

Лекция 7
Тема. Построение классификаторов распознавания речевых сигналов (продолжение)
На лекции будет рассмотрено:
Классификатор на основе гауссовских смесей.
Распознавание речи с помощью нейросетей.
Гауссовы смешанные модели (gmm)
В отличие от СММ, ГСМ игнорирует временную информацию об акустической наблюдаемой последовательности и содержит состояния, отражающие различные акустические классы.
Для каждой фонемы создается модель, представленная на рис.7.1, которая определяет вероятность принадлежности фрейма этой фонеме.

Рис.7.1. Гауссова смешанная модель для одной фонемы
Для одного фрейма сигнала для одной фонемы (рис.7.1) ГСМ представлена в виде
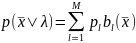 ,
,
где
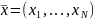 – вектор признаков фрейма,
– вектор признаков фрейма,
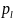 – веса,
– веса,
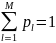 ,
,
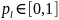 ,
,
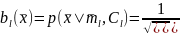 ,
,
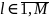 –многомерное распределение Гаусса,
–многомерное распределение Гаусса,
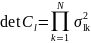
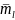 – вектор математических ожиданий
размерности
,
– вектор математических ожиданий
размерности
,
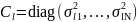 – диагональная ковариационная матрица
размерности
– диагональная ковариационная матрица
размерности
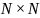 ,
,
– количество состояний фонемы, обычно
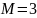 (начало, середина, конец),
– длина вектора признаков,
(начало, середина, конец),
– длина вектора признаков,
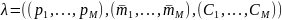 – вектор параметров ГСМ.
– вектор параметров ГСМ.
Для всего сигнала для одной фонемы учитываются результаты распознавания всех фреймов. Функция максимального подобия (ML) представлена в виде
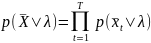 ,
,
где
– количество фреймов сигнала,
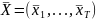 .
.
Алгоритм обучения параметров EM (максимизации ожидания)
1.
Инициализация весов
,
параметров
 (например, случайно)
(например, случайно)
2. Получить очередной вектор сигнала
3. Вычислить матрицу условных вероятностей
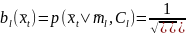 ,
,
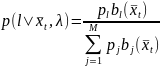 ,
,
,
,
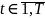
4. Вычислить новые весовые коэффициенты
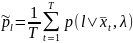 ,
,
5. Вычислить новые средние
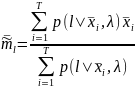 ,
,
6. Вычислить новую диагональную ковариационную матрицу
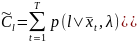 ,
,
Принятие решения о номере фонемы
Если у фонем разная вероятность, то номер фонемы определяется в виде
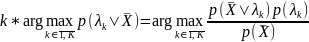 ,
,
где
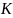 – количество фонем.
– количество фонем.
Если у фонем одинаковая вероятность, то номер фонемы определяется в виде
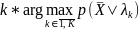 ,
,
или
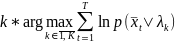 .
.
Распознавание речи с помощью нейронных сетей
Введение в нейронные сети
Имея значения существенных параметров речевого сигнала, мы можем приступить к распознаванию звуков. Под существенными параметрами я здесь полагаю такие характеристики звука, которые образуют множество, по которому можно с высокой вероятностью отличить один вид (класс) звука от другого или прийти к заключению о том, что два звука принадлежат одному виду (классу).
Человеческий слуховой аппарат при распознавании звука ориентируется на частотный домен звукового сигнала, при этом, как уже упоминалось ранее, для него практически не имеет значения фаза сигнала. Существенным является лишь абсолютные значения амплитуд частот сигналов, точнее некие соотношения и сочетания абсолютных значений частот. Для программной реализации мы выберем ранее упоминавшееся распределение энергии сигналов по группам смежных частот (суммарная энергия сигнала в диапазоне частот мы вычисляем как сумму квадратов амплитуд частот, входящих в диапазон).
Для того, чтобы распознать звук, необходимо иметь образцы значений всех существенных параметров каждого из звуков речи и оценить, относится ли к какому-нибудь из них наш звук, сравнивая значения его параметров со значениями параметров образцов.
