

ГРАФ-СХЕМНОЕ ПОТОКОВОЕ ПАРАЛЛЕЛЬНОЕ ПРОГРАММИРОВАНИЕ И ЕГО РЕАЛИЗАЦИЯ НА КЛАСТЕРНЫХ СИСТЕМАХ
2004 г. Д.В. Котляров, В.П. Кутепов, М.А. Осипов
Московский энергетический институт (технический университет)
В статье описана реализация на кластерах система граф – схемного потокового параллельного программирования, которая включает язык модульного визуального параллельного программирования, инструментальные средства разработки программ и средства управления параллельным их выполнением на кластере.
Введение
Первая версия языка граф-схем, которая была создана в начале 70-х годов на волне активных исследований по параллелизму и параллельным системам, задумывалась как “мягкое” развитие структурных (блочно-схемных) форм описания последовательных программ с предполагаемой реализацией на многомашинных и (или) многопроцессорных системах [1-3].
Следующие принципиального характера требования ставились при формулировке
языка:
−модульный принцип построения параллельной программы, причем с возможностью программирования модулей как многовходовых-многовыходовых процедур на последовательных языках программирования;
−наглядное граф-схемное описание структуры параллельной программы в виде двух компонентов: граф-схемы и интерпретации, однозначно сопоставляющей каждому модулю (блоку граф-схемы) подпрограмму (или процедуру) на соответствующем языке программирования;
−интерпретация связей между модулями как связей по данным (а не по управлению), правда, с таким ограничением, чтобы у корректных, т.е. однозначных граф-схем [4] на каждом входе модуля не накапливалось более одного данного (естественное наследование принципа выполнения любой команды или оператора последовательной программы);
−экспликация параллелизма как информационной независимости различных модулей
граф-схемы.
Уже первая попытка реализации такого граф-схемного модульного языка параллельного программирования [5] на многомашинных комплексах М6000/М7000 по принципу децентрализованного управления оказалась вполне успешной, особенно в с сравнении с популярными в то время системами параллельных вычислений Сумма и Минимакс [6], позволявшими описывать параллелизм более примитивными и ограниченными средствами.
Затем эта же версия языка граф-схем была реализована в централизованном варианте на многомашинных комплексах СМ1/СМ2, причем в этой реализации существенное развитие получила система машинной поддержки процесса конструирования граф-схемных параллельных программ, их модификации и отладки.
В[3] в язык граф-схем было введено простое, но весьма важное по практическим соображениям расширение, касающееся векторного динамического параллелизма и возможности его компактного параметрического схемного отражения.
Вработе [7] был сделан радикальный шаг в развитии граф-схемного языка, состоящий в интерпретации информационных связей между модулями как буферов с FIFO (первое поступившее данное считывается первым) дисциплиной их обслуживания. Как следствие, пространственная (информационно-независимая) и основанная на временном
Работа выполнена при поддержке РФФИ, проект 03-01-00588
совмещении выполнения различных частей программы по принципу конвейера, формы параллелизма могли быть одинаково представлены в граф-схемной модели. Утвердившийся затем термин “потоковые вычисления” [8] объединяет эти различные формы параллелизма, а классификационное разделение принципов функционирования параллельных систем по типу SIMD (один поток команд и много
потоков данных), MIMD (много потоков команд и много потоков данных) и др. отражает особенности реализации потоковых схем.
Эта версия граф-схемного языка интересна еще и тем, что она базируется на строгом понятии асинхронной вычислительной сети и описании процесса функционирования сети как композиции процессов, индуцируемых конечно-автономной интерпретацией процессов выполнения модулей граф-схемы. Естественно, что формализм сетей Петри оказался наиболее подходящей моделью для формального описания процесса выполнения граф-схем
[7].
Реализация этой версии граф-схемного языка, выполненная на многопроцессорных и многомашинных комплексах ЕС ЭВМ [9], – первая профессионально выполненная разработка системы параллельного программирования для подобной универсальной организации вычислительных систем на базе серийных ЭВМ. Во-первых, в этой реализации максимально использовались средства операционной системы ЕС ЭВМ для выполнения программ модулей граф-схемы, для организации межмашинных обменов и др. Управление параллельным выполнением граф-схемных программ в этой реализации построено по строго децентрализованному принципу, причем предварительно граф-схема разрезается на n подсхем, где n – количество машин в системе, таким образом, чтобы после “назначения” подсхем на n ЭВМ достигался определенный баланс их загрузки и загрузки каналов обмена между машинами. Подобное статическое планирование параллельных вычислений, не допускающее динамического перераспределения работ между ЭВМ в процессе их функционирования, является ограничительным, однако оказалось достаточно простым в реализации.
В [10] средства управления параллельным выполнением граф-схем были расширены введением специальных программ реакции на отказы и сбои в системе и управления реконфигурированием системы, это существенно повысило ее значение, особенно в сфере военных приложений. Вместо традиционно применяемого механизма резервирования параллельная работа обеспечивала большее суммарное быстродействие и одновременно способность продолжения работы, если в ней оставалась работоспособной хотя бы одна ЭВМ.
Данная статья посвящена описанию реализуемого научной группой под руководством проф. Кутепова В.П. на кафедре прикладной математики МЭИ проекта создания системы граф-схемного потокового параллельного программирования для кластерных систем.
Широкие возможности, которые сегодня предоставляет вычислительная техника в части организации вычислительных систем на базе стандартных аппаратных средств – персональных компьютеров и сетевых коммуникаций актуализировали работы в области параллельных и распределенных вычислений [11]. Активно ведутся работы по созданию программных средств для эффективной организации параллельных и распределенных вычислений на кластерах. Кроме известных расширений последовательных языков программирования (High performance C и C++, mpC, DVM, параллельный ФОРТРАН, CHARM++, Mosix и др.), сегодня широко используются стандартизированные API-средства
(Application Parallel Interface) и библиотеки: MPI, PVM и др. (см. сайт parallel.ru и др.).
Внимательный анализ этого уже достаточно обширного арсенала программных средств для кластеров показывает [12], что они обычно базируются на расширениях языков последовательного программирования (Фортрана, C, C++ и др.), а в реализации для организации параллельного выполнения программ используются специальные библиотеки функций, позволяющие описывать межпроцессное (и межкомпьютерное) взаимодействие. При этом за программистом остается основная работа не только в написании корректной и
2
эффективной программы, но также и ее реализация (распределение процессов на компьютеры кластера). Из программных систем для кластеров, возможно, только в проекте Mosix задача управления параллельными процессами рассматривается как центральная, от решения которой прямо зависит эффективность работы кластера [13] (см. также сайт mosix.tcs.huji.ac.il).
В нашем проекте три главных составляющих, определяющих эффективность параллельных вычислений на кластере: язык программирования, инструментальная среда разработки параллельных программ и программные средства управления параллельным выполнением программ рассматриваются и реализуются комплексно.
Раздел 1 статьи посвящен описанию разработанного языка граф-схемного потокового параллельного программирования, раздел 2 – описанию инструментальной среды программирования на этом языке, в разделе 3 рассмотрена реализация управления параллельным управлением программ на кластерных системах, в разделе 4 описана программная реализация системы граф-схемного потокового программирования для кластерных систем.
1. Язык граф-схемного потокового параллельного программирования (ЯГСПП)
ЯГСПП ориентирован на крупноблочное (модульное) потоковое программирование задач, он также может эффективно применяться для программного моделирования распределенных систем, систем массового обслуживания и др., информационные связи между компонентами которых структурированы и управляются потоками данных, передаваемых по этим связям.
Язык позволяет эффективно и единообразно представлять в программах три вида параллелизма:
−параллелизм информационно-независимых фрагментов;
−потоковый параллелизм, обязанный своим происхождением конвейерному принципу обработки данных;
−параллелизм множества данных, реализуемый в ЯГСПП через механизм тегирования, когда одна и та же программа или ее фрагмент применяются к
различным данным; Другими, важными с позиции программирования, особенностями ЯГСПП являются:
−возможность визуального графического и текстового представлений программ;
−возможность простого структурирования программы и отражения декомпозиционной иерархии при ее построении путем использования отношения «схема-подсхема»;
−использование традиционных последовательных языков при программировании модулей.
1.1 Графическая версия ЯГСПП
Граф-схемная параллельная программа (ГСПП) представляется в виде пары <ГС,I>, где ГС – граф-схема, I – интерпретация.
