

Планирование расширения
Теперь обратимся
к планированию. В нулевой части мы уже
затронули эту тему, но тогда речь была
только о двух офисах в Москве, теперь
же сеть растёт.
Будет она вот
такой:
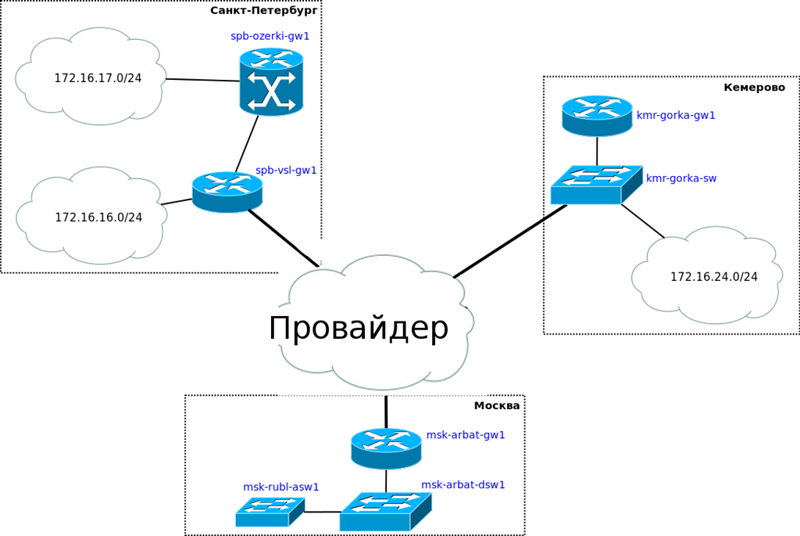 То
есть прибавляются две точки в
Санкт-Петербурге: небольшой офис на
Васильевском острове и сам завод в
Озерках — и одна в Кемерово в районе
Красная горка. Для простоты у нас будет
один провайдер “Балаган Телеком”,
который на выгодных условиях предоставит
нам L2VPN до обеих точек. В одном из следующих
выпусков мы тему различных вариантов
подключения раскроем в красках. А пока
вкратце: L2VPN — это, очень грубо говоря,
когда вам провайдер предоставляет влан
от точки до точки (можно для простоты
представить, что они включены в один
коммутатор).
Следует сказать
несколько слов об IP-адресации и делении
на подсети. В нулевой части мы уже
затронули вопросы планирования, весьма
вскользь, надо сказать. Вообще, в любой
более или менее большой компании должен
быть некий регламент — свод правил,
следуя которому вы распределяете
IP-адреса везде. Сеть у нас сейчас
разрастается и разработать его очень
важно.
Ну вот к примеру, скажем,
что для офисов в других городах это
будет так:
То
есть прибавляются две точки в
Санкт-Петербурге: небольшой офис на
Васильевском острове и сам завод в
Озерках — и одна в Кемерово в районе
Красная горка. Для простоты у нас будет
один провайдер “Балаган Телеком”,
который на выгодных условиях предоставит
нам L2VPN до обеих точек. В одном из следующих
выпусков мы тему различных вариантов
подключения раскроем в красках. А пока
вкратце: L2VPN — это, очень грубо говоря,
когда вам провайдер предоставляет влан
от точки до точки (можно для простоты
представить, что они включены в один
коммутатор).
Следует сказать
несколько слов об IP-адресации и делении
на подсети. В нулевой части мы уже
затронули вопросы планирования, весьма
вскользь, надо сказать. Вообще, в любой
более или менее большой компании должен
быть некий регламент — свод правил,
следуя которому вы распределяете
IP-адреса везде. Сеть у нас сейчас
разрастается и разработать его очень
важно.
Ну вот к примеру, скажем,
что для офисов в других городах это
будет так:
 Это
весьма упрощённый регламент, но теперь
мы во всяком случае точно знаем, что у
шлюза всегда будет 1-й адрес, до 12-го мы
будем выдавать коммутаторам и всяким
wi-fi-точкам, а все сервера будем искать
в диапазоне 172.16.х.13-172.16.х.23. Разумеется,
по своему вкусу вы можете уточнять
регламент вплоть до адреса каждого
сервера, добавлять в него правило
формирования имён устройств, доменных
имён, политику списков доступа и т.д.
