

Методическое пособие 391
.pdfКпроцедурам, определяющим действия над вершинами
иявляющимися средствами манипулирования данными, относятся:
- создание экземпляра некоторого класса; - подсчет числа экземпляров, принадлежащих классу;
- проверка принадлежности экземпляра некоторому классу;
- установление принадлежности экземпляра некоторому классу;
- выбор экземпляров, принадлежащих некоторому классу.
Косновным действиям над семантическими сетями можно отнести:
- установление соответствия между элементами различных сетей. Для этого необходимо задать правило сопоставления элементов одной сети элементам другой;
- объединение семантических сетей и разделение на
части;
- запрос семантической сети. Запрос – это граф (фрагмент семантической сети), в котором вершины, соответствующие некоторым понятиям, событиям, объектам, не определены. Поиск ответа состоит в решении задачи изоморфного вложения графа запроса в семантическую сеть. Существуют два типа запросов:
1) на существование изоморфного вложения. Он предполагает ответ типа «да» или «нет»;
2) на перечисление возможных изоморфных вложений и конкретизацию переменных, т.е. установление соответствия неопределенных имен объектов и дуг графа запроса конкретным именам запрашиваемой семантической сети. Эта операция является одной из основных при организации логического вывода в семантических сетях. Например, запрос «Где работает Иванов?». Строим граф запроса (рис. 9).
41
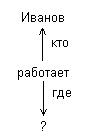
Рис. 9. Пример графа запроса
Затем производится сопоставление этого фрагмента с семантической сетью, на основании чего формируется ответ на запрос – «банк».
Кроме рассмотренных стратегий вывода в семантических сетях, таких как механизм наследования, сопоставления речевых структур, существует много других способов и подходов, использование каждого из которых зависит от спецификации предметной области и класса решаемых задач.
С помощью семантических сетей можно представлять как декларативные, так и процедурные знания. В развитых семантических сетях осуществляют объединение процедурного и декларативного подходов. При этом в качестве вершин семантической сети вводятся программы, реализующие процедуры обработки декларативных знаний.
Наибольшие перспективы в развитии сетевых моделей связаны с достижениями в области компьютерной лингвистики, с созданием алгоритмов лингвистически и семантически безупречного «понимания» машиной естественного человеческого языка, что, в свою очередь, приведет к созданию моделей представления знаний на основе символьных сетей.
Семантические сети широко и успешно применяются при решении задач распознавания образов, в системах управления различного рода сложными объектами, а в
42
последнее время – и в экспертных системах. Расширению областей применения семантико-сетевых моделей способствует рост возможностей электронно-вычислительной техники.
Главным недостатком сетевых моделей является сложность организации логического вывода, вследствие большого объема, бессистемности топологии и неоднородности отношений, применяемых для выражения связей между понятиями проблемной области.
2.4. Представление знаний логическими моделями
Одной из форм представления знаний о проблемных областях с небольшим пространством поиска решений и достаточно определенными фактами и правилами являются логические модели. Они удобны для формального описания мышления человека, так как часто его рассуждения при решении задач носят дедуктивный характер. Логическая модель по своей практической результативности и степени внедрения в реальные технические устройства сегодня занимает центральное место. Сама по себе модель не однородна и включает в себя достаточно большое количество существенно разных теорий. Элементы логики, наиболее часто используемые в системах искусственного интеллекта, представлены на рис. 10.
Исторически первой моделью представления знаний (среди моделей искусственного интеллекта вообще), стала классическая (формальная) логика Аристотеля, заложившая фундамент всех последующих логических теорий. Дальнейшее развитие модели связано с именами Канта (семантический анализ на основе категорий), Буля («математизация» логики), Фреге, Заде (нечеткая логика). Последние десятилетия активно развиваются «неклассические направления»: модальная, временные логики.
43

Элементылогики,наиболее часто используемыев системах ИИ
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Элементыисчисления |
|
Элементыисчисления |
|
Элементытеории |
|
Элементытеории |
|
|||||||||||
|
высказываний |
|
|
|
предикатов |
|
|
множеств |
|
|
алгоритмов |
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Силлогистика |
|
|
|
|
|
Элементы исчисления |
|
|
|
|
|
|
|||||
|
Аристотеля |
|
|
|
|
|
предикатовпервого порядка |
|
|
Элементыклассической |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
теории множеств |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
Элементыисчисления |
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
предикатов второго порядка |
|
|
Элементыальтернативных |
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
теорий множеств |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
“Неклассические” |
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
исчисления |
|
|
|
|
|
|
||||
Рис. 10. Элементы логики
Смысл построения любой формальной теории состоит в том, чтобы выразить мыслительные процессы формально, т.е. записать формулами. Необходимо, чтобы система уравнений, образуемая такими формулами, решалась какими-либо методами, причем так, чтобы результаты вычислений совпадали с картиной, которую мы наблюдали бы в реальном мире при практическом осуществлении тех действий, которые моделируем. Если удастся сформулировать такие формулы и правила, то можно будет предсказывать последствия тех или иных действий без практического осуществления этих действий. В процессе вычислений не имеет значения предметный смысл преобразований над переменными и формулами, а важно только точное соблюдение формальных правил. Интерпретируются только конечные результаты. Следовательно, сам процесс формального логического вывода может осуществляться машиной. Функциями пользователя будут интерпретация и оценка полезности результатов.