Граф-схема или просто схема позволяет визуально представлять строящуюся из модулей программу решения задачи; интерпретация сопоставляет каждому модулю множество подпрограмм, а связям между модулями – типы данных, передаваемых между подпрограммами модулей в процессе выполнения ГСПП.
Основным «строительным» блоком ГСПП является модуль, графическое представление которого приведено на рис. 1. Все входы и выходы модулей строго типизированы и разделены на группы (отдавая дань предыстории ЯГСПП, они называются конъюнктивными группами входов (КГВх) и конъюнктивными группами выходов (КГВых)
3
соответственно) и отражают структуру потоков данных, передаваемых между подпрограммами модулей. Каждой КГВх модуля однозначно сопоставляется подпрограмма на одном из последовательных языков программирования (C/C++, Pascal, Java и др.), причем перечисленные формальные параметры и их типы в задании подпрограммы должны совпадать с порядком изображения (слева направо) входов КГВх и их типами соответственно. Кроме того, в качестве формального параметра в списке параметров подпрограмме добавляется целочисленный параметр tag, который указывается первым. На ГС этот параметр не изображается, поскольку он выполняет роль идентификации данных, передаваемых между модулями ГСПП в процессе его выполнения.
По соглашению, КГВх модуля изображаются на верхней линии его блочного представления, а КГВых – на нижней и отделяются друг от друга, как изображено на рис. 1. Также предполагается, что КГВх и КГВых и их входные и выходные точки однозначно идентифицируются своими номерами, присваемыми им в порядке изображения (слева направо).
int float []float [] |
int |
float [] |
int float [] |
КГ Входов 1 |
КГ Входов 2 |
КГ Входов 3 |
|
Назначение: |
Назначение: |
Назначение: Построение |
|
Перемножение матриц |
Вычисление определителя матрицы |
обратной матрицы |
|
|
Модуль: Matrix |
|
|
|
Назначение: Матричные операции |
|
|
|
КГ Выходов 1 |
|
|
|
int |
float [] |
|
Рис.1. Графическое изображение модуля
Графическое изображение модуля, которое обязательно сопровождается приписыванием ему имени, также может нести дополнительную информацию, носящую характер комментариев, раскрывающих назначение модуля, назначение подпрограмм, сопоставляемых его КГВх и др. Так, модуль, представленный на рис.1, предназначен для выполнения операций над вещественными квадратными матрицами, размерность которых задается целочисленным параметром; результат вычисления передается на КГВых 1.
ГС представляет блочную структуру, построенную из модулей путем соединения выходов КГВых модуля с входами КГВх другого или этого же модуля, причем типы соединяемых входов и выходов должны совпадать. В интерпретации такое соединение называется информационной связью (ИС), по которой данные соответствующего типа передаются от одного модуля к другому.
Возможны связи «один ко многим» и «многие к одному» (см. рис. 2). Первое означает, что данные передаются одновременно с выхода модуля на все входы, с которыми он связан, а второе – что данные на вход могут поступать с любого из выходов, с которыми он связан.
(A) |
(Б) |
Module_2 |
|
Module_1 |
|
|
Module_1 |
|
|
Module_3 |
Module_2 |
Module_3 |
Рис.2. Примеры связей «один ко многим» (А) и «многие к одному» (Б)
Для того чтобы связи не перегружали изображаемые ГС, допускается группировать входы КГВх и выходы КГВых, соединяя их общей горизонтальной линией, а связи между такими объединениями соединять одной «обобщенной» ИС при условии, что все связи между входами и выходами таких групп однозначно могут быть восстановлены (см. рис. 3).
4

Различаются межмодульные и свободные (установочные) связи. Последние позволяют перед выполнением ГСПП задать на соответствующих входах модулей начальные значения. На рис. 3 у модуля изображены две установочные связи.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
float |
int char bool |
char |
|
|
int |
|||
int int bool |
||||||||
Module_1
Рис. 3. Пример свободной ИС
Допускается, что у КГВх модуля может не быть входов. В этом случае подпрограмма, сопоставленная этой КГВх, является подпрограммой без параметров и она начинает выполняться вместе с началом выполнения ГСПП и работает как генератор данных, считываемых с некоторого носителя или вырабатываемых подпрограммой самостоятельно
(см. п. 1.3).
Забегая вперед, заметим, что в операционной семантике ЯГСПП ИС при выполнении ГСПП однозначно сопоставляются буферы, в которых хранятся асинхронно поступающие на входы КГВх модуля данные (фактические параметры соответствующих подпрограмм), которые «вырабатываются» подпрограммами модулей предшественников и направляются на выходы КГВых модуля. При этом механизм тегирования данных (приписывания тега данным) позволяет обеспечивать однозначность отношения «входные данные – результат» при параллельном выполнении ГСПП (см. п. 1.3)
Важным элементом структурирования ГСПП является понятие подсхемы. Понятие подсхемы в ЯГСПП даёт программисту эффективные средства структуризации параллельного алгоритма, выражающиеся через его схему, возможность представления ГС в виде нескольких уровней, отражающих шаги декомпозиции исходной задачи на подзадачи при построении параллельной программы. Графически подсхема строится аналогично схеме и содержательно представляет самостоятельный фрагмент ГСПП, подставляемый вместо одного или нескольких модулей подсхемы более высокого уровня в иерархии «схема – подсхема».
На рис.4 приведен пример двухуровневого вложения «схема – подсхема». Визуальная графическая разработка ГСПП поддерживается специально
разработанными программными средствами (см. раздел 2). Примеры программ на ЯГСПП приведены в приложении 1.
scheme: test1 level: 0 |
|
|
|
||
А) |
|
|
|
|
|
|
|
|
|
bool |
int |
|
Module_1 |
|
|
Module_2 |
|
char int bool |
bool |
bool |
|
float |
|
int |
char |
bool |
char |
float |
|
|
subst.sub_1 |
|
|
Module_3 |
|
|
char |
|
|
|
|
|
|
|
|
5 |
|
subscheme: sub1 level: 1 |
|
Б) |
|
int boolchar |
bool |
Module_1 |
|
char bool |
string |
string |
|
string |
|
char bool |
string |
subst.sub_2 |
|
bool |
|
bool |
|
Module_2 |
|
char |
|
subscheme: sub2 level: 2 |
|
|
|
В) |
|
char |
|
|
|
|
|
|
bool string |
bool |
|
|
|
Module_1 |
|
|
bool |
char |
float |
char |
bool |
float |
|
|
Module_2 |
|
Module_3 |
|
bool |
|
bool |
|
bool |
bool |
|
|
|
Module_4 |
|
|
|
bool |
|
Рис.4. Организационная структура ГС
А) Основная схема; Б) подсхема sub1; В) подсхема sub2 подсхемы sub1
Подстановочный модуль на схеме снабжается описателем subst, за которым после разделителя (точки) записывается имя подставляемой подсхемы. По соглашению подсхема имеет один начальный модуль с той же самой структурой и типами входов, что и у подстановочного модуля, и один конечный модуль, структура и типы выходов которого совпадают со структурой и типами выходов подстановочного модуля.
1.2 Текстовое представление ГСПП
ГСПП в текстовом представлении есть набор XML – файлов, иерархически описывающие структуру ГС и ее интерпретацию. Оно, возможно, окажется более удобным для опытного программиста, для человека, привыкшего иметь дело с XML. XML – формат текстового представления выбран не случайно. Во – первых, XML является общепризнанным стандартом для описания иерархических конструкций, причем разработано множество методов работы с ним, а во -вторых, внутреннее представление ГСПП хранится тоже в формате XML, поэтому наиболее разумным будет и текстовое представление описывать в формате XML.
Описание структуры ГС находится в отдельном XML-файле, в котором собраны все модули ГС и связи между ними, а также для каждого модуля в отдельном (уже другом) XML-файле приводится его подробное описание, описание всех его КГВх, КГВых, а также задается интерпретация КГВх, т.е. указание подпрограмм, сопоставленных с каждой КГВх. Если в ГС встр ечаются подсхемы, то их XML-представления строятся аналогично XMLописанию ГС. Ниже приведён DTD (Document Type Definition) всех XML-описаний ГСПП, который определяет синтаксис текстового представления ГСПП, приведён в приложении 2. Там же приведён пример текстового описания ГС, изображённой на рис. 4.