Чем точнее вы сформулируете правила и
строже будете следить за их выполнением,
тем проще разбираться в структуре сети,
решать проблемы, адаптироваться к
ситуации
Это
весьма упрощённый регламент, но теперь
мы во всяком случае точно знаем, что у
шлюза всегда будет 1-й адрес, до 12-го мы
будем выдавать коммутаторам и всяким
wi-fi-точкам, а все сервера будем искать
в диапазоне 172.16.х.13-172.16.х.23. Разумеется,
по своему вкусу вы можете уточнять
регламент вплоть до адреса каждого
сервера, добавлять в него правило
формирования имён устройств, доменных
имён, политику списков доступа и т.д.
Чем точнее вы сформулируете правила и
строже будете следить за их выполнением,
тем проще разбираться в структуре сети,
решать проблемы, адаптироваться к
ситуации и наказывать виновных.
Это примерно, как схема запоминания
паролей: когда у вас есть некое правило
их формирования, вам не нужно держать
в голове несколько десятков
сложнозапоминаемых паролей, вы всегда
можете их вычислить. Вот так же и тут. Я
некогда работал в средних размеров
холдинге и знал, что если я приеду в офис
где-нибудь в забытой коровами деревне,
то там точно x.y.z.1 — это циска, x.y.z.2 —
дистрибьюшн-свитч прокурва, а x.y.z.101 —
компьютер главного бухгалтера, с которого
надо дать доступ на какой-нибудь
контур-экстерн. Другой вопрос, что надо
это ещё проверить, потому что местные
ИТшники такого порой наворотят, что
слезами омываешься сквозь смех.
Было дело парнишка решил сам управлять всем доступом в интернет (обычно это делал я на маршрутизаторе). Поставил proxy-сервер, случайно поднял на нём NAT и зарулил туда трафик локальной сети, на всех машинах прописав его в качестве шлюза по умолчанию, а потом я минут 20 разбирался, как так: у них всё работает, а мы их не видим.
IP-план
Теперь нам было
бы весьма кстати составить IP-план. Будем
исходить из того, что на всех трёх точках
мы будем использовать стандартную сеть
с маской 24 бита (255.255.255.0) Это означает,
что в них может быть 254 устройства.
Почему это так? И как вообще понять
все эти маски подсетей? В рамках одной
статьи мы не сможем этого рассказать,
иначе она получится длинная, как палуба
Титаника и запутанная, как одесские
катакомбы. Крайне рекомендуем очень
плотно познакомиться с такими понятиями,
как IP-адрес, маска подсети, их представления
в двоичном виде и CIDR (Classless InterDomain Routing)
самостоятельно. Мы же далее будем только
аргументировать выбор конкретного
размера сети. Как бы то ни было, полное
понимание придёт только с практикой.
Вообще,
очень неплохо эта тема раскрыта в этой
статье: http://habrahabr.ru/post/129664/
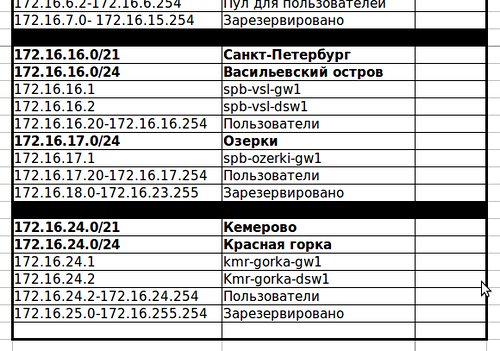
В
данный момент (вспомним нулевой
выпуск) у нас в Москве использованы
адреса 172.16.0.0-172.16.6.255. Предположим, что
сеть может ещё увеличиться здесь,
допустим, появится офис на Воробьёвых
горах и зарезервируем ещё подсети до
172.16.15.0/24 включительно.
