

ГУАП
КАФЕДРА № 41
ОТЧЕТ ЗАЩИЩЕН С ОЦЕНКОЙ
ПРЕПОДАВАТЕЛЬ
кандидат тех. наук, доцент |
|
|
|
А.В. Аграновский |
должность, уч. степень, звание |
|
подпись, дата |
|
инициалы, фамилия |
ОТЧЕТ О ЛАБОРАТОРНОЙ РАБОТЕ № 8 |
Работа с данными в формате CSV |
по курсу: ТЕХНОЛОГИИ ПРОГРАММИРОВАНИЯ |
|
|
РАБОТУ ВЫПОЛНИЛА
СТУДЕНТКА ГР. № |
4716 |
|
|
|
С.А. Янышева |
|
|
|
подпись, дата |
|
инициалы, фамилия |
Санкт-Петербург
2019
1 Постановка задачи
Считать данные из CSV-файла в память программы. При этом, внутренние структуры данных должны предоставлять возможность построения различных поисковых запросов к сохранённым данным.
Для каждого измеренного показателя (“SUBJECT”) необходимо построить график отображающий данные (“VALUE”) для каждой из имеющихся стран как функцию от времени (“TIME”). Если существуют различные единицы измерения параметров, то для каждого показателя должны быть построены отдельные графики для каждой единицы измерений. Каждый график должен иметь подписи координатных осей; заголовок, отражающий название изображённого на данном графике показателя и его единицы измерения; легенду. Таким образом, если в наборе данных имеется три показателя, каждый из которых представлен в трёх единицах измерениях, то всего должно быть построено 9 графиков. Так как в наборе данных представлено большое количество стран, то отображать на графике следует лишь часть от имеющихся стран. Количество отображаемых стран на графике должно быть задано как параметр.
Способ выбора отображаемых стран: страны выбираются случайным образом с использованием датчика случайных чисел.
Провести дополнительную обработку данных по заданию, а результаты обработки представить в виде графика или таблицы. Графики должны быть сохранены в файле с расширением PNG, а таблица должна быть сохранена в новый CSV-файл.
Обработка: разбить весь временной интервал на десятилетия. Для каждого десятилетия, найти k стран, имеющих самое большое значение показателя и p стран, имеющих самое низкое значение показателя (значения k и p должны быть параметрами).
Вариант: «WorkingAgePopulation.csv».
2 Математическая модель
Блок-схема разработанной модели представлена на рисунке 1.
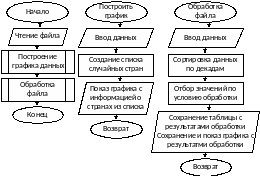
Рисунок 1 – Блок-схема разработанной математической модели
3 Описание разработанной программы
Список входных данных представлен в таблице 1.
Таблица 1 - Список входных данных
Название переменной |
Тип |
Описание |
Iput_file |
CSV |
CSV-файл с данными подлежащими обработке |
p |
Int |
Число стран, с самым большим значением |
k |
Int |
Число стран с самым низким значением |
Список выходных данных представлен в таблице 2.