1.3.Операционная параллельная семантика ЯГСПП
Параллельное выполнение ГСПП представляется как последовательность смены состояний, каждое из которых характеризуется множеством процессов, индуцируемых при выполнении подпрограмм модулей ГСПП, сопоставляемых в интерпретации их конъюнктивным группам входов.
В потоковой модели вычислений предполагается, что любой имеющий самостоятельное значение элемент обработки информации (фрагмент программы) в потоковой схеме запускается на выполнение при наличии данных на его входе, причем только после завершения начатого процесса он может быть запущен снова, если входная очередь данных к элементу не пуста (обычно обработка данных во входной очереди выполняется согласно дисциплине FIFO – первый поступивший обрабатывается первым).
6
Таким образом, множество процессов ГСПП в любом состоянии, следуя этой потоковой схеме ее выполнения, не превосходит суммарного количества КГВх всех модулей ГСПП.
В модели параллельного выполнения ГСПП реализуются три вида параллелизма:
−пространственный, являющийся следствием информационной независимости модулей ГСПП и, как следствие, процессов выполнения подпрограмм, сопоставляемых их КГВх,
−потоковый, о котором сказано выше,
−параллелизм множества данных (SIMD – один поток команд, множество потоков данных), т.е. тот случай параллелизма, когда одна и та же программа модуля одновременно выполняется для разных данных на ее входе.
Для того, чтобы обеспечить однозначность между входными и выходными значениями при параллельном выполнении ГСПП, используется механизм тегирования. В операционной семантике языка ГСПП это выражается в том, что при наличии на всех входах (во входных буферах в реализации) конъюнктивной группы входов модуля данных, помеченных соответствующими тегами, параллельно запускаются на выполнение несколько процессов, каждый из которых однозначно идентифицируется тегом и сопоставленными ему данными. При передаче результатов от одного модуля к другому теги наследуются, позволяя разделять истории обработки различных данных при параллельном выполнении ГСПП.
Перейдем к описанию процесса выполнения ГСПП.
1. Модуль ГСПП считается готовым для выполнения по любой из своих КГВх, если на всех входах этой КГВх (в соответствующих входам буферах) есть данные, помеченные одним и тем же тегом.
Предполагается, что готовность модулей для выполнения определяется (в теоретическом плане) неким оракулом, который периодически просматривает данные всех КГВх всех модулей и определяет их готовность для выполнения. Практически в реализации (см. раздел 3) программы обслуживания буферов, входящие в состав программного обеспечения для управления параллельным выполнением ГСПП, при каждой записи в буферы соответствующих КГВх модулей проверяют в них наличие данных с одним и тем же тегом на всех входах КГВх. Если это условие выполняется, индуцируется процесс с составным именем <имя модуля>.<номер КГВх>.<имя подпрограммы>.<идентификатор тега>, предполагающий применение подпрограммы указанной в этом составном имени, к данным с указанным тегом. При этом все данные с данным тегом уничтожаются в буферной памяти КГВх с тем, чтобы исключить повторное занесение одного и того же процесса в список готовых для выполнения процессов. Исключение делается для данных, заданных на установочных ИС, они постоянно хранятся в буферной памяти соответствующей КГВх. Если оказывается, что в буферной памяти КГВх есть несколько данных с одним и тем же тегом, то эти процессы различаются (см. также раздел 3) добавлением к их идентификатору порядкового номера (который определяется порядком их занесения в буферы) в списке готовых процессов.
Различные теги идентифицируют различные данные, к которым одновременно применяется ГСПП, точнее, подпрограммы, отнесенные к соответствующим КГВх ее модулей (таким образом реализуется параллелизм множества данных, см. пример 2 ГСПП в приложении).
Не накладывается каких-либо ограничений на порядок проверки готовности модулей для выполнения, в принципе, контроль готовности модулей для выполнения может осуществляться одновременно при соответствующей реализации управляющих процессом выполнения программ, осуществляющих запись данных в буферы и контроль их состояния (см. далее).Также не фиксируется порядок выполнения готовых процессов, в принципе, все готовые процессы ГСПП могут выполнятся одновременно.
Считается, что модули, у которых КГВх не имеют входов (этим КГВх сопоставляются подпрограммы с пустым множеством параметров), готовы для выполнения по этим КГВх с момента инициализации выполнения ГСПП (см. раздел 3), но индуцируемые ими процессы
7
порождаются только один раз. Также считается, что подпрограммы, сопоставленные КГВх с пустым множеством входов, работают как генераторы, они либо сами вырабатывают данные, либо считывают их с некоторого носителя.
2. При выполнении процесса в его подпрограмме могут использоваться специальные системные команды (реализуемые посредством обычного обращения к специальным функциям) WRITE (запись), READ (чтение), OUT (выход) – позволяющие осуществлять межмодульное взаимодействие, т.е. строить различные схемы взаимодействия по данным между подпрограммами различных модулей путем чтения данных из буферов или записи данных в буферы, сопоставляемые входам КГВх модулей.
Команда WRITE имеет формат: WRITE(<номер КГВых>,<тег>,<список выходов><список переменных>), где список выходов есть перечисление номеров выходов КГВых, на которые передаются значения, присвоенные переменным в списке переменных при выполнении процесса-подпрограммы
Порядок записи выходов и переменных в списках определяет соответствие между
ними.
При выполнении команды WRITE сохраняется контекст подпрограммы, точнее процесса, где она была инициализирована, а после ее выполнения процесс продолжает свое выполнение в прерванном контексте (обычный механизм возврата после вызова процедуры).
Команда OUT имеет аналогичный формат аргументов, однако после ее выполнения процесс, в котором она возникла, считается завершенным и его контекст может быть уничтожен.
Команда READ имеет формат: READ (<номер КГВх>,<тег>,<список входов>,<список переменных>).
При ее выполнении также сохраняется контекст процесса, а после ее завершения процесс продолжает свое выполнение в старом контексте. Команда READ позволяет процессу читать данные с указанным тегом из буферов, сопоставленных КГВх, по которой процесс был инициирован. Считываемые из перечисленных входов КГВх данные с указанным тегом присваиваются переменным в списке переменных команды READ (возвращаемые процессу значения). При выполнении команды READ, если запрашиваемые данные еще не поступили в буферную память, ее выполнение задерживается, пока эти данные не поступят. Момент поступления контролируется при всякой записи данных в буферную память соответствующей КГВх. После выполнения команды READ запрашиваемые данные стираются из буферной памяти, происходит возвращение в контекст подпрограммы, где команда READ была индуцирована. Команда READ позволяет, в частности, организовывать потоковозависимый режим работы запущенного процесса, последовательно считывая и обрабатывая данные, поступающие на входы КГВх, по которой он был инициирован (см. пример 3 ГСПП в приложении 1).
Отметим, что в описанной семантике выполнения ГСПП (и ее реализации) предполагается, что для хранения данных, поступающих по информационным связям между модулями, буферы сопоставляются (организуются при выполнении) только для КГВх модулей, а не КГВых, поскольку каждая информационная связь берущая начало в КГВых любого модуля непременно приводит на вход одной из КГВх некоторого модуля ГСПП.
Для более “тонкой” работы с поступающими на КГВх модулей данными, в частности работы с сопоставляемыми им буферами, предусмотрена команда:
CHECK(<номер КГВх>.<тег>,<список входов>,<переменная>)
Команда CHECK проверяет наличие данных с указанными тегами на указанных входах КГВх. Эта команда позволяет процессу самому принимать решение в выборе своих действий в зависимости от наличия или отсутствия поступающих данных. Результатом ее выполнения является присваивание переменной общего количества данных с указанным тегом на входах КГВх, номера которых перечислены в списке входов.
3. Хотя команды WRITE и OUT позволяют сохранять или уничтожать контекст выполняемого процесса, ГСПП может быть организованна так, что выполнение ряда
8

процессов может осуществляться с забеганием вперед (с упреждением), а необходимость результатов их выполнения может быть определена позже после выполнения других процессов. Рассмотрим пример фрагмента ГСПП на рис.5,
M1 |
|
M2 |
M3 |
|
1 |
2 |
|
M4 |
|
|
M5 |
Рис. 5. |
Пример фрагмента ГСПП |
||
в котором модули М1 и М3 могут выполнятся с упреждением, однако вопрос о том, результат выполнения какого из них потребуется, может быть решен только после выполнения модуля М2, который осуществляет выход только по одной из своих КГВых. Если выход осуществлен по КГВых1, то результат выполнения модуля М3 не потребуется далее; аналогично не
потребуется результат выполнения модуля М1, если выход из модуля М |
2 будет |
осуществляться по КГВых2. |
|
Для того, чтобы уничтожить процессы (удалить их контексты), которые оказываются ненужными, в подпрограммах модулей может использоваться команда KILL – уничтожить процесс. Ее форма: KILL(<список имен уничтожаемых процессов>), где в списке имен уничтожаемых процессов указывается идентификатор процесса в виде четверки:
<имя модуля>.<номер КГВх>.<имя подпрограммы>.<имя тега> (см. введенную ранее идентификацию процесса)
Имя тега в этом составном идентификаторе процесса необходимо в связи со сказанным выше об организации теговой обработки.
