

извлекаются из начала. Таким образом, первым из очереди будет извлечен тот элемент, который будет добавлен раньше других. Говорят, что очередь реализует дисциплину обслуживания FIFO (First In – First Out, первым пришел – первым ушел). Очередь можно рассматривать как однонаправленный список, в котором можно удалять только из начала, а добавлять только в конец. Основные операции над очередью – такие же, что и над стеком: включение, исключение, определение размера, очистка, обход, чтение.
Деком (англ. deque – аббревиатура от double-ended queue, двухсторонняя очередь) называется структура данных, в которую можно удалять и добавлять элементы как в начало, так и в конец. Дек хранится в памяти так же, как и очередь. Таким образом, дек может быть и стеком, и очередью, и комбинацией этих структур. Наиболее часто дек представляется структурой с ограничением на вход или выход: дек с ограниченным входом (только одна позиция доступна для добавления элемента) и дек с ограниченным выходом (только одна позиция доступна для взятия элемента из дека). Стандартные операции над деком: включение элемента справа; включение элемента слева; исключение элемента справа; исключение элемента слева; определение размера; очистка.
На практике также используются модификации приведенных структур, например циклическая очередь, замкнутый или кольцевой список и т.п. В таких структурах, как правло последний элемент замыкается указателем на первый (и наоборот, – первый ссылается на последний, при двухсторонней связи), что позволяет рассматривать структуру как замкнутое кольцо.
Деревья
Дерево – одна из наиболее распространённых структур данных, используемых в программировании. Формально дерево определяется рекурсивно следующим образом: это конечное множество Т, состоящее из одного или более узлов таких, что:
1.Имеется один узел, называемый корнем дерева.
2.Остальные узлы, исключая корень, содержатся в m≥0 попарно непересекающихся множествах Т1, Т2,….Тm, каждое из которых в свою
162
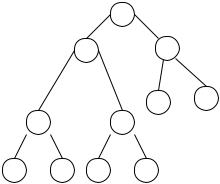
очередь является деревом. При этом деревья Т1, Т2,….Тm называются поддеревьями (потомками) данного корня.
Поддеревья некоторой вершины еще иногда называют кустами, а конечные вершины дерева из которых больше не выходит ни одной связи (т.е. для такого узла m=0), называют листьями.
Наиболее распространены в программировании бинарные (двоичные) деревья, в которых каждый узел может иметь не более двух потомков. Рекурсивное определение бинарного дерева задает его как корень и два бинарных поддерева: левое и правое, – причем любое из них может быть пустым. Бинарные деревья используются как структура данных в том случае, когда в каждой точке процесса должно быть принято одно из двух возможных решений. Например, они применяются для синтаксического анализа, поиска, сортировки, управления базами данных и в других приложениях.
Пример 37. Приведем пример бинарного дерева (рис.44), которое может использоваться для вычисления алгебраического выражения (A*B+C*D)/(B*C), если двигаться от листьев дерева к корню.
/
+*
B C
**
A B C D
Рис.44. Пример бинарного дерева
Бинарные деревья наиболее часто используются в программировании. Это основывается на том факте, что любое дерево может быть приведено к бинарному. Основное правило такого преобразования: левая ветвь каждого узла соединяет его с первым узлом следующего уровня, а правая – с другими узлами следующего уровня (братьями). Рис.45 демонстрирует первый шаг преобразования дерева A к его бинарному представлению. На втором шаге тоже самое делается с поддеревом B и т.д.
163

|
|
|
A |
|
|
A |
Þ |
|
|
|
|
B1 |
B |
|
|
|
|
||
B1 |
B2 . . . |
BN |
|
|
|
|
|
B2 |
B3 . . . BN |
Рис.45. Шаг преобразования дерева к бинарному
Бинарное дерево на языке Си может быть описано следующими структурами данных:
struct tree |
|
|
{ |
//информационное поле |
|
int info; |
||
tree ltree,rtree; |
//указатели на левое и правое поддерево |
|
} |
|
|
Кбинарным деревьям применяют следующие типовые операции:
1.Создание нового бинарного дерева, состоящего из одного узла с информационным полем .
2.Создание нового левого или правого «сына» (узла) для текущего узла.
3.Чтение информационного содержимого узла.
4.Определение указателя на левое или правое поддерево.
5.Удаление куста или листа дерева.
6.Удаление левого или правого поддерева для узла.
7.Обход дерева.
8.Сравнение деревьев.
9.Соединение деревьев.