Для того чтобы задать формальную логическую теорию, необходимо определить алфавит (множество символов,
44
используемых для записи), правила синтаксиса (правила записи формул), аксиоматику (особое подмножество формул) и правила вывода (множество отношений на множестве формул). Правила вывода должны быть заданы так, чтобы на любых исходных данных обеспечить правильность логических заключений. Алфавит и аксиоматика должны быть заданы так, чтобы обеспечить осмысленность получаемых заключений и промежуточных следствий. Таким образом, основное различие
влогических теориях состоит в выборе аксиом и определении правил вывода.
Распространенным типом логических моделей является логика предикатов первого порядка. Она является расширением логики высказываний, так как основным объектом является переменное высказывание (предикат), истинность или ложность которого зависит от значения его переменных.
Исчисление высказываний имеет определенные ограничения. Оно не позволяет оперировать с обобщенными утверждениями вроде “все люди смертны”. Логика предикатов предоставляет набор синтаксических правил, семантических правил и теорию доказательств, которая позволяет вывести правильные формулы, используя синтаксические правила дедукции.
Знания, которые могут быть представлены с помощью логики предикатов, являются фактами, представляемыми логическими формулами. Для представления какой-либо области в виде логических формул, прежде всего, необходимо выбрать константы, которые определяют объекты в данной области, а также функциональные и предикатные символы, которые определяют соответственно функциональную зависимость и отношения между объектами. После этого можно построить логические формулы, описывающие данную область. Записать знания в виде логических формул не удается
втех случаях, когда затруднен выбор указанных трех групп символов, или же эти знания превышают возможности
45
представления в логике предикатов. То есть, формальные классические модели предъявляют очень высокие требования и ограничения к предметной области. Это приводит к тому, что в промышленных экспертных системах исчисление предикатов практически не используется. Тем не менее у этого класса моделей есть и преимущества:
-единственность теоретического обоснования;
-возможность реализации системы формально точных определений и выводов.
2.5. Системы на основе нечеткой логики
Отличительной особенностью естественной компетенции (интеллекта) является способность принимать правильные решения в условиях неполной и нечеткой информации. Построение моделей приближенных размышлений человека и использование их в интеллектуальных системах представляет сегодня одну из важнейших проблем искусственного интеллекта.
Основы нечеткой логики были заложены в конце 60-х в работах известного американского математика Лотфи Заде. Для создания интеллектуальных систем, в полной мере соответствующих тем требованиям, которые к ним предъявляются и способных адекватно взаимодействовать с человеком, был необходим новый математический аппарат, который переводит неоднозначные жизненные утверждения в язык четких и формальных математических формул. Первым серьезным шагом в этом направлении стала теория нечетких множеств, разработанная Заде. Он заложил основы моделирования интеллектуальной деятельности человека и дал толчок к развитию новой математической теории. Он же дал и название для новой области науки - "fuzzy logic" (fuzzy - нечеткий, размытый, мягкий). Дальнейшие работы профессора Лотфи Заде и его последователей заложили фундамент новой
46
теории и создали предпосылки для внедрения методов нечеткого управления в инженерную практику.
При попытке формализовать человеческие знания исследователи столкнулись с проблемой, затруднявшей использование традиционного математического аппарата для их описания. Существует целый класс описаний, оперирующих качественными характеристиками объектов (много, мало, сильный, очень сильный и т.п.). Эти характеристики обычно размыты и не могут быть однозначно интерпретированы, однако они содержат важную информацию (например, «Одним из возможных признаков гриппа является высокая температура»).
Кроме того, в задачах, решаемых интеллектуальными системами, часто приходится пользоваться неточными знаниями, которые не могут быть интерпретированы как полностью истинные или ложные. Существуют знания, достоверность которых выражается некоторой промежуточной цифрой, например 0,7.
Для разрешения таких проблем используется формальный аппарат нечеткой алгебры и нечеткой логики, главными понятиями которой являются нечеткие и лингвистические переменная.