Наиболее часто употребляются два подхода к классификации и распознаванию.
В первом некая функция служит мерой близости параметров. Такая функция называется метрикой.
Второй подход не использует вспомогательных функций, но моделирует процесс распознавания в биологических системах. Такой подход использует технологии так называемых нейронных сетей. Для программной реализации мы выберем именно этот, представляющийся более перспективным в настоящее время, подход.
Итак, проведем краткий экскурс в предмет компьютерных нейронных сетей. Нейронные сети – это аппаратные или программные средства, моделирующие работу человеческого мозга. Как и всякая модель, они являются приближением. Но даже несмотря на то, что в подобных средствах имитируются лишь отдельные стороны биологического прототипа, они уже сейчас позволяют добиться определенных успехов во многих областях, в частности связанных с классификацией и распознаванием образов.
Как известно, нервная система человека состоит из огромного числа элементов, называемых нейронами, соединяемыми между собой нитеобразными отростками-дендритами. Возбуждение или торможение (возбуждение со знаком минус) передается от нейрона к нейрону по дендритам, где те принимают сигналы в точках соединения, называемых синапсами. Принятые синапсом входные сигналы передаются к телу нейрона, где суммируются. Если уровень возбуждения превышает некоторую пороговую величину, возбуждение передается из тела нейрона в выходную точку, называемую аксоном, откуда по дендритам поступает в другие нейроны.
Именно указанные выше характеристики и стали существенными при создании искусственных нейронных сетей.
Основу нейронной сети составляют как правило однотипные элементы, имитирующие работу биологического нейрона, и называемые обычно так же. Каждый из нейронов в каждый момент времени находится, как и биологический нейрон, в некотором текущем состоянии. Он имеет группу однонаправленных входных связей-синапсов, идущих от входа в сеть или от других нейронов. Кроме того он имеет одну однонаправленную выходную связь-аксон.
Схематически нейрон можно представить так:

Синаптические связи характеризуются весами wi. Текущее состояние S нейрона равно взвешенной сумме входов:
|
n |
|
S = |
∑ |
Xiwi |
|
i=1 |
|
В векторном виде это можно записать как S=XW, то есть вектор S есть произведение вектора входных значений X на матрицу весов W, где строки соответствуют слоям, а столбцы – нейронам внутри каждого слоя.
Функция S далее преобразуется активационной функцией F и дает выходной сигнал Y нейрона.
Y=F(S) Активационная функция должна обладать свойством резко возрастать на коротком интервале аргумента в окрестностях порогового значения T, принимать приблизительно одно значение до этого интервала и приблизительно одно (большее) значение – после этого интервала. Этим требованиям соответствует, например функция Y, равная 1 при S>T, и 0 при S<=T. Эта функция называется также функцией единичного скачка.

Но, к сожалению, опыт показал, что многие алгоритмы нейронных сетей плохо работают или не работают с линейными функциями. К тому же эта функция содержит разрыв в точке T.
Самой распространенной в нейронных сетях активационной функцией является сигмоид или логистическая функция, вычисляемая как
F(S)=1/(1+e-s)

На самом деле, в общем виде формула логистической функции выглядит так:
F(S)=1/(1+e-αs),
где α –некоторая константа. При уменьшении α логистическая функции становится более пологой, при α=0 принимая вид горизонтальной линии Y=0.5. При увеличении α сигмоид приближается по внешнему виду к функции единичного скачка.
Еще одним весьма полезным свойством логистической функции является ее дифференцируемость при любых S и простота вычисления ее производной:
F/(S)= αF(S)(1-F(S))
Простейшей моделью нейронной сети является однослойный персептрон. Однослойность означает, что входной сигнал входов (x1,x2,…xn) подается на одну группу нейронов, именуемых слоем нейронной сети, а выходные сигналы этих нейронов поступают сразу на выход сети. Для двуслойной сети выходные сигналы подавались бы не на выход сети, а на вторую группу-слой нейронов, а оттуда на вход. Понятно, что трехслойный нейрон имеет уже три группы-слоя, N-слойный – N групп-слоев и т.д.

