

3736
.pdf-в поле случайное рассеивание вводится произвольное значение, для которого необходимо генерировать случайные числа. Впоследствии можно снова использовать это значение для получения тех же самых случайных чисел.
-выходной диапазон вводится ссылка на левую верхнюю ячейку выходного диапазона. Размер выходного диапазона будет определен автоматически, и на экран будет выведено сообщение в случае возможного наложения выходного диапазона на исходные данные.
Рассмотрим пример.
Пример 3. Повар столовой туристической базы может готовить 4 различных первых блюда (уха, щи, борщ, грибной суп). Необходимо составить меню на месяц, так чтобы первые блюда чередовались в случайном порядке.
Решение
1.Пронумеруем первые блюда по порядку: 1 — уха, 2 — щи, 3 — борщ, 4 — грибной суп. Введем числа 1-4 в диапазон А2:А5 рабочей таблицы.
2.Укажем желаемую вероятность появления каждого первого блюда. Пусть все блюда будут равновероятны (р=1/4). Вводим число 0,25 в диапазон В2:В5.
3.В меню Сервис выбираем пункт Анализ данных и далее указываем строку Генерация случайных чисел. В появившемся диалоговом окне указываем Число переменных —
1, Число случайных чисел — 30 (количество дней в месяце). В поле Распределение
указываем Дискретное (только натуральные числа). В поле Входной интервал значений и вероятностей вводим (мышью) диапазон, содержащий номера супов и их вероятности. – А2:В5.
4.Указываем выходной диапазон и нажимаем ОК. В столбце С появляются случайные числа: 1,
2, 3, 4.
Задание для самостоятельной работы
1.Сформировать выборку из 10 случайных чисел, лежащих в диапазоне от 0 до 1.
2.Сформировать выборку из 20 случайных чисел, лежащих в диапазоне от 5 до
20.
3.Составить график патрулирования в лесу на 10 дней, так чтобы дистанция, пройденная за 1 день, случайным образом менялась от 5 до 10 км.
4.Составить расписание на месяц для случайной демонстрации на телевидении одного из четырех рекламных роликов о пожарной безопасности в лесу. Причем вероятность появления рекламного ролика №1 должна быть в два раза выше, чем остальных рекламных роликов.
11
3.Использование электронных таблиц Excel для построения выборочных функций распределения
Рассмотренные в лабораторной работе 2 распределения вероятностей СВ опираются на знание закона распределения СВ. Для практических задач такое знание – редкость. Здесь закон распределения обычно неизвестен, или известен с точностью до некоторых неизвестных параметров. В частности, невозможно рассчитать точное значение соответствующих вероятностей, так как нельзя определить количество общих и благоприятных исходов. Поэтому вводится статистическое определение вероятности. По этому определению вероятность равна отношению числа испытаний, в которых событие произошло, к общему числу произведенных испытаний. Такая вероятность называется статистической частотой.
Связь между эмпирической функцией распределения и функцией распределения (теоретической функцией распределения) такая же, как связь между частотой события и его вероятностью.
Для построения выборочной функции распределения весь диапазон изменения случайной величины X (выборки) разбивают на ряд интервалов (карманов) одинаковой ширины. Число интервалов обычно выбирают не менее 3 и не более 15. Затем определяют число значений случайной величины X, попавших в каждый интервал (абсолютная частота, частота интервалов).
Частота интервалов – число, показывающее сколько раз значения, относящиеся к каждому интервалу группировки, встречаются в выборке. Поделив эти числа на общее количество наблюдений (n), находят относительную частоту (частость) попадания случайной величины X в заданные интервалы.
По найденным относительным частотам строят гистограммы выборочных функций распределения. Гистограмма распределения частот – это графическое представление выборки, где по оси абсцисс (ОХ) отложены величины интервалов, а по оси ординат (ОУ) – величины частот, попадающих в данный классовый интервал. При увеличении до бесконечности размера выборки выборочные функции распределения превращаются в теоретические: гистограмма превращается в график плотности распределения.
Накопленная частота интервалов – это число, полученное последовательным суммированием частот в направлении от первого интервала к последнему, до того интервала включительно, для которого определяется накопленная частота.
В Excel для построения выборочных функций распределения используются специальная функция ЧАСТОТА и процедура Гистограмма из пакета анализа.
Функция ЧАСТОТА (массив_данных, двоичный_массив) вычисляет частоты появления случайной величины в интервалах значений и выводит их как массив цифр, где
•массив_данных — это массив или ссылка на множество данных, для которых вычисляются частоты;
•двоичный_массив — это массив интервалов, по которым группируются значения выборки.