Нечеткая переменная характеризуется тройкой <α, X, A>, где
α- имя переменной,
X - универсальное множество (область определения α), A - нечеткое множество на X, описывающее ограничение (то есть µA(x)) на значение нечеткой переменной
α.
Лингвистической переменной называется набор
<β,T,X,G,M>, где
β - имя лингвистической переменной; Т - множество её значений (терм-множество),
представляющие имена нечетких переменных, областью определения которых является множество X. Множество T
47
называется базовым терм-множеством лингвистической переменной;
G - синтаксическая процедура, позволяющая оперировать элементами терм-множества T, в частности, генерировать новые термы (значения). Множество T G(T), где G(T) - множество сгенерированных термов, называется расширенным терм-множеством лингвистической переменной;
М- семантическая процедура, позволяющая преобразовать новое значение лингвистической переменной, образованной процедурой G, в нечеткую переменную, то есть сформировать соответствующее нечеткое множество.
Во избежание большого количества символов символ β используют как для названия самой переменной, так и для всех его значений, а для обозначения нечеткого множества и его названия пользуются одним символом, например, терм "молодой", является значением лингвистической переменной b
="возраст", и одновременно нечетким множеством М ("молодой"). Присваивание нескольких значений символам предполагает, что контекст допускает неопределенности.
Например, пусть эксперт определяет толщину изделия, с помощью понятия "маленькая толщина", "средняя толщина" и "большая толщина", при этом минимальная толщина равняется 10 мм, а максимальная - 80 мм.
Формализация этого описания может быть проведена с помощью лингвистической переменной < β, T, X, G, M>, где
β - толщина изделия;
T - {"маленькая толщина", "средняя толщина", "большая толщина"};
X - [10, 80];
G - процедура образования новых термов с помощью связок "и", "или" и модификаторов типа "очень", "не", "слегка" и др. Например, "маленькая или средняя толщина", "очень маленькая толщина" и др.;
М- процедура задания на X = [10, 80] нечетких подмножеств А1="маленькая толщина", А2 = "средняя
48

толщина", А3="большая толщина", а также нечетких множеств для термов из G(T) соответственно правилам трансляции нечетких связок и модификаторов "и", "или", "не", "очень", "слегка", операции над нечеткими множествами вида: А C,
А C, A, CON(A) = A2 , DIL(A) = A0,5 .
Вместе с рассмотренными выше базовыми значениями лингвистической переменной "толщина" (Т={"маленькая толщина", "средняя толщина", "большая толщина"}) существуют значения, зависящие от области определения Х. В данном случае значения лингвистической переменной "толщина изделия" могут быть определены как "около 20 мм", "около 50 мм", "около 70 мм", то есть в виде нечетких чисел.
Функции принадлежности нечетких множеств: "маленькая толщина" = А1 , "средняя толщина"= А2, " большая толщина"= А3 (рис. 11).
µA(х) |
|
|
A1 |
A2 |
A3 |
1 |
|
|
|
0 10 |
80 Х |
Рис. 11. |
Функции принадлежности нечетких множеств |
|
Функция |
принадлежности |
нечеткого множества |
"маленькая или средняя толщина" А1 А2 (рис.12).
Нечеткими высказываниями называются высказывания следующего вида:
- высказывание <β есть β'>, где β - имя лингвистической переменной, β' - ее значение, которому соответствует нечеткое множество на универсальном множестве Х. Например, высказывание <давление большое> предполагает, что лингвистической переменной "давление" предоставляется
49

значение "большой", для которого на универсальном множестве Х переменной "давление" определено, соответственно данному значению "большой", нечеткое множество;
-высказывание <β есть mβ'>, где m - модификатор, которому соответствуют слова "очень", "более или менее", "намно больше" и др.;
-сложные высказывания, образованные из высказываний вида 1 и 2 и операций "И", "ИЛИ", "ЕСЛИ..,
ТО...", "ЕСЛИ.., ТО.., ИНАЧЕ".
µA1(х) A2(x)
1
0 10 |
80 Х |
Рис. 12. Функция принадлежности нечеткого множества
Если значения фиксированной лингвистической переменной соответствуют нечетким множествам одного универсального множества Х, можно отождествлять модификаторы "очень" или "нет" с операциями "CON" и "дополнение", а союзы "И", "ИЛИ" с операциями "пересечение" и "объединение" над нечеткими множествами.
Для иллюстрации понятия лингвистической переменной мы в качестве примера рассматривали лингвистическую переменную "толщина изделия" с базовым терм-множеством Т = {"маленькая", "средняя", "большая"}. При этом на Х = [10, 80] мы определили нечеткие множества А1, А2, А3, соответствующие базовым значениям: "маленькая", "средняя", "большая".
50