4. Отметим еще ряд существенных элементов операционной семантики языка ГСПП, которые также важны при его реализации на параллельных системах.
1)Порядок выполнения множества процессов, существующих на каждом шаге выполнения ГСПП, не существенен, по крайней мере, программист должен позаботится о том, чтобы порядок выполнения процессов не влиял на правильность выполнения ГСПП, Вместе с тем, планирование выполнения процессов может оказать существенное влияние на сокращение времени выполнения ГСПП на параллельной системе.
2)Определение готовых для выполнения процессов следует дисциплине FIFO: проверка на наличие в буферной памяти КГВх данных с одним и тем же тегом на всех ее входах осуществляется в порядке занесения этих данных в буферную память.
Аналогично, при выполнении команды READ необходимые данные ищутся буфере данных в порядке занесения в нее данных; при выполнении команд WRITE и OUT данные записываются в буферную память в порядке поступления (в «хвост» очереди данных).
3)Поскольку с одним и тем же буфером данных могут одновременно работать несколько процессов (чтения или записи), поэтому в реализации нужно обеспечить взаимное исключение одновременных подобных действий.
Примеры 1÷3, приведенные в приложении 1, иллюстрируют технологию программирования и описание различных форм параллелизма средствами языка ГСПП.
В примере 1 присутствует только пространственный параллелизм, пример 2 иллюстрирует использование тегирования при описании SIMD-параллелизма, в примере 3 показано, как описывается потоковая обработка.
2. Инструментальная среда разработки ГСПП
Инструментальная среда предназначена для разработки граф-схемных параллельных программ и устроена таким образом, что программист может разделять аспекты при проектировании программы, последовательно переходя от чисто графического ее представления к содержательному, используя многооконную организацию. Например, в отдельном окне для каждой КГВх модуля можно задать связанную с ней подпрограмму, отредактировать текст самой подпрограммы, а также автоматически проверить правильность
9

согласования типов входов КГВх с типами связанных с ними выходов КГВых. Также предусмотрена возможность переходить в новое окно в тот момент, когда пользователь добавляет к ГС подсхему, с целью концентрирования основного внимания пользователя на разработке подсхемы.
При необходимости пользователь может перейти к окну текстового представления программы, причем, поскольку существует взаимно-однозначный переход между текстовым и графическим представлением программы, любое изменение в графическом представлении приводит к соответствующим изменениям в текстовом представлении и наоборот.
Основные блоки инструментальной среды представлены на рис. 6
Блок графической |
|
Блок текстовой |
разработки ГСПП |
|
разработки ГСПП |
|
|
|
Блок взаимной
трансляции
Блок
координации
Блок взаимодействия с
базой данных
ОС Windows
База данных
Рис. 6. Архитектура инструментальной среды
Блок разработки ГСПП в графическом представлении позволяет визуально разрабатывать ГС, а именно добавлять, удалять и редактировать элементы ГСПП. Также данный блок следит за корректностью вводимых данных и своевременным обновлением информации в окнах инструментальной среды.
Блок разработки ГСПП в текстовом представлении управляет ходом построения текстового представления и по своему назначению представляет собой аналог блока разработки графического представления, но работает с текстом ГСПП.
Блоки графической и текстовой разработки ГСПП помимо редактирования, синтаксического анализа и выявления ошибок в ГС создаваемых программ имеют средства для поддержки процессов разработки программ «сверху – вниз» и «снизу – вверх». Декомпозиция и структурирование, присущие процессу разработки программ «сверху – вниз», легко реализуются в инструментальной среде благодаря модульной организации ГСПП и возможности выделения подсхем.
Механизм задания интерпретации ГС требует обращения к конкретному языку (или языкам) последовательного программирования и их реализации на соответствующей платформе. Как уже было сказано ранее, в ЯГСПП в качестве описания подпрограмм, сопоставляемых КГВх модулей, могут использоваться широко известные последовательные языки (C/C++, Pacal, Java и др.). Поскольку инструментальная среда разработана под ОС Windows, в задании интерпретации можно применять все стандартные средства этой ОС для написания подпрограмм, сопоставляемых КГВх модулей.
Все необходимые для задания интерпретации ГС подпрограммы образуют специальную библиотеку (или набор библиотек), а доступ к ним осуществляется, как это определено синтаксисом ЯГСПП.
Блок взаимной трансляции состоит из двух подблоков. Первый подблок занимается переводом графического представления в текстовое. Все визуально созданные пользователем элементы ГСПП однозначно отображаются в текстовое представление. Второй подблок переводит текстовое представление ГСПП в графическое. Для взаимной трансляции между представлениями ГСПП используется ее внутреннее представление в формате XML, которое также используется в качестве исходной информации для выполнения ГСПП на вычислительной системе (см. раздел 3).
В инструментальной среде используется база данных, как средство для длительного хранения всей информации о разрабатываемых пользователями ГСПП. Также в ней
10
сохраняются «следы» («логи») разработки ГСПП, их завершенные версии и библиотеки подпрограмм.
Отметим также, что в инструментальной среде предусмотрен целый ряд соглашений, усиливающих возможности визуального проектирования ГСПП за счет выбора цвета для изображения стандартных типов на входах и выходах модулей, цветового выделения подстановочных модулей (отличного от обычных модулей) и др.
В заключение этого раздела отметим, что арсенал средств поддержки разработки программ может быть намного шире, в частности, в настоящее время планируется расширить инструментальную среду путем включения в нее средств моделирования процессов выполнения ГСПП на заданной конфигурации кластера.
3. Реализация ЯГСПП на кластерных системах
3.1 Физическая среда реализации
Мы исходим из того, что локальная сеть (в том числе сеть персональных компьютеров) является основным “строительным блоком” или узлом вычислительной системы или кластера (рис. 7)
Рис. 7. Узел кластера
Узел кластера – хорошо сбалансированная по отношению, к быстродействию компьютеров, их количеству и пропускной способности коммуникации вычислительная система, так что на ней можно эффектно осуществлять реализацию параллельных вычислений в достаточно широком диапазоне вариаций степени распараллеливания программ [11] от “крупнозернистого” до “мелкозернистого” параллелизма.
Задача сервера на рис. 7, как важного логического элемента узла кластера, – обеспечение на программном уровне механизма масштабирования кластера, реализация интерактивных взаимодействий между узлами, управление их загрузкой и др. (см. далее). Путем введения соответствующей стратегии соподчинения серверов узлов кластера можно легко построить различные схемы управления в системе: строго централизованное, иерархическое, полностью децентрализованное и др.
Расширение системы достигается путем объединения кластерных узлов, как правило, через более медленные коммуникации. По-сути, эта идеология построения больших масштабируемых вычислительных структур, продиктованная также техническими и технологическими соображениями, прослеживается в архитектуре всех самых мощных компьютерных систем: SPP, Hewlett Packard и Convex [14], SP1 и SP2, ASCI WHITE IBM [15]
и др.
В них в качестве узла обычно выступает 8, 16 или 32 – процессорная подсистема, в которой используются самые быстрые коммуникации (коммутаторы, переключательные матрицы и т.п.). Для межузловых соединений применяются менее дорогие и скоростные коммуникации. Эта особенность в организации вычислительной системы требует, чтобы при вычислениях более частые обменные взаимодействия происходили внутри узла, так как в
11

нем можно планировать вычисления с большей степенью распараллеливания, т.е. мелкозернистый параллелизм. В то же время на межузловом уровне планирование загрузки (ее реализует сервер узла, рис. 7) должно осуществляться на более высоком уровне сложности частей программы, пересылаемых между узлами, с целью уменьшения времени, затрачиваемого на обмены [11].
Отметим также, что компьютеры узла могут быть многопроцессорными, иметь векторные сопроцессоры, что так же должно учитываться как на программном уровне, так и при планировании параллельных вычислений на кластере.