Можно считать, что на вход первого слоя подаются сигналы со всех входов сети, просто веса некоторых синапсов равны нулю. Аналогично можно считать, что на входы всех слоев кроме первого подаются сигналы с выходов всех нейронов предыдущего слоя.
Но вернемся к однослойному персептрону. Он обнаружил ряд положительных свойств, которые и заставили многих ученых обратить свой взор на исследование нейронных сетей. Главными из обнаруженных свойств персептрона была способность к обучению и распознаванию. То есть оказалось возможным в ряде случаев установить то, как можно настроить веса синапсов персептрона, чтобы при различных комбинациях значений входов получать заранее установленные, «правильные» значения выходов. То есть однослойный персептрон оказался способным воспроизводить некоторые математические функции.
Однако эйфория по поводу этих открытий оказалась недолгой: были обнаружены существенные ограничения в способностях однослойного персептрона к обучению и распознаванию.
Во-первых, было доказана его неспособность воспроизводить некоторые простые функции, например ИСКЛЮЧАЮЩЕЕ ИЛИ.
Если Tj – пороговое значение j-го выхода, то однослойный персептрон описывается уравнениями:
|
n |
|
Tj = |
∑ |
xiw1,j,i |
|
i=1 |
|
где n – число нейронов в слое. В n-мерном пространстве эти функции оказываются прямыми. Точки n-мерного пространства входов для значений дающих разные значения (0 или 1) выхода (то есть F>Tj или F<=Tj) должны лежать по разные стороны от таких прямых. Но для многих функций (например ИСКЛЮЧАЮЩЕЕ ИЛИ) это невыполнимо.
Все было бы очень грустно, если бы не существовало многослойных нейронных сетей. Уже при количестве слоев равном двум сеть описывается уравнениями:
|
n |
|
n |
|
Tj = |
∑ |
( |
∑ |
xiw1,j,i)w2,j,i |
|
i=1 |
|
i=1 |
|
Теперь включая достаточное число нейронов во входной слой можно получить выпуклый многоугольник любой формы. Трехслойная же сеть есть еще более общий случай. В ней ограничения на выпуклость отсутствуют: нейрон третьего слоя принимает на вход выпуклые многоугольники, комбинация которых может быть уже невыпуклой.
Таким образом, способности к распознаванию у многослойных сетей значительно превосходят те же способности у однослойного персептрона. Зато несколько усложняется процесс обучения этой сети. Под обучением сети мы понимаем процесс настройки весов синапсов, так чтобы выход сети был ожидаемым.
Если в сети только один слой, процесс ее обучения довольно очевиден. Рассмотрим, например, алгоритм Кохонена.
1. Весовые коэффициенты wij, определяющие i-й вход j-го нейрона, устанавливаются в некоторые малые значения. Устанавливаются входы Xi .
2. Вычисляются значения вспомогательного вектора Rj для каждого входа по формуле:
|
n |
|
Rj = |
∑ |
(Xi-w1,j,i)2 |
|
i=1 |
|
где n – число нейронов в сети.
3. Определяется m, такое что
Rm= |
min |
Rj |
|
j |
|
4. Пересчитать все wij для нейрона с номером m по формуле wim= wim + M(Xi-wij), где 0.5<=M<=1.
5. Если решение не было достигнуто, переходим к шагу 2.
Существуют и другие алгоритмы для однослойной сети.
Алгоритмы обратного распространения
Сложнее обстоит дело с многослойными сетями, так как изначально неизвестны желаемые выходы слоев сети (за исключением последнего) и их невозможно обучить, руководствуясь только величиной ошибок на выходе сети, как это было с однослойной сетью.
Наиболее приемлемым вариантом решения проблемы стала идея распространения сигнала ошибки от выхода сети к ее входу, слой за слоем. Алгоритмы, реализующие обучение сети по этой схеме, получили название алгоритмов обратного распространения. Наиболее распространенный вариант этого алгоритма мы и рассмотрим.