12
Процедура Гистограмма из Пакета анализа выводит результаты выборочного распределения в виде таблицы и графика. Параметры диалогового окна Гистограмма:
•Входной диапазон - диапазон исследуемых данных (выборка);
•Интервал карманов - диапазон ячеек или набор граничных значений, определяющих выбранные интервалы (карманы). Эти значения должны быть введены в
возрастающем порядке. Если диапазон карманов не был введен, то набор интервалов, равномерно распределенных между минимальным и максимальным значениями данных, будет создан автоматически.
•выходной диапазон предназначен для ввода ссылки на левую верхнюю ячейку выходного диапазона.
•переключатель Интегральный процент позволяет установить режим включения
вгистограмму графика интегральных процентов.
•переключатель Вывод графика позволяет установить режим автоматического создания встроенной диаграммы на листе, содержащем выходной диапазон.
Пример 1. Построить эмпирическое распределение веса кроны деревьев в килограммах для следующей выборки: 64, 57, 63, 62, 58, 61, 63, 70, 60, 61, 65, 62, 62, 40,
64, 61, 59, 59, 63, 61.
Решение
1.В ячейку А1 введите слово Наблюдения, а в диапазон А2:А21 — значения веса кроны деревьев (см. рис. 1).
2.В ячейку В1 введите названия интервалов Вес, кг. В диапазон В2:В8 введите граничные значения интервалов (40, 45, 50, 55, 60, 65, 70).
3.Введите заголовки создаваемой таблицы: в ячейки С1 — Абсолютные частоты, в
ячейки D1 — Относительные частоты, в ячейки E1 — Накопленные частоты.(см.
рис. 1).
4.С помощью функции Частота заполните столбец абсолютных частот, для этого выделите блок ячеек С2:С8. С панели инструментов Стандартная вызовите Мастер функций (кнопка fx). В появившемся диалоговом окне выберите категорию Статистические и функцию ЧАСТОТА, после чего нажмите кнопку ОК. Указателем мыши в рабочее поле Массив_данных введите диапазон данных наблюдений (А2:А21). В рабочее поле Двоичный_массив мышью введите диапазон интервалов (В2:В8). Слева на клавиатуре последовательно нажмите комбинацию клавиш Ctrl+Shift+Enter. В столбце C должен появиться массив абсолютных частот (см. рис.2).
5.В ячейке C9 найдите общее количество наблюдений. Активизируйте ячейку С9, на панели инструментов Стандартная нажмите кнопку Автосумма. Убедитесь, что диапазон суммирования указан правильно и нажмите клавишу Enter.
6.Заполните столбец относительных частот. В ячейку введите формулу для вычисления относительной частоты: =C2/$C$9. Нажмите клавишу Enter. Протягиванием (за правый нижний угол при нажатой левой кнопке мыши) скопируйте введенную формулу в диапазон и получите массив относительных частот.
7.Заполните столбец накопленных частот. В ячейку E2 скопируйте значение относительной частоты из ячейки D2. В ячейку D3 введите формулу: =E2+D3. Нажмите клавишу Enter. Протягиванием (за правый нижний угол при нажатой левой кнопке
мыши) скопируйте введенную формулу в диапазон D3:D8. Получим массив
13

накопленных частот.
Рис. 2. Результат вычислений из примера 1
8.Постройте диаграмму относительных и накопленных частот. Щелчком указателя мыши по кнопке на панели инструментов вызовите Мастер диаграмм. В появившемся диалоговом окне выберите закладку Нестандартные и тип диаграммы График/гистограмма. После редактирования диаграмма будет иметь такой вид, как на рис. 3.
0.7 |
|
|
|
|
|
1.2 |
|
0.6 |
|
|
|
|
|
1 |
|
|
|
|
|
|
|
|
|
0.5 |
|
|
|
|
|
0.8 |
относит. |
|
|
|
|
|
|
частота |
|
0.4 |
|
|
|
|
|
|
|
|
|
|
|
|
0.6 |
|
|
0.3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
накопл. |
|
|
|
|
|
|
|
0.4 |
|
0.2 |
|
|
|
|
|
частота |
|
|
|
|
|
|
|
||
0.1 |
|
|
|
|
|
0.2 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
0 |
|
40 |
45 |
50 |
55 |
60 |
65 |
70 |
|
Рис. 3 Диаграмма относительных и накопленных частот из примера 1
Задания для самостоятельной работы
1.Для данных из примера 1 построить выборочные функции распределения, воспользовавшись процедурой Гистограмма из пакета Анализа.
2.Построить выборочные функции распределения (относительные и накопленные частоты) для высоты деревьев в метрах: 18,1; 16,9; 17,8; 17,8; 17,1; 17,9; 17,2; 18,1; 17,9; 16,8; 14,4; 16,7; 16,9; 17,1; 17,9; 20,5; 18,1; 18,3; 17,2; 19,6.
