

Бази даних-20210115T104840Z-001 / Реферат на тему _Современные СУБД_ / Using_MySql,_MS_SQL_Server_and_Oracle(1)
.pdfПример 2: выборка данных без повторения
MS SQL Решение 2.1.2.b
1SELECT [s_name],
2COUNT(*) AS [people_count]
3 |
|
FROM |
[subscribers] |
4 |
|
GROUP |
BY [s_name] |
Oracle Решение 2.1.2.b
1SELECT "s_name",
2COUNT(*) AS "people_count"
3 |
|
FROM |
"subscribers" |
4 |
|
GROUP |
BY "s_name" |
Агрегирующая функция COUNT(*) (представленная во второй строке всех запросов 2.1.2.b) производит подсчёт записей, сгруппированных по совпадению значения поля s_name (см. четвёртую строку в запросах 2.1.2.b).
Для быстрого понимания логики группировок можно использовать аналогию с объединением ячеек с одинаковыми значениями в таблице Word или Excel, после чего происходит анализ (чаще всего — подсчёт или суммирование) ячеек, соответствующих каждой такой «объединённой ячейке». В только что рассмотренном примере 2.1.2.b эту аналогию можно выразить следующим образом:
s_id s_name
1Иванов И.И.
2Петров П.П.
3Сидоров С.С.
Теперь СУБД считает строки таблицы в контексте выполненной группировки, и получает, что Иванова и Петрова у нас по одному человеку, а Сидоровых — два, что и отражено в ожидаемом результате 2.1.2.b.
Задание 2.1.2.TSK.A: показать без повторений идентификаторы книг, которые были взяты читателями.
Задание 2.1.2.TSK.B: показать по каждой книге, которую читатели брали в библиотеке, количество выдач этой книги читателям.
Работа с MySQL, MS SQL Server и Oracle в примерах © EPAM Systems, RD Dep, 2016–2018 Стр: 20/545

Пример 3: использование функции COUNT и оценка её производительности
2.1.3.Пример 3: использование функции COUNT и оценка её производительности
Задача 2.1.3.a{21}: показать, сколько всего разных книг зарегистрировано в библиотеке.
Ожидаемый результат 2.1.3.a.
total_books
7
Решение 2.1.3.a{21}.
Если переформулировать задачу, она будет звучать как «показать, сколько всего записей есть в таблице books», и решение выглядит так.
MySQL |
Решение 2.1.3.a |
||
1 |
SELECT |
COUNT(*) AS `total_books` |
|
2 |
FROM |
`books` |
|
|
|
||
MS SQL |
Решение 2.1.3.a |
||
1 |
SELECT |
COUNT(*) AS [total_books] |
|
2 |
FROM |
[books] |
|
|
|
|
|
Oracle Решение 2.1.3.a
1SELECT COUNT(*) AS "total_books"
2FROM "books"
Функция COUNT может быть использована в следующих пяти форматах:
•COUNT(*) — классический вариант, используемый для подсчёта количества записей;
•COUNT(1) — альтернативная запись классического варианта;
•COUNT(первичный_ключ) — альтернативная запись классического варианта;
•COUNT(поле) — подсчёт записей, в указанном поле которых нет NULL- значений;
•COUNT(DISTINCT поле) — подсчёт без повторения записей, в указанном поле которых нет NULL-значений.
Одним из самых частых вопросов относительно разных вариантов COUNT является вопрос о производительности: какой вариант работает быстрее?
Исследование 2.1.3.EXP.A: оценка скорости работы различных вариантов COUNT в зависимости от объёма обрабатываемых данных. Это исследование — единственное, в котором кэш СУБД не будет сбрасываться перед выполнением каждого следующего запроса.
В базе данных «Исследование» создадим таблицу test_counts, содержащую такие поля:
•id — автоинкрементируемый первичный ключ (число);
•fni — поле без индекса («field, no index») (число или NULL);
•fwi — поле с индексом («field, with index») (число или NULL);
•fni_nn — поле без индекса и NULL’ов («field, no index, no nulls») (число);
•fwi_nn — поле с индексом без NULL’ов («field, with index, no nulls») (число).
Работа с MySQL, MS SQL Server и Oracle в примерах © EPAM Systems, RD Dep, 2016–2018 Стр: 21/545