Алгоритм требует дифференцируемости активационной (или как ее по-другому называют, сжимающей) функции на всей оси абсцисс. По этой причине, функция единичного скачка не может использоваться и в качестве сжимающей функции обычно применяют упомянутый выше сигмоид (логистическую функцию), хотя существуют и другие варианты.
Рассматриваем «классический вариант» многослойной сети, где синаптические связи могут определяться любыми действительными числами, а выход нейрона – действительными числами из интервала от 0 до 1. В качестве активационной функции используем сигмоид. Число слоев произвольное.
1. Определяем M матриц весовых коэффициентов W размером NxN, где M – число слоев, N – число нейронов в одном слое. Wi, j, k будет обозначать вес j-го входа k-го нейрона в i-м слое. Инициализируем матрицы некоторыми малыми случайными ( не одинаковыми ) значениями.
2. Подаем на входы сети определенные значения X, для которых известны правильные значения выходов сети Y*.
3. Вычисляем значения выходов сети для текущего состояния матриц W. То есть для входного вектора X вычисляется выходной вектор Y. Для этого необходимо последовательно вычислить выход для каждого слоя сети с первого по последний. Для i-го слоя в векторном виде это можно записать так:
Oi=F(ХWi), если i – не первый слой.
Oi=F(Oi-1Wi), если i – не первый слой.
где Oi – вектор выхода i-го слоя, F – активационная функция, X – вектор входов, Oi-1 – вектор выхода (i-1)-го слоя, Wi – матрица весовых коэффициентов i-го слоя.
4. Вычисляем вектор ΔY=Y-Y*
5. Если ΔY меньше заданной погрешности, переходим к шагу 9.
6. Для слоя с номером M (т.е. в последнем слое) производим следующие операции:
6.1. Для всех нейронов в слое с номера 1 по N производим следующие операции:
6.1.1. Для всех весов нейрона с номера 1 по N производим следующие операции:
6.1.1.1. Рассчитываем вектор δM=X(1-X)ΔY
6.1.1.2. Рассчитываем величину ΔWM,j,k=ηδM,kOi-1,j,
где η – коэффициент скорости обучения (от 0.01 до 1.0)
6.1.1.3. Корректируем величину весового коэффициента, добавляя к WM, j, k величину ΔWM,j,k
7. Для слоев с номером M-1 по первый последовательно производим следующие операции:
7.1. Для всех нейронов в слое с номера 1 по N производим следующие операции:
7.1.1. Для всех весов нейрона с номера 1 по N производим следующие операции:
7.1.1.1. Рассчитываем вектор
|
N |
|
δi=Oi+1(1-Oi+1)[ |
∑ |
δi+1,jWi+1, j, k] |
|
k=1 |
|
7.1.1.2. Рассчитываем величину ΔWi,j,k= ηδi,kOi-1,j, где Δ – коэффициент скорости обучения (от 0.01 до 1.0)
7.1.1.3. Корректируем величину весового коэффициента, добавляя к WM, j, k величину ΔWM,j,k
8. Переход к шагу 3.
9. Конец (обучение окончено).
Описанный алгоритм применяется достаточное количество раз, чтобы все варианты выходных значений могли правильно выходить при задании произвольных значений входа с заданной вероятностью ошибки.
Это алгоритм может быть усовершенствован. Например, выяснилось, что обычный диапазон для входов и выходов от 0 до 1 не является оптимальным. Из за того, что ΔWi,j,k прямо пропорционален выходному уровню нейрона, нулевой выходной уровень приводит к нулевому значению ΔWi,j,k, то есть величина веса не изменяется и обучение не происходит. Выход состоит в приведении входов к значениям от -0.5 до 0.5. Активационная функция должна приобрести вид:
F(S) = (-0.5)+1/(1+e-s).
После того, как сеть будет надлежащим образом обучена, она может быть использована для распознавания, в том числе, для распознавания звуков. Подаем на вход сети параметры звукового сигнала и получаем на выходе последовательность значений от -0.5 до 0.5 (или – после обратной корректировки – от 0 до 1), по которым и определяем звук (каждому звуку сопоставляется уникальная комбинация выходов до начала процесса обучения, и, собственно по ней мы на этапе обучения и определяем, правильно ли определен звук).