3.2 Управление параллельными вычислениями на кластере
Собственно задача управления параллельными вычислениями формулируется как задача минимизации времени выполнения параллельной программы и используемых при этом ресурсов (обычно количества используемых компьютеров или процессорных элементов в вычислительной системе). Ее практическое решение осуществляется через механизмы планирования и требует тонкого учета специфики задания выполняемой параллельной программы, степени ее распараллеливания, загруженности различных элементов вычислительной системы (компьютеров, коммуникаций и др.), времени их безотказной работы и др. [1,10,11].
Эта проблема требует специального анализа, поэтому далее рассматриваются, в основном, организационные аспекты реализации управления параллельным выполнением ГСПП на кластерах.
В организационной структуре управления можно выделить два относительно самостоятельных уровня: общесистемный, в задачу которого входит управление конфигурированием кластера, контроль и планирование загрузки (узлов, компьютеров), реакция на отказы компонентов кластера и др., и уровень собственно управления параллельными процессами, индуцируемыми при выполнении ГСПП.
На рис. 8 представлена структура и основные блоки управления процессом выполнения ГСПП на кластерных системах.
|
|
|
|
|
|
|
Блоки системного уровня |
||||
|
|
|
|
|
|
|
|
|
|
|
|
УК |
|
ИН |
|
ОТ |
|
ОБ |
|
УЗ |
|
АД |
|
|
|
|
|
|
|
|
|
|
|
|
|
КО
УБ |
|
УП |
|
ПЛ |
|
ОС |
|
|
|
|
|
|
|
Интерпретатор
Блоки процессного уровня
Рис. 8. Структура и основные блоки управления процессом выполнения ГСПП
Кратко опишем функции указанных на этом рисунке блоков.
АД – блок администрирования, в функции которого входят инсталляция программных средств для управления на кластере, оперативное получение информации о функционировании (например, загрузке) кластера, “вмешательство” в его работу администратора, если это оказывается необходимым.
УК – блок управления конфигурациями, в задачу которого входит конфигурирование узла кластера (или кластера в целом) и его реконфигурирование в процессе функционирования в связи с отказами и восстановлениями компонентов кластера (компьютеров, коммуникаций и др.), необходимостью динамического масштабирования.
ИН – блок инициализации выполнения ГСПП (см. далее).
12
ОТ – блок отказоустойчивости; его функции: реакция на отказы компонентов кластера и реализация принятой стратегии периодического сохранения состояний компонентов кластера на случай их отказа. Стратегия может быть или простейшей, предусматривающей периодическое сохранение состояния компьютера или другого контролируемого компонента кластера на общем носителе памяти (например, дисковой памяти сервера узла) или более сложной, например основанной на той или иной схеме “договоренности” между компьютерами о периодическом сохранении компьютерами состояний других компьютеров на случай отказа последних [10].
Отказы или восстановления компонентов кластера, фиксируемые блоком ОТ, также передаются блоку УК в качестве информации для изменения конфигурации кластера.
ОБ – блок реализации по соответствующему протоколу интерфейсных взаимодействий (обменов сообщениями и данными) между компьютерами кластера.
УЗ – блок управления загрузкой кластера, ее прогнозирования и перераспределения параллельных процессов между компьютерами узла или между узлами кластера с целью достижения максимальной эффективности его работы. Этот блок работает в тесной связи с блоком планирования процессов (ПЛ) каждого компьютера, получая через него необходимую информацию о загруженности компьютера (см. п. 3.2.2).
Блок координации (КО) представляет из себя в программном смысле монитор и осуществляет все взаимодействия друг с другом перечисленных блоков.
Блоки процессного уровня непосредственно связаны с определением готовности и идентификацией индуцируемых при выполнении ГСПП процессов (блок управления буферами – УБ), их организацией и контролем состояний (блок управления процессами УП) и планированием выполнения (блок планирования - ПЛ).
Блок УП также реализует, путем обращения к операционной системе (ОС) функции, связанные с постановкой процессов в очередь для выполнения на процессоре компьютера и идентификацией команд обращения к блоку управления буферами, сопоставленными КГВх модулей ГСПП (команды READ, WRITE, OUT, CHECK, см. п.1.3 - описание операционной семантики языка). Блок УП выполняет также команды KILL – “уничтожения” процессов, выполнение которых было инициировано с упреждением и на некотором шаге выполнения которых обнаруживается, что их результаты не будут использованы.
Блоки, реализующие эти действия, образуют интерпретатор ЯГСПП (рис. 8).
3.2.1 Описание работы интерпретатора ГСПП
Как было сказано в описании инструментальной среды, при разработке ГСПП строится ее внутреннее представление (см. рисунок 8), которое, с одной стороны, является мостом между ее графическим и текстовым представлением, а, с другой стороны, служит исходной информацией о ГСПП для интерпретатора.
Перед началом выполнения ГСПП это внутреннее представление сначала инициализируется пользователем через обращение к блоку инициализации ИН путем задания значений признаков (признаки обозначены на рис. 9 символом П), значений тегданные на свободных или установочных входах модулей ГСПП, а также заполнения “полей” с указанием идентификаторов компьютеров (номеров компьютеров кластера), на которых должны быть организованны буферы для КГВх соответствующих модулей.
Предполагается, что имея предварительную информацию о “поведении” ГСПП в процессе ее выполнения и конфигурации кластера, пользователь может сделать достаточно “грамотное” распределение буферов, сопоставляемых КГВх модулей ГСПП, по компьютерам кластера.
Двоичный признак П в описании модулей ГСПП показывает, является ли модуль подстановочным, т.е. должна ли вместо него подставляться подсхема, и если да, то заполняется указатель Y на описание этой подсхемы (аналогично для описания модулей подсхемы). В описании входов КГВх модуля этот признак показывает, является ли вход установочным или нет. В описаниях КГВых модуля в таблице приемников выходов КГВых
13
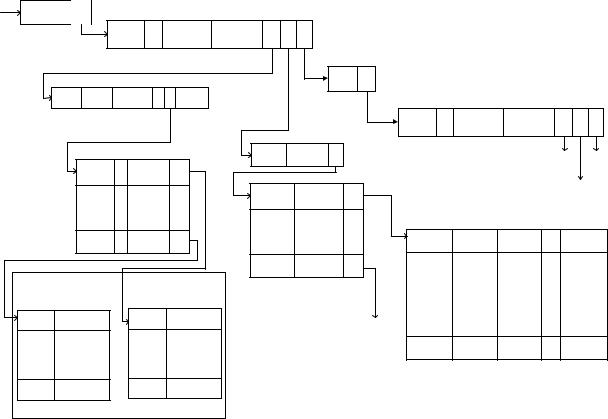
модулей этот признак указывает, находится ли буфер, сопоставленный КГВх, на том же |
|||||||||||||||||||
компьютере, начальное размещение на котором указал пользователь, или на другом |
|||||||||||||||||||
компьютере, идентификатор которого указан в соответствующих полях описаний входов |
|||||||||||||||||||
КГВх и приемников выходов КГВых. Это упрощает выполнение команд чтения из буферной |
|||||||||||||||||||
памяти и записи в нее (команд READ, WRITE и OUT), а также команды CHECK (проверки |
|||||||||||||||||||
данных в буфере), которые “возникают” при выполнении подпрограмм модулей. |
|
|
|||||||||||||||||
Y |
Имя ГСПП |
Y |
|
Описание модулей ГСПП |
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
Имя |
П |
Количеств |
Количество |
Y |
Y |
Y |
|
|
П - признак |
|
|
|
|
|
|
|
|
|
модуля |
о КГВх |
КГВых |
|
Описание |
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
У - указатель |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
подсхем |
Идент. К - идентиф. компьютера |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
Имя |
|
|
|
|
|
|
|
|
Описание КГВх модуля |
|
|
|
|
|
|
схемы Y |
|
|
|
|
|
|
||||
|
|
Номер Кол-во |
"Путь" к П Y Идент. |
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
КГВх |
входов подпр-ме |
К |
|
|
|
Описание |
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
Имя |
Количеств |
