком этой стратегии является накопление свободных блоков малого размера в начале
16
списка свободных блоков. Это увеличивает время поиска подходящего блока при последующих запросах на размещение данных, т.к. пока алгоритм доберется до блока подходящего размера, приходится просматривать множество коротких блоков в начале списка.
Для борьбы с этим явлением была предложена модификация стратегии первого подходящего, известная как стратегия следующего подходящего.
Основная идея стратегии следующего подходящего заключается в том, чтобы начать просмотр списка свободных блоков с той позиции, где в прошлый раз был выделен блок памяти. При достижении конца списка, просмотр снова начинается сначала и т.д.
Стратегия следующего подходящего исключает скопление коротких свободных блоков в какой-либо части списка, но имеет другой недостаток.
При использовании традиционной реализации стратегии первого подходящего, в конце списка свободных блоков обычно сохраняются свободные блоки большого размера, т.к. при просмотре списка редко достигается его конец: требуемый блок обычно удается найти раньше. Поэтому при необходимости разместить большой блок данных свободное место для него почти всегда удается найти в конце списка свободных блоков.
Стратегия же следующего подходящего разбивает большие свободные блоки. Распределение свободных блоков различного размера по списку становится более равномерным, исключается скопление малых блоков в голове списка, но зато исчезает и резерв блоков большого размера. В результате растет вероятность отказа при попытке размещения блоков данных большого размера.
Максимально отсрочить использование свободных блоков большого размера призвана стратегия наиболее
17
подходящего, которая заключается в том, чтобы из всех имеющихся подходящих свободных блоков выбрать такой, размер которого был бы наиболее близок к выделяемому объему памяти. Очевидно, что такой подход требует для вынесения решения полного просмотра списка свободных блоков, что снижает скорость выполнения запроса на размещение данных.
Кроме того, стратегия наиболее подходящего имеет еще один существенный недостаток. После размещения новых данных остаток памяти использованного свободного блока возвращается в карту памяти в качестве нового свободного блока меньшего размера. Использовании для размещения новых данных самого маленького из пригодных для этого свободных блоков ведет к появлению нового свободного блока минимального размера, который скорее всего уже нельзя будет использовать для размещения в нем данных. Это ведет к фрагментации и неэффективному использованию памяти.
Для снижения фрагментации свободной памяти может быть использована стратегия наименее подходящего, сущность которой заключается в том, чтобы из всех имеющихся свободных блоков использовать для размещения новых данных блок наибольшего размера. Такой выбор повышает вероятность того, что остаток использованного свободного блока будет достаточно большим, чтобы его можно было использовать в дальнейшем для размещения новых данных.
Недостаток же стратегии наименее подходящего состоит в том, что она неоправданно разбивает большие свободные блоки, повышая вероятность отказа при дальнейших попытках размещения новых данных.
Таким образом, стратегии наиболее подходящего и наименее подходящего не ведут к существенным
18
улучшениям, по сравнению со стратегией следующего подходящего, которая в большинстве случаев используется для решения задачи размещения данных, возможно, с некоторыми модификациями, учитывающими специфику решаемых задач и применяемой аппаратной платформы.
Рассмотрим теперь решение задачи замещения данных. При нехватке свободного места для размещения новых данных на некотором уровне, новые данные должны заместить часть старых данных в адресном пространстве этого уровня. При этом старые данные переносятся на нижележащий уровень. В принципе, для освобождения места можно заместить любые данные уровня. Если при этом будут замещены данные, используемые исполняющимися программами, то при попытке обращения к ним будет инициирована новая выборка этих данных, которые теперь будут размещены по другому адресу, причем для их размещения на уровне-получателе возможно снова потребуется выполнить замещение данных.
Таким образом, иерархическая память сохранит работоспособность при вытеснении любых данных, но для достижения максимальной производительности стратегия замещения должна минимизировать число пересылок данных между уровнями, для этого она должна выбирать для замещения те данные, к которым дольше всего не будет обращений. Это так называемая оптимальная стратегия замещения [1], которая в общем случае не может быть реализована, поскольку точные адреса будущих обращений к памяти нам не известны.
Помимо оптимальной стратегии замещения, могут применяться и альтернативные варианты, в частности
стратегия случайного замещения и стратегия замещения наиболее старых данных.
19
Если нет никакой информации об адресах будущих обращений к памяти, и нельзя сделать обоснованных предположений о большей или меньшей вероятности обращения к тем или иным данным, то оптимизация выбора данных для замещения невозможна. В этом случае предлагается случайным образом выбирать для замещения блок данных в памяти уровня.
Если при этом будут замещены «нужные» данные, которые используются исполняющимися программами, то эти данные в скором времени будут снова выбраны в память уровня. Для их размещения будут замещены другие случайные данные и т.д., пока таким случайным поиском не будут обнаружены «ненужные» данные, которые больше не используются.
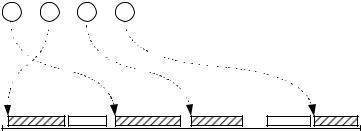
Для того, чтобы снизить накладные расходы при поиске неиспользуемых данных методом «проб и ошибок» и сохранить высокую производительность иерархической памяти, целесообразно реализовать замещение с буферизацией, идея которого поясняется на рис. 4.
Список блоков памяти для замещения
1 
 2
2 
 3
3 
 4
4
Адресное пространство уровня памяти и блоки данных в нем
Рис. 4. Очередь замещения при использовании замещения с буферизацией
20