Все эти адреса:
172.16.0.0-172.16.15.255 — можно описать так:
172.16.0.0/20. Эта сеть (с префиксом /20) будет
так называемой суперсетью, а операция
объединения подсетей в суперсети
называется суммированием подсетей
(суммированием маршрутов, если быть
точным, route summarization)
Очень наглядный
IP-калькулятор.
Я и сейчас им периодически пользуюсь,
хотя со временем приходит интуитивное
и логическое понимание соответствия
между длиной маски и границами
сети.
Теперь обратимся к Питеру.
В данный момент в этом прекрасном городе
у нас 2 точки и на каждой из них подсети
/24. Допустим это будут 172.16.16.0/24 и
172.16.17.0/24. Зарезервируем адреса
172.16.18.0-172.16.23.255 для возможного расширения
сети.
172.16.16.0-172.16.23.255 можно объединить
в 172.16.16.0/21 — в общем-то исходя именно из
этого мы и оставляем в резерв именно
такой диапазон.
В Кемерово нам
нет смысла оставлять такие огромные
запасы /21, как в Питере (2048 адресов или
8 подсетей /24), или тем более /20, как в
Москве (4096 или 16 подсетей /24). А вот 1024
адреса и 4 подсети /24, которым соответствует
маска /22 вполне рационально.
Таким
образом сеть 172.16.24.0/22 (адреса
172.16.24.0-172.16.27.255) будет у нас для
Кемерово.
 Тут
надо бы заметить: делать такой запас в
общем-то необязательно и то, что мы
зарезервировали вполне можно использовать
в любом другом месте сети. Нет табу на
этот счёт. Однако в крупных сетях именно
так и рекомендуется делать и связано
это с количеством информации в таблицах
маршрутизации.
Понимаете ли дело вот
в чём: если у вас несколько подряд идущих
подсетей разбросаны по разным концам
сети, то каждой из них соответствует
одна запись в таблице маршрутизации
каждого маршрутизатора. Если при этом
вы вдруг используете только статическую
маршрутизацию, то это ещё колоссальный
труд по настройке и отслеживанию
корректности настройки.
А если же
они у вас все идут подряд, то несколько
маленьких подсетей вы можете суммировать
в одну большую.
Поясним на примере
Санкт-Петербурга. При настройке
статической маршрутизации мы могли бы
делать так:
Тут
надо бы заметить: делать такой запас в
общем-то необязательно и то, что мы
зарезервировали вполне можно использовать
в любом другом месте сети. Нет табу на
этот счёт. Однако в крупных сетях именно
так и рекомендуется делать и связано
это с количеством информации в таблицах
маршрутизации.
Понимаете ли дело вот
в чём: если у вас несколько подряд идущих
подсетей разбросаны по разным концам
сети, то каждой из них соответствует
одна запись в таблице маршрутизации
каждого маршрутизатора. Если при этом
вы вдруг используете только статическую
маршрутизацию, то это ещё колоссальный
труд по настройке и отслеживанию
корректности настройки.
А если же
они у вас все идут подряд, то несколько
маленьких подсетей вы можете суммировать
в одну большую.
Поясним на примере
Санкт-Петербурга. При настройке
статической маршрутизации мы могли бы
делать так:
ip route 172.16.16.0 255.255.255.0 172.16.2.2 ip route 172.16.17.0 255.255.255.0 172.16.2.2 ip route 172.16.18.0 255.255.255.0 172.16.2.2 …… ip route 172.16.23.0 255.255.255.0 172.16.2.2
Это 8 команд и 8 записей в таблице. Но при этом пришедший на маршрутизатор пакет в любую из сетей 172.16.16.0/21 в любом случае будет отправлен на устройство с адресом 172.16.2.2. Вместо этого мы поступим так:
ip route 172.16.16.0 255.255.248.0 172.16.2.2
И вместо восьми
возможных сравнений будет только
одно.