Количество |
Y |
Y Y |
|||
|
|
|
|
|
|
|
|
|
|
|
|
КГВых |
|
модуля П |
о КГВх |
КГВых |
|
||
|
|
|
|
|
|
|
|
|
|
|
|
модуля |
|
|
|
К описанию |
|
||
|
|
|
Описание входов КГВх |
|
Номер |
|
Кол-во |
Y |
|
|
К описанию |
||||||||
|
|
|
|
КГВых |
выходов |
|
|
КГВх |
|
|
подсхемы |
||||||||
|
|
|
Вход 1 |
|
П |
тип |
Y |
|
Описание выходов КГВых |
|
|
подсхемы |
|
||||||
|
|
|
. . . |
. |
|
|
|
|
|
К описанию |
|||||||||
|
|
|
|
Выход 1 |
тип |
Y |
|
|
|
|
|||||||||
|
|
|
. . . |
. |
|
|
|
|
|
КГВых |
|||||||||
|
|
|
|
|
. |
|
. |
. |
Описание приемников |
|
подсхемы |
||||||||
|
|
|
. . . |
. |
|
|
. |
|
. |
. |
выхода 1 |
|
|
|
|
||||
|
|
|
|
|
|
Имя |
Номер |
Номер |
П |
|
Идент. К |
||||||||
|
|
|
Вход n |
|
П |
тип |
Y |
|
|
. |
|
. |
. |
модуля |
|
||||
|
|
|
|
|
|
|
|
|
|
|
КГВх |
входа |
|
|
|
||||
|
|
|
|
|
|
|
|
|
Выход m |
тип |
Y |
. |
. |
. |
. |
|
. |
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
Данные на входе n |
|
Данные на входе 1 |
|
|
|
К описанию |
. |
. |
. |
. |
|
. |
||||||
|
|
Ссылка на |
|
|
|
Ссылка на |
|
|
|
. |
. |
. |
. |
|
. |
||||
|
Тег |
|
Тег |
|
|
|
приемнико |
|
|||||||||||
|
|
данные |
|
|
|
|
|
||||||||||||
|
|
данные |
|
|
|
|
|
|
|
в входа m |
|
|
|
|
|
|
|||
|
. |
|
. |
|
|
. |
. |
|
|
|
|
|
|
Имя |
Номер |
Номер |
П |
|
Идент. К |
|
. |
|
. |
... . |
. |
|
|
|
|
|
|
модуля |
КГВх |
входа |
|
||||
|
. |
|
. |
|
|
. |
. |
|
|
|
|
|
|
|
|
|
|
|
|
|
Тег |
Ссылка на |
|
Тег |
Ссылка на |
|
|
|
|
|
|
|
|
|
|
|
|||
|
данные |
|
данные |
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
Буферная память для КГВх |
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
Рис. 9. Внутреннее представление ГСПП |
|
|
|
|
|
|||||||
|
Процесс инициализации выполнения ГСПП осуществляется через блок ИН |
||||||||||||||||||
заполнением указанных полей внутреннего представления ГСПП значениями, заданными |
|||||||||||||||||||
пользователем, загрузкой его на все компьютеры кластера вместе с блоками управления |
|||||||||||||||||||
процессного уровня, выделения начальной памяти для буферов, сопоставляемых КГВх |
|||||||||||||||||||
модулей, и занесения в них данных, “присвоенных” пользователем установочным входам |
|||||||||||||||||||
модулей (см. рисунок 9). Итог всей этой работы – пользовательское приложение, готовое для |
|||||||||||||||||||
выполнения на соответствующем компьютере кластера под управлением его ОС. |
|
|
|
||||||||||||||||
|
Рассмотрим более подробно функции блоков управления буферами (УБ) и |
||||||||||||||||||
процессами (УП) интерпретатора ГСПП. |
|
|
|
|
|
|
|
|
|
||||||||||
|
Блок УБ выполняет следующие функции: |
|
|
|
|
|
|
|
|||||||||||
−организацию буферов для КГВх, включая формирование запросов к ОС на выделение памяти, ее “чистка” в связи с частичным освобождением при чтении данных,
−выполнение команд чтения, записи или проверки состояния буферной памяти,
−определение и идентификацию готовых для выполнения процессов.
В начале выполнения ГСПП готовыми для выполнения являются все процессы – подпрограммы, в буферной памяти которых, то есть на всех входах соответствующих им КГВх, есть данные, помеченные одним и тем же тегом (все фактические параметры подпрограммы). Начальный запрос на наличие таких процессов (на каждом компьютере кластера) определяется блоком УП путем обращения к блоку УБ. В дальнейшем всякая команда записи в буферы (команды WRITE и OUT), которая возникает при выполнении
14
процесса на компьютере, вызывает обращение к блоку УП, который переадресует ее блоку УБ, если указанные в ней выходы КГВых, на которые передаются данные, связаны с входами КГВх, буферы которых размещены на данном компьютере (см. рис. 9, описание выходов КГВых). При этом, выполняя команду записи в буферную память КГВх, блок УБ одновременно проверяет в ней наличие на всех ее входах данных с одинаковым тегом. Если обнаруживается, что такие данные существуют, то блок УБ передает блоку УП идентификатор готового процесса вместе с тегом и фактическими параметрами подпрограммы, сопоставленной КГВх. Формат этой информации о новом процессе предопределен выбранным внутренним представлением ГСПП (см. рис. 9, а также описание операционной семантики ЯГСПП) и имеет вид: <имя модуля>:<номер КГВх>.<”путь” к подпрограмме>.<идентификатор тега>.<список фактических параметров>.
Одновременно в буферной памяти, память, занятая этой информацией, переводится в статус освобожденной и может использоваться в дальнейшей работе. Также блок УБ может при необходимости затребовать у ОС дополнительную память для хранения записываемых в буферную память новых данных.
На рис.10 и 11 приведены блок-схемы программ выполнения команд READ и WRITE (выполнение команды OUT аналогично выполнению команды WRITE за исключением того, что контекст процесса, в котором она возникает, после ее выполнения уничтожается и занятая им память освобождается).
Напомним, что команды READ и WRITE имеют следующий формат задания параметров: READ(<номер КГВх>,<тег>,<список входов>,<список переменных>); WRITE(<номер КГВых>,<тег>,<список выходов>,<список переменных>).
Укоманды READ в списке входов перечислены номера входов КГВх, в буферной памяти которой необходимо прочитать данные с этими номерами и указанным тегом. В списке переменных перечислены имена переменных, которым должны быть присвоены значения, возвращенные в подпрограмму, в процессе выполнения которой команда READ встретилась.
Укоманды WRITE в списке выходов перечислены выходы КГВых, на которые должны быть переданы значения, которые присвоены указанным переменным в процессе выполнения подпрограммы, в которой встретилась команда WRITE. По умолчанию, соответствие входов (выходов) и сопоставляемых им переменных определяется порядком и перечисления тех и других в соответствующих списках. Команда OUT имеет формат параметров, совпадающий с командой READ.
Команда READ
да P1 нет
P2 |
|
|
|
да |
|||||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Присвоить значения переменным |
|
||
|
нет |
|
|
|
(считывается из буферной |
|
|||
|
|
|
|
|
|
памяти), указанным в команде |
|
||
|
|
|
|
|
|
READ |
|
||
Перевести команду READ |
|||||||||
|
|
|
|
|
|
||||
в задержанное состояние |
|
|
|
|
|
|
|||
|
|
Вернуть управление (с присвоенными |
|||||||
до момента поступления |
|
|
|||||||
|
|
|
значениями переменных) в |
||||||
данных (определяется |
|
|
|
||||||
|
|
|
подпрограмму процесса, который |
||||||
блоком УБ) |
|
|
|
||||||
|
|
|
индуцировал команду READ |
||||||
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
По внутреннему представлению (см. описание КГВх) определить компьютер, на котором находятся буферы указанной в команде READ КГВх
Переслать на этот компьютер (блоку УБ) команду READ для выполнения
Выполнить команду READ и возвратить результат ее выполнения (требуемые данные) блоку УБ на компьютере, от которого команда была получена
P1: проверка условия, находятся ли буферы КГВх, указанной в команде READ, на этом же компьютере
P2: проверка условия, есть ли затребованные данные с указанным в команде READ тегом в буферной памяти
Рис.10. Блок-схема выполнения команды READ
15

1.По внутреннему представлению (см. описание выходов КГВых на рис. 9) определить номера КГВх модулей и номера их входов, на которые командой WRITE передаются значения переменных, перечисленных в списке ее параметров. Перейти к пункту 2.
2.Для каждой КГВх и номеров ее входов, на которые должны быть переданы параметры, сформировать “внутренние” команды WRITE1(<номер КГВх>,<тег>,[<значение>’→’<номер входа>]). Перейти к пункту 3.
