Сжатие по Шеннону-Фано
.docxМИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ КЫРГЫЗСКОЙ РЕСПУБЛИКИ
КЫРГЫЗСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ
УНИВЕРСИТЕТ ИМ. И. РАЗЗАКОВА
Лабораторная работа
Бишкек 2021
Сжатие по Шеннону-Фано
Построить дерево и таблицу кодирования по Шеннону. Подсчитать сколько на сколько разрядов осуществилось сжатие без учета таблицы кодов.
Мой текст: “носорогоносец нос сон рог сор” - весит 232 бит.
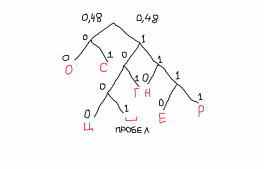
Дерево и таблица:
Алфавит: О,С,_,Н,Р,Г,Ц,Е (N=8)
Буква |
Частота |
Вероятность |
Код |
О |
9 |
0,31 |
00 |
С |
5 |
0,17 |
01 |
_ - пробел |
4 |
0,13 |
101 |
Н |
4 |
0,13 |
110 |
Р |
3 |
0,10 |
1000 |
Г |
2 |
0,06 |
1001 |
Ц |
1 |
0,03 |
1110 |
Е |
1 |
0,03 |
1111 |
Дерево:
Закодирование:
носорогоносец нос сон рог сор = 110 00 01 00 1000 00 1001 00 110 00 01 1111 1110 101 110 00 01 101 01 00 110 101 1000 00 1001 101 01 00 1000 = 80 бит
Алфавитное кодирование:
Формула Хартли:

b – число битов, необходимое для кодирования одного слова, N – число всех слов.
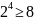 где
b
= 4 бита.
где
b
= 4 бита.
Тогда для алфавитного кодирования слова понадобится 4 * 29 = 116 бит.
Ответ: можно сэкономить 36 бит.
Листинг кода:
from collections import Counter
def divide_table(table):
optimal_difference = sum(table.values())
optimal_index = 0
for i in range(len(table)):
current_difference = abs(sum(list(table.values())[:i]) - sum(list(table.values())[i:]))
#находит сумму и делит
if current_difference < optimal_difference:
optimal_difference = current_difference
optimal_index = i
return dict({item for i, item in enumerate(table.items()) if i < optimal_index}), \
dict({item for i, item in enumerate(table.items()) if i >= optimal_index})
#
def shenon_get_codes(table, value='', codes={}):
if len(table) != 1:
a, b = divide_table(table)
shenon_get_codes(a, value + '0', codes)
shenon_get_codes(b, value + '1', codes)
else:
codes[table.popitem()[0]] = value
return codes
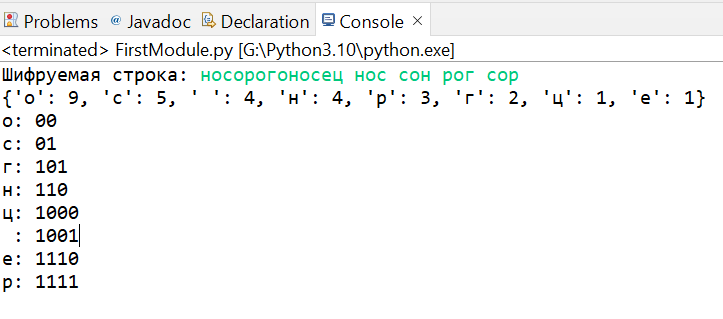
data = input('Шифруемая строка: ')
counter = Counter(data)
sorted_freq = sorted(set(data), key=lambda letter: counter[letter], reverse=True)
sorted_freq_dict = {letter: counter[letter] for letter in sorted_freq}
code_table = shenon_get_codes(sorted_freq_dict)
print(sorted_freq_dict)
for symbol, key in sorted(code_table.items(), key=lambda item: len(item[1])):
print(symbol, key, sep=': ')
Фото результат: