

Предельные возможности эффективного кодирования дискретных сообщений.
Пусть
А
– источник последовательности знаков
с объемом алфавита K
и производительность H’(A).
Для
передачи по дискретному каналу нужно
преобразовать сообщения в последовательность
кодовых символов В
так, чтобы эту кодовую последовательность
можно было затем однозначно декодировать.
Для этого необходимо, чтобы скорость
передачи информации от источника к коду
I’(A,
B)
равнялась производительности источника
H’(A).
Необходимое условие для кодирование
H’(B)≥H’(A),
обозначив
через TK
длительность
кодового символа, а через TС
длительность элементарного сообщения
получим:
 или
или .
.

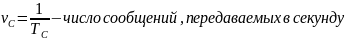
Теорема
кодирования для источника заключается
в том, что, передавая двоичные символы
со скоростью
 , можно закодировать сообщение так,
чтобы передавать их со скоростью
, можно закодировать сообщение так,
чтобы передавать их со скоростью
 ,
где
,
где
 – сколь угодно малая величина.
– сколь угодно малая величина.
Если источник передает сообщения независимо и равновероятно, то H(A) = log K, если при этом К – целая степень двух (К = 2n), то H(A) = n. С другой стороны, используя для передачи каждого сигнала последовательность из n двоичных символов, мы получим 2n = К различных последовательностей и можем каждому сигналу сопоставить одну из кодовых последовательностей.
Прямая теорема (теорема Шеннона для канала без помех – первая теорема Шеннона)
Теорема Шеннона устанавливает возможность передачи информации по каналу связи.
Смысл теоремы состоит в том, если пропускная способность канала связи достаточно большая, то хотя временные задержки возможны, но они когда-нибудь «рассосутся».
Пусть Vu - (информационная) производительность источника, т.е. количество информации, производимое источником в единицу времени; Ck - (информационная) пропускная способность канала, т.е. максимальное количество информации, которое способен передать канал без искажений за единицу времени. Первая теорема Шеннона утверждает, что безошибочная передача сообщений определяется соотношением Vu и Ck.
Первая теорема Шеннона: если пропускная способность канала без помех превышает производительность источника сообщений, т.е. удовлетворяется условие Ck>Vu, то существует способ кодирования и декодирования сообщений источника, обеспечивающий сколь угодно высокую надежность передачи сообщений. В противном случае, т.е. если Ck<Vu такого способа нет.
Строго первая теорема Шеннона о передаче информации, которая называется также основной теоремой о кодировании при отсутствии помех, формулируется следующим образом:
При отсутствии помех передачи всегда возможен такой вариант кодирования сообщения, при котором среднее число знаков кода, приходящихся на один знак кодируемого алфавита, будет сколь угодно близко к отношению средних информаций на знак первичного и вторичного алфавитов.
Используя понятие избыточности кода, можно дать более короткую формулировку теоремы:
При отсутствии помех передачи всегда возможен такой вариант кодирования сообщения, при котором избыточность кода будет сколь угодно близкой к нулю.
Эта теорема открывает принципиальную возможность оптимального кодирования. Однако необходимо сознавать, что из самой теоремы никоим образом не следует, как такое кодирование осуществить практически – для этого должны привлекаться какие-то дополнительные соображения.
В применении к побуквенному кодированию прямая теорема может быть сформулирована следующим образом:
Существует префиксный, то есть разделимый код, для которого средняя длина сообщений отличается от нормированной энтропии не более, чем на единицу:

где: U - некоторый источник сообщений, а также множество всех его сообщений u1,u2,...,uK ; w1,w2,...,wK - длины сообщений источника после кодирования; EUw(U) - средняя длина сообщений; H(U) - энтропия источника; D - количество букв в алфавите кодирования (например, 2 для двоичного алфавита, 33 - для кодирования заглавными русскими буквами и т. д.)