Пример 3: использование функции COUNT и оценка её производительности
dm MySQL |
dm SQLServ er2012 |
||
|
test_counts |
|
test_counts |
«column» |
«column» |
||
*PK |
id: INT |
*PK |
id: int |
|
fni: INT |
|
fni: int |
|
fwi: INT |
|
fwi: int |
* |
fni_nn: INT |
* |
fni_nn: int |
* |
fwi_nn: INT |
* |
fwi_nn: int |
«PK» |
«PK» |
||
+ |
PK_test_counts(INT) |
+ |
PK_test_counts(int) |
«index» |
«index» |
||
+ |
idx_fwi(INT) |
+ |
idx_fwi(int) |
+ |
idx_fwi_nn(INT) |
+ |
idx_fwi_nn(int) |
dm Oracle
test_counts
«column» *PK id: NUMBER(10) fni: NUMBER(10) fwi: NUMBER(10)
*fni_nn: NUMBER(10)
*fwi_nn: NUMBER(10)
«PK»
+PK_test_counts(NUMBER)
«index»
+idx_fwi(NUMBER)
+idx_fwi_nn(NUMBER)
MySQL |
MS SQL Server |
Oracle |
Рисунок 2.1.a — Таблица test_counts во всех трёх СУБД
Суть исследования состоит в последовательном добавлении в таблицу по тысяче записей (от нуля до десяти миллионов с шагом в тысячу) и выполнении следующих семи запросов с COUNT после добавления каждого десятка тысяч записей:
MySQL Исследование 2.1.3.EXP.A
1-- Вариант 1: COUNT(*)
2SELECT COUNT(*)
3 FROM `test_counts`
1-- Вариант 2: COUNT(первичный_ключ)
2SELECT COUNT(`id`)
3 FROM `test_counts`
1-- Вариант 3: COUNT(1)
2SELECT COUNT(1)
3 FROM `test_counts`
1-- Вариант 4: COUNT(поле_без_индекса)
2SELECT COUNT(`fni`)
3 FROM `test_counts`
1-- Вариант 5: COUNT(поле_с_индексом)
2SELECT COUNT(`fwi`)
3 FROM `test_counts`
1-- Вариант 6: COUNT(DISTINCT поле_без_индекса)
2SELECT COUNT(DISTINCT `fni`)
3 FROM `test_counts`
1-- Вариант 7: COUNT(DISTINCT поле_с_индексом)
2SELECT COUNT(DISTINCT `fwi`)
3 FROM `test_counts`
MS SQL Исследование 2.1.3.EXP.A
1-- Вариант 1: COUNT(*)
2SELECT COUNT(*)
3 FROM [test_counts]
1-- Вариант 2: COUNT(первичный_ключ)
2SELECT COUNT([id])
3 FROM [test_counts]
1-- Вариант 3: COUNT(1)
2SELECT COUNT(1)
3 FROM [test_counts]
1-- Вариант 4: COUNT(поле_без_индекса)
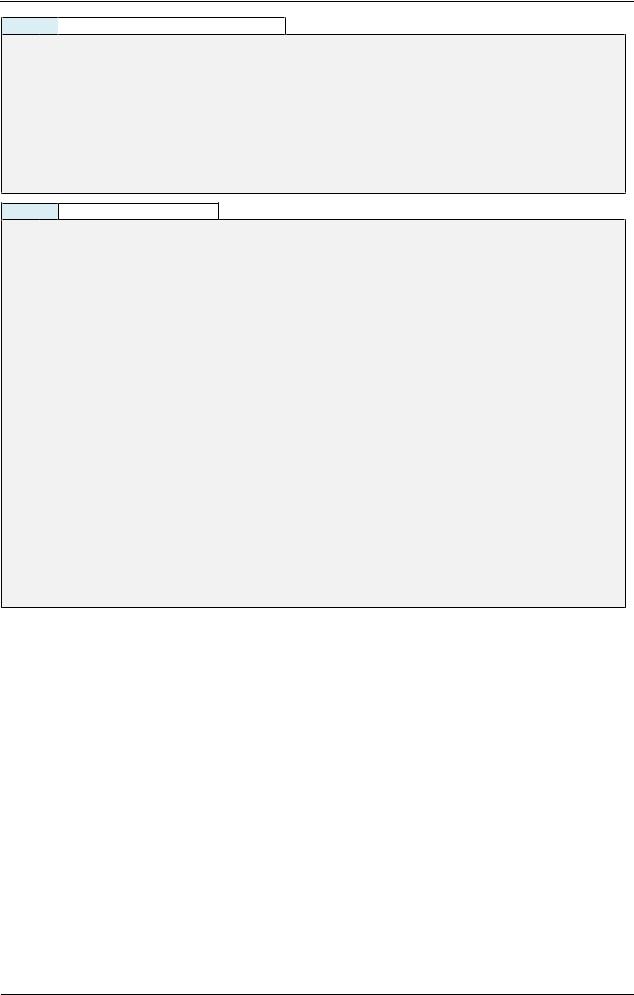
2SELECT COUNT([fni])
3FROM [test_counts]
Работа с MySQL, MS SQL Server и Oracle в примерах © EPAM Systems, RD Dep, 2016–2018 Стр: 22/545
Пример 3: использование функции COUNT и оценка её производительности
MS SQL  Исследование 2.1.3.EXP.A (продолжение)
Исследование 2.1.3.EXP.A (продолжение)
1-- Вариант 5: COUNT(поле_с_индексом)
2SELECT COUNT([fwi])
3 FROM [test_counts]
1-- Вариант 6: COUNT(DISTINCT поле_без_индекса)
2SELECT COUNT(DISTINCT [fni])
3 FROM [test_counts]
1-- Вариант 7: COUNT(DISTINCT поле_с_индексом)
2SELECT COUNT(DISTINCT [fwi])
3 FROM [test_counts]
Oracle Исследование 2.1.3.EXP.A
1-- Вариант 1: COUNT(*)
2SELECT COUNT(*)
3 FROM "test_counts"
1-- Вариант 2: COUNT(первичный_ключ)
2SELECT COUNT("id")
3 FROM "test_counts"
1-- Вариант 3: COUNT(1)
2SELECT COUNT(1)
3 FROM "test_counts"
1-- Вариант 4: COUNT(поле_без_индекса)
2SELECT COUNT("fni")
3 FROM "test_counts"
1-- Вариант 5: COUNT(поле_с_индексом)
2SELECT COUNT("fwi")
3 FROM "test_counts"
1-- Вариант 6: COUNT(DISTINCT поле_без_индекса)
2SELECT COUNT(DISTINCT "fni")
3 FROM "test_counts"
1-- Вариант 7: COUNT(DISTINCT поле_с_индексом)
2SELECT COUNT(DISTINCT "fwi")
3 FROM "test_counts"
В первую очередь рассмотрим время, затраченное каждой СУБД на вставку тысячи записей, и зависимость этого времени от количества уже имеющихся в таблице записей. Соответствующие данные представлены на рисунке 2.1.b.
Как видно из графика, даже на таком относительно небольшом объёме данных все три СУБД показали падение производительности операции вставки ближе к концу эксперимента. Сильнее всего данный эффект проявился у Oracle. MySQL показал наименьшее время выполнения операции на протяжении всего эксперимента (также результаты MySQL оказались самыми стабильными).
Работа с MySQL, MS SQL Server и Oracle в примерах © EPAM Systems, RD Dep, 2016–2018 Стр: 23/545