3.Все сформированные в п.2 команды WRITE1 передать для выполнения блокам УБ на компьютеры, на которых находятся буфера КГВх. Перейти к пункту 4.
4.Завершить процесс выполнения команды WRITE после выполнения блоками УБ всех разосланных команд WRITE1.
Рис. 11. Последовательность шагов выполнения команды WRITE
Вотличие от команд READ, WRITE и OUT команда CHECK(<номер
КГВх>,<тег>,<список входов>,<переменная>) позволяет процессу проверить, есть в буферной памяти данные с указанным тегом. Возвращаемым процессу значением, присеваемым переменной в этой команде, является количество данных в буферной памяти с данным тегом.
Блок управления процессами (УП) реализует следующие функции:
−формирование списка готовых процессов (см. рис 12), в котором помимо идентифицирующей процесс информации и входных данных, необходимых для обращения к соответствующей подпрограмме, “поддерживается” также дополнительная информация (поле “характеристики”) о состоянии процесса, его приоритете, других характеристиках (времени, затраченным процессом на выполнение и др.);
−взаимодействие с ОС, управление выполнением “системных” команд WRITE, READ, OUT и CHECK, возникающих при выполнении процессов (см. блок-схемы выполнения команд WRITE и READ на рис. 10 и 11). Эти команды адресуются сначала блоку УП, который реализует их, используя блок УБ;
−взаимодействие с блоком планирования (ПЛ);
−при назначении процессов на выполнение на процессоре компьютера, с блоком обмена данными между компьютерами при выполнении команд READ и WRITE, если требуемые буферы размещены на другом компьютере.
3.2.2. Планирование параллельных процессов и управление загрузкой кластера
Как следует из п.п. 3.2, управление параллельным выполнением ГСПП на кластере условно разделено на два уровня: системный и процессный.
Схема на рис. 12 показывает, каким образом осуществляется управление выполнением ГСПП на процессном уровне.
Блок УП вместе с блоком У Б формирует список готовых для выполнения процессов. В этот список включаются процессы, которые блок УБ определяет как готовые при каждой записи в разнесённые по компьютерам буферы данных (это происходит при выполнении команд write и out), а также процессы, перемещаемые блоком на компьютер с других компьютеров с целью достижения равномерной загрузки кластера.
Планировщик ПЛ упорядочивает эти процессы и в соответствии с принятой стратегией часть из них отправляет ОС на выполнение.
ОС компьютера организует выполнение стоящих в очереди 1 процессов к процессору компьютера. Обычно ОС выполняет процессы в порядке их поступления, выделяя каждому процессу фиксированный квант времени (здесь мы не актуализируем другие известные и более эффективные дисциплины обслуживания процессов на компьютере с многоуровневыми очередями и различными способами квантования). Выполняясь на процессоре, процесс либо завершает свое выполнение в течении выделенного кванта, сообщая об этом через команду OUT блоку УП, либо в нем возникают команды WRITE, READ, CHECK, KILL, которые реализуются посредством блока УП, либо процессу требуется обмен данными с дисковой памятью. В последнем случае он попадает в очередь 2
16
к системе обмена оперативная память – диски (оп/д). “Появление” в процессе команд READ, WRITE, OUT, KILL и CHECK, в свою очередь, может приводить к необходимости обмена данными с другими компьютерами, что реализуется путем обращения блока УП к блоку ОБ, который организует очередь 3 соответствующих запросов на обмен к ОС, которая выполняет их в соответствии с принятой в ней схемой межкомпьютерного обмена.
Список готовых для выполнения процессов
имя |
номер |
путь к |
тег |
данные |
характе- |
процесса |
КГВХ |
подпрограмме |
|
|
ристики |
|
|
|
|
|
|
ОБ |
УБ |
УП |
ПЛ |
Управление |
|
|
|
|
параллельными |
|
|
|
|
процессами |
|
|
|
Завершение |
|
|
очередь 3 |
|
|
процесса |
|
|
|
очередь 1 |
процессор |
Запросы к ОС на обмен с |
|
оп/д |
очередь 2 |
|
другими компьютерами |
|
|||
|
|
|
||
|
|
|
исчерпание кванта |
|
|
|
|
команды WRITE, READ, OUT, CHEK, KILL |
|
Рис. 12. Схема управления процессами на компьютере
Два самых важных показателя загруженности компьютера, которые используются планировщиком, - это интенсивность обменов с дисковой памятью и интенсивность обменов с другими компьютерами, которые вычисляются как усредненные величины на некотором интервале работы компьютера.
Исследования 70-х годов по эффективности систем управления страничной памятью компьютеров, работающих в многопрограммном режиме (т.е. в нашем случае, многопроцессном) [16-20], а также новейшие исследования влияния интенсивности обменов оперативная память – диски на эффективность работы кластерных систем являются попрежнему актуальными [13]. Они показывают, что даже при современных достаточно больших объемах оперативной памяти компьютеров и использовании более быстродействующей дисковой памяти, чем это было ранее, интенсивность обменов оперативная память – диски является ключевым параметром эффективности работы компьютера в многопроцессном режиме. Реальные эксперименты показывают, что при высокой интенсивности этих обменов целесообразно перенести определенное количество процессов с рассматриваемого компьютера на другой (или другие), несмотря на то, что при этом будет также затрачено непроизводительное время на передачу данных по каналам межкомпьютерной (и, возможно, межузловой) связи кластера. Однако, при использовании достаточно быстрых коммуникаций, несмотря на неизбежную латентность, – это верный путь к достижению определенного баланса загрузки компьютеров (также узлов) кластера.
Решение о перемещении процессов принимает блок системного уровня управления загрузкой УЗ (см. 3.2) по информации, которую планировщики компьютеров передают периодически на сервер узла. Именно блок УЗ разделяет компьютеры по степени их загруженности, используя получаемые данные от планировщиков компьютеров, используя для этой цели "нечёткую" шкалу: перегружен, нормально загружен, недогружен.
Рассматривая проблему планирования параллельных процессов более широко, необходимо комплексно учитывать следующие параметры: интенсивность обменов данными между компьютерами и в системе оперативная память – диски, время, которое тратится на организацию управления (реактивность управления), а также степень распараллеливания
17
[11]. Последний параметр достаточно сложно “регулировать” [11], тем не менее, при недогрузке кластера (заметном времени простоя компьютеров) он позволяет путем перехода на более глубокий уровень распараллеливания увеличить количество выполняемых процессов и тем самым лучше загрузить компьютеры. С другой стороны, это приводит к увеличению интенсивности обменов между компьютерами кластера и времени, затрачиваемого на управление. Найти нужное соотношение при управлении перечисленными параметрами – основная задача планировщика в обеспечении эффективной работы кластера.
Заметим, что увеличение степени распараллеливания программ на ЯГСПП достаточно просто может достигаться, если помимо перечисленных выше и внешне отражаемых в ГСПП видах параллелизма используется также возможность задания в самих процессах (подпрограммах модулей) векторного параллелизма и параллелизма ветвей, процессов-нитей и др.
4. Программная реализация управления параллельным выполнением ГСПП на кластерных системах
Для параллельного выполнения ГСПП на ВС разработана система программных средств – система управления. Эта система обеспечивает корректность параллельного выполнения программ на кластерной ВС, возможность отладки этих программ, хранение граф-схем и модулей, надёжную передачу данных между процессами модулей и пр.
Помимо перечисленных выше основных задач, связанных с выполнением граф-схем, система должна выполнять и другие функции. Следующий список содержит основные функциональные требования к реализации системы управления параллельным выполнением граф-схемных программ на кластерах:
−инициализация выполнения граф-схем,
−определение готовности процессов для выполнения,
−назначение процессов на выполнение, контроль их состояния,
−реализация команд языка: Read, Write, Out, Kill и Check,
−контроль состояния компьютеров кластера,
−планирование процессов с целью оптимизации использования ресурсов и уменьшения времени выполнения граф-схемы,
−реализация интерфейса взаимодействия компьютеров кластера,
−параллельное выполнение нескольких процессов,
−общая (для всех узлов ВС) система хранения данных,
−возможность мониторинга процессов системы,
−возможность выполнения подпрограмм модулей в различных ОС,
−Система управления также должна обеспечить:
−устойчивость к изменениям конфигурации кластера,
−надёжный протокол обмена данными между узлами кластера,
−высокую производительность.
