

6.2 Описание программы для выполнения работы
Лабораторный макет представляет собой программный пакет обладающий следующими функциями:
- проводить оценку статистических и информационных характеристик дискретных источников информации (для источников с наличием и отсутствием зависимости между соседними символами);
- моделирование дискретного источника информации цепью Маркова 0-го, 1-го и более высокого порядка;
- кодирование и декодирование сообщений источника неравномерным посимвольным кодом Шеннона-Фано, Хаффмана
- кодирование и декодирование сообщений источника алгоритмом арифметического кодирования.
6.3 Порядок выполнения работы
Перед началом работы задайте программе каталог, в который будут помещаться результаты работы.
Задайте в программе таблицу статистики появления символов согласно своему варианту и таблице 6.1. Для этого необходимо произвести пересчет частот появления символов в оценку вероятности их появления.
Постройте с помощью программы код Шеннона-Фано. Результат занесите в отчет, заполнив таблицу 6.3 и отразив ход построения кода.

Постройте с помощью программы код Хаффмана. Результат занесите в отчет (заполнить таблицу 6.3 и зарисовать полученное кодовое дерево).
Закодируйте полученными кодами сообщение согласно своему варианту и таблице 6.1. Сравните полученные закодированные сообщения и их длины.
Внесите в закодированное сообщение однократную ошибку, инвертировав один из битов, и декодируйте искаженное сообщение с помощью программы, проанализируйте полученный результат, определите трек ошибок и сделайте выводы.
Для выполнения следующих пунктов заготовьте в отчете таблицу 6.4.
Проинициализируйте таблицу вероятности появления символов в текстах на русском или английском языке (согласно варианту). Для этого необходимо загрузить заданный преподавателем текстовый файл, приняв длину символов источника равной одной букве.
Постройте с помощью программы код Шеннона-Фано.
Определите с помощью программы информационные характеристики полученного кода. Результат занести в отчет (таблица 6.4).
Закодируйте полученным кодом заданный преподавателем текстовый файл, определите длину полученного закодированного сообщения, и коэффициент сжатия. Результат занести в таблицу 6.4.
Постройте с помощью программы код Хаффмана.
Повторите эксперимент с полученным кодом аналогично п.10, 11. Результат занести в таблицу 6.4.
Повторите эксперимент п.8-13, приняв длину символов источника равной двум, трем и четырем буквам. Результат занести в таблицу 6.4.
Повторите эксперимент п.8-13, приняв длину символов источника равной одному, двум, трем и четырем битам. Результат занести в таблицы 6.3 и 6.4 (таблицу 6.3 заполнять для каждого значения длины символов источника).
Задайте в программе таблицу статистики появления символов аналогично п.2. Закодируйте арифметическим алгоритмом сообщение согласно своему варианту и таблице 6.1. Процесс кодирования занесите в отчет. Определите длину сообщения и основные информационные характеристики.
Задайте в программе таблицу статистики появления символов аналогично п.8. Закодируйте арифметическим алгоритмом файл, заданный преподавателем, определите его длину и основные информационные характеристики. Результат занести в таблицу 6.4.
Таблица 6.4.

nи – количество символов в букве укрупненного алфавита источника (длина кодируемого блока);
N – мощность алфавита источника;
Hmax – максимальная энтропия для данного алфавита источника;
H(x) – энтропия источника;
H1(x) – удельная энтропия на один символ источника;
I(S) – количество информации содержащееся в сообщении;
rи – избыточность источника;
rк – избыточность кода;
– средняя длина кодового слова;
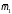 – средняя
длина кодового слова на один символ
источника;
– средняя
длина кодового слова на один символ
источника;
m(S) – длина закодированного сообщения;
h – коэффициент сжатия.
Содержание отчета
Отчет должен содержать:
- Цель работы.
- Исходные данные из таблицы 6.1 согласно своему варианту и результаты пересчета частоты появления символов в вероятности их появления.
- Заполненную в результате выполнения п.3 и п.4 таблицу 6.3.
- Рисунки, поясняющие процесс построения кода Шеннона-Фано и кода Хаффмана.
- Закодированные каждым из полученных кодов сообщения, искаженное закодированное сообщение, результат его декодирования и результат расчета трека ошибок.
- Заполненную в результате выполнения п.10, 11, 13, 14, 15, 17 таблицу 6.4.
- Заполненную в результате выполнения п.15 таблицу 6.3, для каждого значения длины символа источника (1, 2, 3, 4 бита).
- Рисунок, поясняющий процесс построения кода с помощью арифметического алгоритма, а также результаты расчета информационных параметров полученного закодированного сообщения.
- Анализ полученных результатов и выводы.
Контрольные вопросы и задания
Префиксные коды. Неравенство Крафта.
Поясните преимущества блочного кодирования и его особенности.
Что такое "неприводимость" кода?
Сущность и методы эффективного кодирования.
Поясните процедуру кодирования по методу Хаффмана. Назовите достоинства процедуры Хаффмана.
Перечислите достоинства эффективных кодов и возможности их применения.
Как влияют помехи на декодирование сообщений при эффективном кодировании?
Предельные возможности эффективного кодирования.
Сравните пропускные способности двух дискретных каналов без помех, если в первом канале используются сигналы с основанием кода N= 2 при технической скорости передачи В = 100 Бод, а во втором канале основание кода N = 8 и В = 40 Бод.
Закодировать двоичным кодом Шеннона - Фано множество из пяти сообщений с вероятностями P1 = 0,4; P2 = P3 = P4 = P5 = 0,15. Оценить среднюю длину кодовых слов
 .
.Закодировать сообщения этого же источника кодом Хаффмана, определить среднюю длину кодовых слов . Сравнить результаты кодирования по этим двум методам и сделать выводы.