Пример 3: использование функции COUNT и оценка её производительности
Рисунок 2.1.b — Время, затраченное каждой СУБД на вставку тысячи записей
Теперь посмотрим на графики зависимости времени выполнения каждого из семи рассмотренных выше запросов 2.1.3.EXP.A от количества данных в таблице.
На рисунках 2.1.c, 2.1.d, 2.1.e приведены графики для MySQL, MS SQL Server и Oracle соответственно.
Рисунок 2.1.c — Время, затраченное MySQL на выполнение разных COUNT
Работа с MySQL, MS SQL Server и Oracle в примерах © EPAM Systems, RD Dep, 2016–2018 Стр: 24/545

Пример 3: использование функции COUNT и оценка её производительности
Рисунок 2.1.d — Время, затраченное MS SQL Server на выполнение разных
COUNT
Рисунок 2.1.e — Время, затраченное Oracle на выполнение разных COUNT
Чтобы увидеть всю картину целиком, представим в таблице значения медиан времени выполнения каждого запроса 2.1.3.EXP.A для каждой СУБД:
|
MySQL |
|
MS SQL Server |
Oracle |
|
COUNT(*) |
36.662 |
|
0.702 |
0.541 |
|
COUNT(id) |
11.120 |
|
0.679 |
0.001 |
|
COUNT(1) |
9.995 |
|
0.681 |
0.001 |
|
COUNT(fni) |
6.999 |
|
1.494 |
0.001 |
|
COUNT(fwi) |
12.333 |
|
1.475 |
0.001 |
|
COUNT(DISTINCT fni) |
9.252 |
|
6.300 |
0.001 |
|
COUNT(DISTINCT fwi) |
9.626 |
|
1.743 |
0.001 |
|
|
|
|
|
|
|
Работа с MySQL, MS SQL Server и Oracle в примерах |
© EPAM Systems, RD Dep, 2016–2018 Стр: 25/545 |
||||