Таблица 2 - Список выходных данных
Название переменной |
Тип |
Описание |
Output_file |
CSV |
CSV-файл с результатами обработки входного файла |
Output_image |
PNG |
PNG-изображение с визуализацией данных Output_file |
Листинг программного кода:
import random import matplotlib.pyplot as plt import csv
#Чтение csv-файла def csv_reader(name): with open(name, "r") as csv_file: reader = csv.reader(csv_file) lines = [] for row in reader: lines.append(row) lines[0][0] = lines[0][0][3:] return lines
#Запись в csv-файл def csv_writer(lines, name): with open(name, 'w', newline='') as csv_file: writer = csv.writer(csv_file, delimiter=',') for line in lines: writer.writerow(line)
#Представление строк файла в удобной форме для обработки def change(lines): data = {} #Получаем структуру: {Location: {Subject: {Measure: {"Time": [Time], "Value": [Value]}}}} for row in lines[3:]: #Перебираем игнорируя начальные строки файла loc = row[0] sub = row[2] mea = row[3] time = int(row[5]) if row[6] == "": continue else: value = float(row[6])
if loc not in data: data[loc] = {} if sub not in data[loc]: data[loc][sub] = {} if mea not in data[loc][sub]: data[loc][sub][mea] = {"Time": [], "Value": []}
data[loc][sub][mea]["Time"].append(time) data[loc][sub][mea]["Value"].append(value) return data
#Представление данных в виде, удобном для записи в файл def unchange(data): lines = ["LOCATION,SUBJECT,MEASURE,TIME,Value".split(',')] for loc in data: for sub in data[loc]: for mea in data[loc][sub]: for i in range(0, len(data[loc][sub][mea]["Time"])): lines.append([loc, sub, mea, str(data[loc][sub][mea]["Time"][i]), str(data[loc][sub][mea]["Value"][i])]) return lines
#Показ данных def show(data, name = ""): if name == "": #Получение списка случайных стран countries = [] while countries == []: for i in data: if random.randint(1, len(data)) in [1, 2]: countries.append(i) else: countries = data
#Анализ количества и типов требуемых графиков plots = {} #Структура {Subject: {Measure: int}} colums = 0 for loc in data: if loc not in countries: continue for sub in data[loc]: if sub not in plots: plots[sub] = {} for mea in data[loc][sub]: plots[sub][mea] = 0 if colums < len(plots[sub]): colums = len(plots[sub])
#Инициализация графиков plt.figure(figsize=(12,6)) i = 0 for s in plots: j = 0 for m in plots[s]: j += 1 plots[s][m] = i * colums + j plt.subplot(len(plots), colums, plots[s][m]) plt.title(s) plt.xlabel('year') plt.ylabel(m) plt.legend(loc='best') plt.grid i += 1
#Отображение данных for loc in data: if loc not in countries: continue for sub in data[loc]: for mea in data[loc][sub]: plt.subplot(len(plots), colums, plots[sub][mea]) if len(data[loc][sub][mea]["Time"]) == 1: plt.scatter(data[loc][sub][mea]["Time"], data[loc][sub][mea]["Value"], label = loc) else: plt.plot(data[loc][sub][mea]["Time"], data[loc][sub][mea]["Value"], label = loc) plt.legend()
if name != "": plt.savefig(name) plt.show()
def processing(stat, k, p): data = {} #Структура {Location: {Subject: {Measure: {Decade: {"MaxValue": MaxValue, "MinValue": MinValue}}}}}