14
3. Найдите распределение по абсолютным частотам для следующих результатов тестирования в баллах: 79, 85, 78, 85, 83, 81, 95, 88, 97, 85 (используйте границы интервалов 70, 80, 90).
4.Корреляционный анализ в Excel
Общеизвестно, что в природе все взаимосвязано и взаимообусловлено и, следовательно, изменение одного признака какого-либо явления неизбежно ведет к изменению других. Так, с увеличением возраста дерева увеличивается его высота, диаметр, длина листьев, корней, толщина коры, объем ствола и т.д. Это свойство природы широко используется в практике лесного хозяйства, когда по значению одного из признаков, обычно легко доступного для обмера, приходится рассчитывать значение другого признака, определение величины которого связано со значительными трудностями.
Особенностью массовых явлений в природе является их изменчивость, варьирование, поэтому связи, наблюдающиеся в природе, не так очевидны. Каждому значению одного признака здесь может соответствовать несколько значений другого признака. Обнаруживаются такие связи только при достаточно большом числе наблюдений. Обычно эти связи принято называть корреляционными.
От корреляционных надо отличать известные в математике функциональные связи, при которых каждому значению независимой - соответствует только одно, строго определенное значение второй переменной. В связи с этим пределами корреляционной связи является полное отсутствие между признаками, когда с изменением одного признака второй не изменяется, и наличие функциональной связи, когда зависимость между признаками может быть выражена математически.
Корреляцию называют простой, если она измеряется на основе двух признаков, или множественной, когда на результативный признак влияет несколько факторов. По форме корреляция может быть линейной и нелинейной, по направлению - прямой и обратной.
Учитывая вышесказанное, при проведении корреляционного анализа решаются следующие задачи:
1.Установление факта наличия или отсутствия связи между изучаемыми признаками.
2.Определение формы связи, и ее направленности.
3.Вычисление показателя тесноты связи и его оценка.
15
Рассмотрим пример расчѐта корреляции для данных измерений 9 деревьев:
Исходные данные
диаметр, |
высота, |
см |
м |
X |
Y |
12,2 |
16,00 |
16,6 |
18,00 |
20,8 |
20,15 |
24,4 |
22,14 |
28,1 |
23,48 |
32,2 |
23,65 |
36.524,62
40,1 |
26,00 |
44,3 |
27,00 |
Решение:
1. Введите исходные данные в таблицу Excel и запустите надстройку «Анализ данных». Выберите из списка метод «Корреляция» (Рис.4).
|
Рис. 4 Выбор метода анализа |
2. |
В появившемся диалоговом окне укажите диапазон исходных данных и |
выходной интервал для вывода результатов корреляционного анализа (рис.5)
16
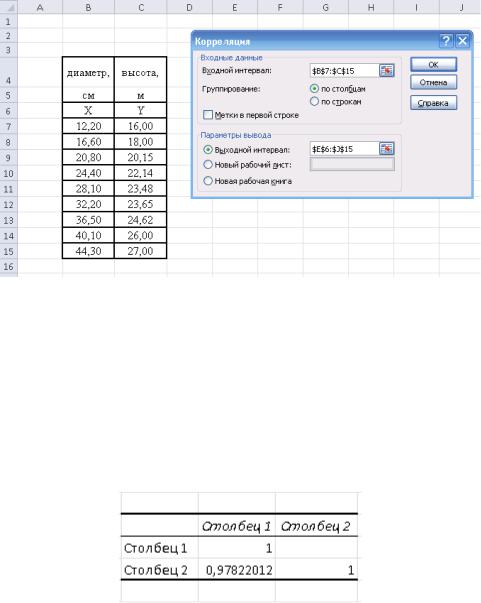
Рис. 5 Ввод входного и выходного интервала
3. После выполнения расчѐта на лист Excel будет выведена таблица с результатом корреляционного анализа (рис. 6).
Рис.6. Результат корреляционного анализа
На рисунке 6 видно, что коэффициент корреляции (r), характеризующий тесноту связи между диаметрами и высотами деревьев равен +0,987. Полученное значение коэффициента корреляции со знаком + свидетельствует о том, что выявленная корреляционная связь прямая: с увеличением значений одного признака (X) значения другого (Y) увеличиваются.
Для оценки степени тесноты корреляционных связей используется следующая шкала:
r >0,91 – связь очень высокая; r = 0,71-0,90 – связь высокая;
r = 0,51-0,70 – связь незначительная; r = 0,31-0,50 – связь умеренная;
r = 0,10-0,30 – связь слабая; r < 0,1 – связь отсутствует.
17
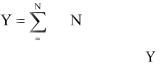
По указанию М.Л. Дворецкого (1971), для практических целей можно использовать связи при r > 0,5.
4. Регрессионный анализ в Excel
Перед началом моделирования и выбором вида модели (графический, табличный, аналитический) прежде всего, необходимо установить наличие корреляционной взаимосвязи между сравниваемыми признаками. С этой целью исходные данные отображаются на графике, по которому в результате визуального осмотра делают заключение о наличии или отсутствии корреляции.
Рассмотрим особенности графического выравнивания зависимости между двумя сопряженными признаками при малой и большой выборке
При малой выборке (N<:25... 30) на графике откладываются конкретные значения отдельных наблюдений (не объединенных в классы), то есть строится так называемый точечный график. Результирующая линия проводится между точками с таким расчетом, чтобы разделить их общее количество на две приблизительно равные части. При этом необходимо стремиться к такому положению, чтобы расстояние между линией и исходными точками было кратчайшим. Для облегчения техники выравнивания и увеличения его точности можно рекомендовать следующий прием. Соединить все выравниваемые точки и постараться провести плановую выравнивающую линию по возможности ближе к этим серединам.
В результате выравнивания в нашем примере (рис 7) где N = 16, над выравнивающей прямой расположено шесть точек, под ней семь точек и три находятся непосредственно на выравнивающей линии
Показан пример выравнивания при большой выборке (рис. 8), когда результаты наблюдений группируются в классы. В этом случае выравниваемые значения Y по классам X представляют собой средние значения, полученные как среднеарифметическое из нескольких наблюдений в классе, а именно:
~
Yi /
i 1
где Yi – данные относительных наблюдений; ~ - среднеарифметическое значение из всех наблюдений; N - число наблюдений. Рассмотрим два способа выравнивания: без учета веса наблюдений и при учете их веса.
В случае выравнивания без учета веса наблюдений необходимо руководствоваться принципом выравнивания при малой выборке. При этом условно допускается, что все выравниваемые значения Y по классам X имеют одинаковый «вес», приравненный к единице.
Показанная на рисунке выравнивающая кривая (сплошная линия) разделяет исходные точки на две приблизительно равные части: четыре точки над кривой и три точки под ней. Этот способ выравнивания следует применять в тех случаях, когда во всех классах имеется равное или близкое число наблюдений.
18

Рис. 7 Графическое выравнивание взаимосвязи при малой выборке
Рис. 8 Графическое выравнивание взаимосвязи при большой выборке:
______ без учета «веса» наблюдений;
--------- с учетом «веса» наблюдений.
Рассмотрим пример, когда в отдельных классах имеется явно различное число наблюдений, а именно:
№ классов |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
Число наблюдений |
3 |
15 |
17 |
21 |
2 |
9 |
1 |
Учитывая «вес» наблюдений, необходимо проводить выравнивающую кривую, принимая во внимание главным образом те точки, которые представлены сравнительно большим числом наблюдений. В нашем примере - классы 2, 3, 4, 6. В отличие от кривой, проведенной без учета веса наблюдений, в данном случае в начальных классах получилась более круто восходящая линия, что вызвано большим весом частот в классе 2, где n = 15, и в классе 3, где n = 17. Более высокое положение выравнивающей кривой в последующих классах 4 (n = 21) и 6 (n = 9) в сравнении с малым весом классов 5 (n = 2) и 7(n = 1).
19

Таким образом, в результате применения любого из методов получается выравнивающая линия, которая и является графической моделью корреляционной зависимости. Если же с полученной кривой снять значения Y по классам X, можно получить выравненные числовые значения зависимого признака, то есть, табличную модель.
Следовательно, полученные описанными способами результаты графического выравнивания могут быть использованы в двух направлениях:
1)для решения вопроса о наличии корреляционной связи, а следовательно, выяснения возможности дальнейшего аналитического (математического) моделирования;
2)как готовая графическая или табличная модель.
При выборе одного из указанных направлений необходимо учитывать, что путь графического выравнивания позволяет получить результаты сравнительно быстро, но с невысокой точностью, что объясняется невозможностью устранить субъективизм исследователя при проведении выравнивающих линий.
Аналитическое выравнивание гораздо более трудоемко, но исключает субъективность в оценках, обеспечивая получение более точных данных в виде конкретных уравнений связи двух признаков.
При выполнении регрессионного анализа в Excel нет необходимости группировать исходные данные в классы. В приведѐнном ниже примере показано, как получить регрессионное уравнение для исходных данных, приведѐнных в предыдущей главе.
Выберите в главном меню Excel пункт «Вставка/Диаграмма». Тип диаграммы укажите «Точечная» и нажмите кнопку «Далее». В поле «Диапазон» (рис. 9) введите координаты верхней левой и нижней правой ячейки исходных данных (А3:B12).
Рис.9 Вставка диаграммы в лист Excel.
После нажатия кнопки «Готово» на листе Excel появится точечный график с исходными данными (рис. 10).
20