Для современных устройств ни
в плане процессорного времени ни
использования памяти это уже не является
существенной нагрузкой, однако такое
планирование считается правилами
хорошего тона и в конечном итоге вам же
самим проще разобраться. Положа руку
на сердце, такое планирование скорее
исключение, нежели правило: так или
иначе фрагментация маршрутов с ростом
сети неизбежна.
Теперь ещё несколько
слов о линковых сетях. В среде сетевых
администраторов так называются сети
точка-точка (Point-to-Point) между двумя
маршрутизаторами.
Вот опять же в
примере с Питером. Два маршрутизатора
(в Москве и в Петербурге) соединены друг
с другом прямым линком (неважно, что у
провайдера это сотня коммутаторов и
маршрутизаторов — для нас это просто
влан). То есть кроме вот этих 2-х устройств
здесь не будет никаких других. Мы знаем
это наверняка. В любом случае на
интерфейсах обоих устройств (смотрящих
в сторону друг друга) нужно настраивать
IP-адреса. И нам точно незачем назначать
на этом участке сеть /24 с 254 доступными
адресами, ведь 252 в таком случае пропадут
почём зря. В этом случае есть прекрасный
выход — бесклассовая IP-адресация.
Почему
она бесклассовая? Если вы помните, то в
нулевой части мы говорили о трёх классах
подсетей: А, В и С. По идее только их вы
и могли использовать при планировании
сети. Бесклассовая междоменная
маршрутизация (CIDR)
позволяет очень гибко использовать
пространство IP-адресов.
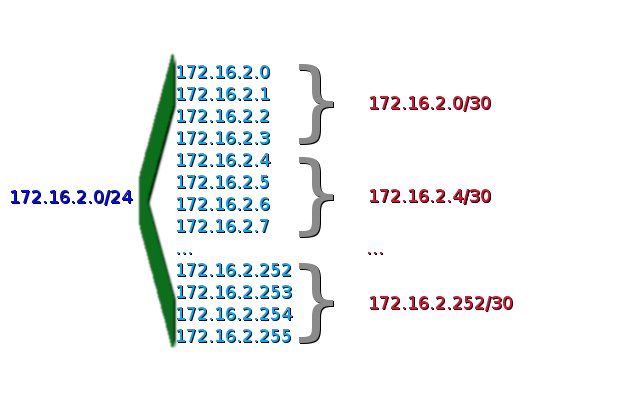
Мы просто
берём сеть с самой маленькой возможной
маской — 30 (255.255.255.252) — это сеть на 4
адреса. Почему мы не можем взять сеть с
ещё более узкой маской? Ну 32 (255.255.255.255)
по понятными причинам — это вообще один
единственный адрес, сеть 31 (255.255.255.254) —
это уже 2 адреса, но один из них (первый)
— это адрес сети, а второй (последний)
— широковещательный. В итоге на адреса
хостов у нас и не осталось ничего. Поэтому
и берём маску 30 с 4 адресами и тогда как
раз 2 адреса остаются на наши два
маршрутизатора.
Вообще говоря,
самой узкой маской для подсетей в cisco
таки является /31. При определённых
условиях их можно использовать на
P-t-P-линках.
Что же касается маски /32,
то такие подсети, которые суть один
единственный хост, используются для
назначения адресов Loopback-интерфейсам.
Именно
так мы и поступим. Для этого, собственно,
в нулевой части мы и оставили сеть
172.16.2.0/24 — её мы будем дробить на мелкие
сетки /30. Всего их получится 64 штуки,
соответственно можно назначить их на
64 линка.