#Сбор данных о максимальном и минимальном значении для каждой страны/показателя/единицы измерения/декады for loc in stat: data[loc] = {} for sub in stat[loc]: data[loc][sub] = {} for mea in stat[loc][sub]: data[loc][sub][mea] = {stat[loc][sub][mea]["Time"][0]//10: {"MaxValue": stat[loc][sub][mea]["Value"][0], "MinValue": stat[loc][sub][mea]["Value"][0]}} for i in range(0, len(stat[loc][sub][mea]["Time"])): temp_d = stat[loc][sub][mea]["Time"][i] // 10 if temp_d not in data[loc][sub][mea]: data[loc][sub][mea][temp_d] = {"MinValue": stat[loc][sub][mea]["Value"][i], "MaxValue": stat[loc][sub][mea]["Value"][i]} else: if data[loc][sub][mea][temp_d]["MaxValue"] < stat[loc][sub][mea]["Value"][i]: data[loc][sub][mea][temp_d]["MaxValue"] = stat[loc][sub][mea]["Value"][i] if data[loc][sub][mea][temp_d]["MinValue"] > stat[loc][sub][mea]["Value"][i]: data[loc][sub][mea][temp_d]["MinValue"] = stat[loc][sub][mea]["Value"][i]
#Отбор значений по условию задачи для декад decades = {} #Структура {Subject: {Measure: {Decade: {"Max": {"Location": [Loc], "MaxValue": [Value]}, "Min": {"Location": [Loc], "MinValue": [Min]}}}}} for loc in data: for sub in data[loc]: if sub not in decades: decades[sub] = {} for mea in data[loc][sub]: if mea not in decades[sub]: decades[sub][mea] = {} for dec in data[loc][sub][mea]: if dec not in decades[sub][mea]: decades[sub][mea][dec] = {"Max": {"Location": [], "MaxValue": []}, "Min": {"Location": [], "MinValue": []}} if k > 0: decades[sub][mea][dec]["Max"] = {"Location": [loc], "MaxValue": [data[loc][sub][mea][dec]["MaxValue"]]} if p > 0: decades[sub][mea][dec]["Min"] = {"Location": [loc], "MinValue": [data[loc][sub][mea][dec]["MinValue"]]} else: if len(decades[sub][mea][dec]["Max"]["Location"]) < k: decades[sub][mea][dec]["Max"]["Location"].append(loc) decades[sub][mea][dec]["Max"]["MaxValue"].append(data[loc][sub][mea][dec]["MaxValue"]) elif k > 0: temp_i = decades[sub][mea][dec]["Max"]["MaxValue"].index(min(decades[sub][mea][dec]["Max"]["MaxValue"])) decades[sub][mea][dec]["Max"]["Location"][temp_i] = loc decades[sub][mea][dec]["Max"]["MaxValue"][temp_i] = data[loc][sub][mea][dec]["MaxValue"] if len(decades[sub][mea][dec]["Min"]["Location"]) < p: decades[sub][mea][dec]["Min"]["Location"].append(loc) decades[sub][mea][dec]["Min"]["MinValue"].append(data[loc][sub][mea][dec]["MinValue"]) elif p > 0: temp_i = decades[sub][mea][dec]["Min"]["MinValue"].index(max(decades[sub][mea][dec]["Min"]["MinValue"])) decades[sub][mea][dec]["Min"]["Location"][temp_i] = loc decades[sub][mea][dec]["Min"]["MinValue"][temp_i] = data[loc][sub][mea][dec]["MinValue"]
#Приведение значений к виду, пригодному для отображения res = {} #Структура: {Location: {Subject: {Measure: {"Time": [Time], "Value": [Value]}}}} for sub in decades: for mea in decades[sub]: for dec in decades[sub][mea]: for i in range(0, len(decades[sub][mea][dec]["Max"]["Location"])): loc = decades[sub][mea][dec]["Max"]["Location"][i] if loc not in res: res[loc] = {} if sub not in res[loc]: res[loc][sub] = {} if mea not in res[loc][sub]: res[loc][sub][mea] = {"Time": [], "Value": []} res[loc][sub][mea]["Time"].append(dec*10) res[loc][sub][mea]["Value"].append(decades[sub][mea][dec]["Max"]["MaxValue"][i]) for i in range(0, len(decades[sub][mea][dec]["Min"]["Location"])): if decades[sub][mea][dec]["Min"]["Location"][i] in decades[sub][mea][dec]["Max"]["Location"]: continue loc = decades[sub][mea][dec]["Min"]["Location"][i] if loc not in res: res[loc] = {} if sub not in res[loc]: res[loc][sub] = {} if mea not in res[loc][sub]: res[loc][sub][mea] = {"Time": [], "Value": []} res[loc][sub][mea]["Time"].append(dec*10) res[loc][sub][mea]["Value"].append(decades[sub][mea][dec]["Min"]["MinValue"][i])
#Сохранение таблицы данных csv_writer(unchange(res), 'Result.csv')
#Отображение результата с сохранением show(res, name='Result.png')
#Старт File = csv_reader("WorkingAgePopulation.csv") Data = change(File)
show(Data)
processing(Data, 1, 2) |