Пример 3: использование функции COUNT и оценка её производительности
Здесь можно увидеть несколько странную картину.
Для MySQL подтверждается бытующее мнение о том, что COUNT(*) работает медленнее всего, но неожиданно самым быстрым оказывается вариант с COUNT(поле_без_индекса). Однако стоит отметить, что на меньшем объёме данных (до миллиона записей) ситуация оказывается совершенно иной — быстрее всего работает COUNT(*).
MS SQL Server показал ожидаемые результаты: COUNT(первичный_ключ) оказался самым быстрым, COUNT(DISTINCT поле_без_индекса) — самым медленным. На меньших объёмах данных этот результат не меняется.
И теперь самое интересное — результаты Oracle: здесь снова подтвердились слухи о медленной работе COUNT(*), но все остальные запросы показали потрясающий результат, очень высокую стабильность этого результата и полную независимость от объёма анализируемых данных. (Обратитесь к документации по Oracle, чтобы узнать, как этой СУБД удаётся так быстро выполнять некоторые виды
COUNT).
Пусть данное исследование и не претендует на научный подход, но общая рекомендация состоит в том, чтобы использовать COUNT(1) как в среднем один из самых быстрых вариантов для разных СУБД и разных объёмов данных, т.к. остальные варианты иногда оказываются быстрее, но иногда и медленнее.
Исследование 2.1.3.EXP.B: рассмотрим, как функция COUNT реагирует на NULL-значения и на повторяющиеся значения в DISTINCT-режиме. Добавим в базу данных «Исследование» таблицу table_with_nulls.
dm MySQL |
dm SQLServ er2012 |
dm Oracle
table_w ith_nulls |
table_with_nulls |
«column» |
«column» |
x: INT |
x: int |
table_w ith_nulls
«column» x: NUMBER(10)
MySQL |
MS SQL Server |
Oracle |
Рисунок 2.1.f — Таблица table_with_nulls во всех трёх СУБД
Поместим в созданную таблицу следующие данные (одинаковые для всех трёх СУБД):
x
1
1
2
NULL
Выполним следующие запросы на подсчёт количества записей в этой таб-
лице:
MySQL Исследование 2.1.3.EXP.B
1-- Вариант 1: COUNT(*)
2SELECT COUNT(*) AS `total_records`
3 FROM `table_with_nulls`
1-- Вариант 2: COUNT(1)
2SELECT COUNT(1) AS `total_records`
3FROM `table_with_nulls`
Работа с MySQL, MS SQL Server и Oracle в примерах © EPAM Systems, RD Dep, 2016–2018 Стр: 26/545

Пример 3: использование функции COUNT и оценка её производительности
MS SQL Исследование 2.1.3.EXP.B
1-- Вариант 1: COUNT(*)
2SELECT COUNT(*) AS [total_records]
3 FROM [table_with_nulls]
1-- Вариант 2: COUNT(1)
2SELECT COUNT(1) AS [total_records]
3 FROM [table_with_nulls]
Oracle Исследование 2.1.3.EXP.B
1-- Вариант 1: COUNT(*)
2SELECT COUNT(*) AS "total_records"
3 FROM "table_with_nulls"
1-- Вариант 2: COUNT(1)
2SELECT COUNT(1) AS "total_records"
3FROM "table_with_nulls"
Все шесть запросов во всех СУБД вернут одинаковый результат:
total_records
4
Теперь выполним запрос с COUNT, где аргументом будет являться имя поля:
MySQL |
Исследование 2.1.3.EXP.B |
1-- Вариант 3: COUNT(поле)
2SELECT COUNT(`x`) AS `total_records`
3 FROM `table_with_nulls`
MS SQL |
Исследование 2.1.3.EXP.B |
1-- Вариант 3: COUNT(поле)
2SELECT COUNT([x]) AS [total_records]
3 FROM [table_with_nulls]
Oracle |
Исследование 2.1.3.EXP.B |
1-- Вариант 3: COUNT(поле)
2SELECT COUNT("x") AS "total_records"
3FROM "table_with_nulls"
Поскольку в таком случае подсчёт не учитывает NULL-значения, во всех трёх СУБД получится следующий результат:
total_records
3
И, наконец, выполним запрос с COUNT в DISTINCT-режиме:
MySQL Исследование 2.1.3.EXP.B
1-- Вариант 4: COUNT(DISTINCT поле)
2SELECT COUNT(DISTINCT `x`) AS `total_records`
3 FROM `table_with_nulls`
MS SQL Исследование 2.1.3.EXP.B
1-- Вариант 4: COUNT(DISTINCT поле)
2SELECT COUNT(DISTINCT [x]) AS [total_records]
3 FROM [table_with_nulls]
Oracle Исследование 2.1.3.EXP.B
1-- Вариант 4: COUNT(DISTINCT поле)
2SELECT COUNT(DISTINCT "x") AS "total_records"
3FROM "table_with_nulls"
Работа с MySQL, MS SQL Server и Oracle в примерах © EPAM Systems, RD Dep, 2016–2018 Стр: 27/545