Пример 40. Рассмотрим реализацию основных процедур и функции для работы с деревьями.
tree MakeTree(tree node, int x)
{
if(node.value == NULL) { tree* p = new tree;
164
p->value = x; } node = *p;
else
{ if((node).value > x) MakeTree(*node.pleft, x);
} else MakeTree(*node.pright, x);
return node;
}
void SetLeft (tree *p,int x) // создание левого сына для узла с указателем p
{
}
*p->ltree = NewNode(x);
void SetRight(tree *p,int x) // создание правого сына для узла с указателем p
{
}
*p->rtree = NewNode(x);
int GetInfo (tree *p) // чтение значения информационного поля узла p
{
}
if (p != NULL) return p->info; else return(0);
tree GetLeftTree (tree *p) // выдать значение указателя на левое поддерево // узла p
{
}
if (p != NULL) return *p->ltree; //else return(NULL);
tree GetRightTree (tree *p) //выдать значение указателя на правое поддерево // узла p
{
if (p != NULL) return *p->ltree; // else return (tree)NULL;
}
void DelLeaf (tree *p) // Удалить в дереве «лист»
{
}
if (p != NULL) free(p);
Рассмотрим более подробно задачу обхода дерева. Обход дерева – это последовательный обход всех узлов дерева. Фактически во время обхода нужно составить список всех узлов дерева. Поскольку дерево по определению является рекурсивной структурой данных, то и обход дерева как правило осуществляется рекурсивно. Существует три способа рекурсивного обхода бинарного дерева: обход с префиксным порядком; обход с инфиксным порядком; обход с суффиксным (или постфиксным) порядком.
165
Префиксный порядок обхода дерева определяется в виде списка узлов следующим образом:
Если дерево не пусто, то префиксный порядок это:
1.Корень дерева.
2.Узлы левого поддерева в префиксном порядке.
3.Узлы правого поддерева в префиксном порядке.
Например, пусть дано дерево, указанное вна рис. примере 48, тогда префиксный обход дерева это следующая последовательность узлов: / +*AB*CD*BC. Иногда префиксный порядок называют обходом дерева сверху вниз.
Инфиксный порядок обхода дерева определяется в виде списка узлов следующим образом:
Если дерево не пусто, то инфиксный порядок это:
1.Узлы левого поддерева в инфиксном порядке.
2.Корень дерева.
3.Узлы правого поддерева в инфиксном порядке. Для нашего примера это будет: A*B+C*D/B*C
Суффиксный порядок обхода дерева определяется в виде списка узлов
следующим образом:
Если дерево не пусто, то суффиксный порядок это:
1.Узлы левого поддерева в суффиксном порядке.
2.Узлы правого поддерева в суффиксном порядке.
3.Корень дерева.
Для нашего примера это будет: AB*CD*+BC*/. Суффиксный порядок обхода иногда называют обходом дерева снизу вверх.
Заметим, что инфиксный порядок обхода бинарного дерева в нашем примере совпал с самим алгебраическим выражением, только без скобок, суффиксный порядок – совпал с ОПЗ выражения, а результат префиксного обхода является обратным инфиксному, т.е. сначала указывается операция, затем операнды, – именно так записываются функции и процедуры на языке Паскаль.
166
С обходом дерева как правило совмещаются некоторые действия над проходимой вершиной. Например, в случае суффиксного обхода, можно совместить обход с операцией удаления куста дерева.
void PrefixObhod (tree *p)
{
if (p !=NULL) // Если дерево не пусто, то префиксный порядок это:
{ printf ("%d", p->info); //обработка узла, например напечатем его
инф.часть
PrefixObhod (p->ltree); // Узлы левого поддерева в префиксном порядке } PrefixObhod (p->rtree); // Узлы правого поддерева в префиксном порядке
}
void InfixObhod (tree *p)
{
if (p != NULL) // Если дерево не пусто, то инфиксный порядок это:
{ InfixObhod (p->ltree); // Узлы левого поддерева в инфиксном порядке printf ("%d", p->info); //обработка узла, например напечатем его
инф.часть
} InfixObhod (p->rtree); // Узлы правого поддерева в инфиксном порядке
}
void DelSubTree (tree *p) //процедура удаление куста p с использованием
суффиксного обхода
{
if (p != NULL) // Если дерево не пусто, то суффиксный порядок это:
{DelSubTree (p->ltree); // Узлы левого поддерева в суффиксном порядке DelSubTree (p->rtree); // Узлы правого поддерева в суффиксном порядке free(p); //обработка узла, например удалим узел
}
}
void DelLeftTree (tree *p) //удаление левого поддерева для узла p
{
if (p != NULL)
{ DelSubTree (p->ltree); } p->ltree = NULL;
}
void DelRightTree (tree *p) //удаление правого поддерева для узла p
{
if (p != NULL)
{ DelSubTree (p->rtree); } p->ltree = NULL;
}
Сравнение деревьев производится путём сравнения информационной части (информационных полей) соответствующих деревьев, начиная с корня. Функция должна сравнивать информационные части узлов дерева, а далее рекурсивно
167