 Здесь
мы поступили так же, как и в предыдущем
случае: сделали небольшой резерв для
Питера, и резерв для Кемерово. Вообще
резерв — это всегда очень хорошо о чём
бы мы ни говорили. ;)
Здесь
мы поступили так же, как и в предыдущем
случае: сделали небольшой резерв для
Питера, и резерв для Кемерово. Вообще
резерв — это всегда очень хорошо о чём
бы мы ни говорили. ;)
Вот к примеру с компьютера ПК1 — 172.16.3.2 я хочу подключиться по telnet к L3-коммутатору с адресом 172.16.17.1. Как мой компьютер узнает что делать? Куда слать данные? 1) Как вы уже знаете, если адрес получателя из другой подсети, то данные нужно отправлять на шлюз по умолчанию. 2) По уже известной вам схеме компьютер с помощью ARP-запроса добывает MAC-адрес маршрутизатора. 3) Далее он формирует кадр с инкапсулированным в него пакетом и отсылает его в порт. После того, как кадр отправлен, компьютеру уже по барабану, что происходит с ним дальше. 4) А сам кадр при этом попадает сначала на коммутатор, где решается его судьба согласно таблице MAC-адресов. А потом достигает маршрутизатора RT1. 5) Поскольку маршрутизатор ограничивает широковещательный домен — здесь жизнь этого кадра и заканчивается. Циска просто откидывает заголовок канального уровня — он уже не пригодится — извлекает из него IP-пакет. 6) Теперь маршрутизатор должен принять решение, что с ним делать дальше. Разумеется, отправить его на какой-то свой интерфейс. Но на какой? Для этого существует таблица маршрутизации, которая есть на любом рутере. Выяснить, что у нас в данный момент находится в таблице маршрутизации, можно с помощью команды show ip route:
172.16.0.0/16 is variably subnetted, 10 subnets, 3 masks C 172.16.3.0/24 is directly connected, FastEthernet0/0.101 C 172.16.2.0/30 is directly connected, FastEthernet0/1.4 S 172.16.17.0/24 [1/0] via 172.16.2.2
Каждая строка в ней — это способ добраться до той или иной сети. Вот к примеру, если пакет адресован в сеть 172.16.17.0/24, то данные нужно отправить на устройство с адресом 172.16.2.2. Таблица маршрутизации формируется из: — непосредственно подключенных сетей (directly connected) — это сети, которые начинаются непосредственно на нём. В примере 172.16.3.0/24 и 172.16.2.0/30. В таблице они обозначаются буквой C — статический маршруты — это те, которые вы прописали вручную командой ip route. Обозначаются буквой S — маршруты, полученные с помощью протоколов динамической маршрутизации (OSPF, EIGRP, RIP и других). 7) Итак, данные в сеть 172.16.17.0 (а мы хотим подключиться к устройству 172.16.17.1) должны быть отправлены на следующий хоп — следующий прыжок, которым является маршрутизатор 172.16.2.2. Причём из таблицы маршрутизации видно, что находится следующий хоп за интерфейсом FE0/1.4 (подсеть 172.16.2.0/30). 8)Если в ARP-кэше циски нет MAC-адреса, то надо снова выполнить ARP-запрос, чтобы узнать MAC-адрес устройства с IP-адресом 172.16.2.2. RT1 посылает широковещательный кадр с порта FE0/1.4. В этом широковещательном домене у нас два устройства, и соответственно только один получатель. RT2 получает ARP-запрос, отбрасывает заголовок Ethernet и, понимая из данных протокола ARP, что искомый адрес принадлежит ему отправляет ARP-ответ со своим MAC-адресом. 9) Изначальный IP-пакет, пришедший на RT1 не меняется, он инкапсулируется в совершенно новый кадр и отправляется в порт FE0/1.4, получая при этом метку 4-го влана. 10) Полностью аналогичные действия происходят на следующем маршрутизаторе. И на следующем и следующем (если бы они были), пока пакет не дойдёт до последнего, к которому и подключена нужная сеть. 11) Последний маршрутизатор (коим является L3-коммутатор) видит, что искомый адрес принадлежит ему самому, а извлекая данные транспортного уровня, понимает, что это телнет и передаёт все данные верхним уровням. Так вот и путешествуют данные с одного хопа на другой и ни один маршрутизатор представления не имеет о дальнейшей судьбе пакета. Более того, он даже не знает есть ли там действительно эта сеть — он просто доверяет своей таблице маршрутизации.