Пример 3: использование функции COUNT и оценка её производительности
В таком режиме COUNT не учитывает не только NULL-значения, но и все дубликаты значений (в наших исходных данных значение «1» было представлено дважды). Итого, результат выполнения запроса во всех трёх СУБД:
total_records
2
Осталось проверить, как COUNT работает на пустом множестве значений. Изменим запрос так, чтобы в выборку не попадал ни один ряд:
MySQL Исследование 2.1.3.EXP.B
1-- Вариант 5: COUNT(поле_из_пустого_множества_записей)
2SELECT COUNT(`x`) AS `negative_records`
3 |
|
FROM |
`table_with_nulls` |
4 |
|
WHERE |
`x` < 0 |
|
|
|
|
MS SQL Исследование 2.1.3.EXP.B
1-- Вариант 5: COUNT(поле_из_пустого_множества_записей)
2SELECT COUNT([x]) AS [negative_records]
3 |
|
FROM |
[table_with_nulls] |
4 |
|
WHERE |
[x] < 0 |
Oracle Исследование 2.1.3.EXP.B
1-- Вариант 5: COUNT(поле_из_пустого_множества_записей)
2SELECT COUNT("x") AS "negative_records"
3 |
|
FROM |
"table_with_nulls" |
4 |
|
WHERE |
"x" < 0 |
|
|
|
|
Все три СУБД возвращают одинаковый легко предсказуемый результат:
negative_records
0
Задание 2.1.3.TSK.A: показать, сколько всего читателей зарегистрировано в библиотеке.
Работа с MySQL, MS SQL Server и Oracle в примерах © EPAM Systems, RD Dep, 2016–2018 Стр: 28/545

Пример 4: использование функции COUNT в запросе с условием
2.1.4.Пример 4: использование функции COUNT в запросе с условием
Задача 2.1.4.a{29}: показать, сколько всего экземпляров книг выдано читателям.
Задача 2.1.4.b{30}: показать, сколько всего разных книг выдано читателям.
Ожидаемый результат 2.1.4.a.
in_use
5
Ожидаемый результат 2.1.4.b.
in_use
4
Решение 2.1.4.a{29}.
Вся информация о выданных читателям книгах (фактах выдачи и возврата) хранится в таблице subscriptions, поле sb_book которой содержит идентификатор выданной книги. Поле sb_is_active содержит значение Y в случае, если книга сейчас находится у читателя (не возвращена в библиотеку).
Таким образом, нас будут интересовать только строки со значением поля sb_is_active равным Y (что отражено в секции WHERE, см. третью строку всех шести запросов 2.1.4.a-2.1.4.b), а разница между задачами 2.1.4.a и 2.1.4.b состоит в том, что в первом случае мы просто считаем все случаи «книга находится у читателя», а во втором случае мы не учитываем повторения (когда на руки выдано несколько экземпляров одной и той же книги) — и достигаем это за счёт COUNT(DISTINCT поле).
MySQL |
Решение 2.1.4.a |
|
||
1 |
SELECT |
COUNT(`sb_book`) |
AS `in_use` |
|
2 |
FROM |
`subscriptions` |
|
|
3 |
WHERE |
`sb_is_active` = |
'Y' |
|
|
|
|
||
MS SQL |
Решение 2.1.4.a |
|
||
1 |
SELECT |
COUNT([sb_book]) |
AS [in_use] |
|
2 |
FROM |
[subscriptions] |
|
|
3 |
WHERE |
[sb_is_active] = |
'Y' |
|
|
|
|
|
|
Oracle |
|
Решение 2.1.4.a |
|
|
1 |
SELECT |
COUNT("sb_book") |
AS "in_use" |
|
2 |
FROM |
"subscriptions" |
|
|
3 |
WHERE |
"sb_is_active" = |
'Y' |
|
Работа с MySQL, MS SQL Server и Oracle в примерах © EPAM Systems, RD Dep, 2016–2018 Стр: 29/545