Система управления параллельным выполнением ГСПП представляет собой набор программных средств, устанавливаемых на каждом компьютере или узле кластера. Состав и организация устанавливаемых программных средств приведена на рис. 13.
Центральным элементом данной архитектуры является сервис. Сервис – это набор функций системы, выполняющих одну общую задачу. Сервис выполнения содержит все функции, необходимые для выполнения ГСПП на кластере. Именно сервисы реализуют функции, непосредственно связанные с процессом выполнения ГСПП, описанном в предыдущем разделе. Все остальные элементы архитектуры выполняют системные функции:
−инициализация сервисов,
−управление конфигурацией кластера,
−передача данных между узлами кластера,
18

−взаимодействие с внешними системами,
−управление сервисами.
Рис. 13. Архитектура программных средств управления процессом выполнения ГСПП
Передача данных между узлами кластера осуществляется компонентом Sender, а получение – компонентом Reciever. Для каждого внешнего (по отношению к данному) узла сети в локальной версии системы существуют свои Sender и Reciever. Управление этими компонентами осуществляют соответственно Sender Dispatcher и Reciever Dispatcher. Компонент Client Sender/Reciever осуществляет обмен данными с внешними системами. При запуске системы создаётся компонент Service Manager, который при помощи Service Loader’a загружает сервисы и инициализирует их.
В сущности, предустановленный на компьютере набор программных компонентов является контейнером сервисов. Контейнер организует вызов необходимых сервисов, предоставляет сервисам функции высокого уровня, создаёт окружение. На различных узлах кластера в принципе могут функционировать различные наборы сервисов. Набор сервисов узла кластера определяет роль данного узла в системе. Назовём некоторые сервисы из системы управления:
−сервис конфигурации контролирует конфигурацию узла кластера и предоставляет её остальным узлам,
−сервис реестра предоставляет другим узлам интерфейс реестра системы. Реестр – это база данных системы, которая имеет иерархическую структуру. Реестр содержит информацию, необходимую для работы системы: программы граф-схем, конфигурацию кластера, информацию о пользователях и т.д. Также реестр может использоваться графсхемами для хранения данных в ходе выполнения,
−сервисы управления выполнением – это набор сервисов, которые выполняют функции по запуску, контролю выполнения граф-схем, управлению буферами и планированию. Сервис выполнения – это основной сервис системы, отвечающий за выполнение
ГСПП, соответственно он должен работать на всех узлах кластера, которые участвуют в параллельных вычислениях. Во время инициализации данный сервис получает модули и граф-схемы, инсталлированные на данном узле. Инсталляция производится при помощи специального программного средства, входящего в состав системы, и заключается в копировании файлов модулей, а также описаний модулей и граф-схем и регистрацию данных сущностей в системе.
Описание модуля содержит идентификатор адаптера для данного модуля. Адаптер – это подключаемый компонент системы, осуществляющий запуск и остановку процесса модуля. Таким образом, один адаптер может использоваться для определённого класса модулей. Классификация определяется сценарием запуска. Например, для модулей, написанных на языке C++ в виде консольных приложений, будет применяться один адаптер, а для модулей, представляющих собой динамическую библиотеку DLL – другой. Также есть специальный регламент поведения модуля и спецификация интерфейса взаимодействия процесса модуля с системой. Таким образом, если программисту необходимо реализовать
19

модуль на каком-нибудь языке программирования, он должен создать библиотеку для работы с системой на этом языке программирования и придерживаться установленного регламента. Данная библиотека может далее использоваться для реализации любого модуля на этом языке программирования. Библиотека предоставляет программисту модулей функции высокого уровня, такие как запись данных на конъюнктивную группу выходов, завершение процесса граф-схемы и т.д. Подобная стратегия (рис. 14) позволяет программировать модули на разных языках программирования и даёт возможность выбора наиболее подходящего языка.
Рис. 14. Взаимодействие процесса модуля с системой
Взаимодействие между локальными компонентами системы управления осуществляется при помощи протокола TCP/IP посредством передачи сообщений определённого формата. Каждое сообщение имеет имя и тело сообщения. При получении сообщения компонент системы Service Manager по имени сообщения определяет сервис, которому предназначено это сообщение и передаёт его найденному сервису, который выполняет обработку данного события. Список сообщений, обрабатываемых сервисом, предоставляется системе самим сервисом. По такому же сценарию проходит взаимодействие системы с модулями и внешними системами. У каждого типа сообщений есть набор метаданных, который включает вид возможных отправителей для данного сообщения: локальный компонент системы, модуль или внешняя система.
Функции системы по управлению выполнением граф-схем распределены между несколькими сервисами. Набор этих сервисов должен присутствовать на каждом узле кластера, участвующем в вычислениях. Список данных сервисов следующий:
−сервис выполнения. Данный сервис отвечает за запуск граф-схем, управление процессами, индуцируемыми при выполнении. Этот сервис осуществляет также все взаимодействия между процессами модулей, получает запросы на выполнение функций WRITE, READ, CHECK, KILL, OUT, KILL,
−сервис управления буферами. Данный сервис реализует функции WRITE, READ, CHECK и OUT,
−сервис планирования. Осуществляет планирование выполнения граф-схемы, а именно определяет узлы кластера, на которых будут выполняться процессы модулей Для того чтобы понять принципы взаимодействия данных сервисов, приведём
несколько сценариев:
Запуск граф-схемы: Пользователь инициирует команду запуска граф-схемы, которая передаётся на выполнение сервису выполнения. Этот сервис создаёт контекст выполнения граф-схемы. Контекст содержит идентификатор контекста и имя граф-схемы. Контекст необходим для того, чтобы пользователь имел возможность выполнять несколько граф-схем в системе.
Запись данных на висящие входы граф-схемы: Пользователь инициирует команду записи данных на висящие входы граф-схемы, которая перенаправляется сервису выполнения. Сервис выполнения определяет контекст выполнения и запрашивает у сервиса планирования узел кластера или компьютер, на котором должен располагаться буфер для данного модуля. На указанном узле или компьютере создаётся буфер и в него записываются данные. Данные действия выполняет сервис управления буферами на этом узле.
Запись данных в буфер: При записи данных сервис управления буферами проверяет наличие в буфере готовых кортежей данных. Если в буфере есть кортеж, данный сервис сообщает об этом сервису управления. После получения уведомления от сервиса управления
20
буферами о наличии готового кортежа данных, сервис выполнения запрашивает у сервиса планирования компьютер, на котором должен выполняться процесс для этого набора данных. Далее сети сервис выполнения запускает процесс модуля по соответствующей конъюнктивной группе входов.
Заключение
В настоящее время завершена разработка инструментальной среды и создан экспериментальный вариант программных средств для параллельного выполнения на кластерных системах.
Этот экспериментальный вариант системы управления реализован на языке программирования JAVA. Выбор языка Java обусловлен в первую очередь таким требованием к системе, как поддержка различных операционных систем. К плюсам данного языка программирования можно отнести поддержку параллельного программирования и синхронизации, а также простоту документирования системы. Минусом является то, что программы на языке Java работают медленнее, чем программы на таких языках программирования как C/C++. В дальнейшем предполагается перепрограммирование критических компонентов системы или всей системы на более “быстрых” языках программирования для нескольких популярных операционных систем, в частности для платформ Win32 и Unix/Linux.
Отметим, что средства описания потоковых вычислений, реализованные в ЯГСПП, уже эффективно использовались для построения программного обеспечения распределенных систем: гибких автоматизированных систем [22], систем управления военными действиями и др. По-видимому, они могут оказаться также вполне конкурентоспособными при реализации распределенных вычислений, представляемых в виде объектно-ориентированных программ. Для этого достаточно сравнить средства языка UML и ЯГСПП для описания параллельной и распределенной обработки информации.
Приложение 1. Примеры программ на ЯГСПП
1. Использование пространственного параллелизма
Построим ГСПП решения нелинейного уравнения x = aex +bx3 −c
 x методом простых ите-
x методом простых ите-
раций с заданной точностью ε и начальным приближением х0. ГС программы:
GenData
Генерация исх. данных
Mult1 |
Умножение a на ex |
Mult2
Умножение b на x3
Mult3
Умножение c на √x
CheckCond
Проверка критерия окончания вычислений
Output
Вывод результата
21
На ГС модуль GenData задает значения x0 и ε и передает их на входы модуля CheckCond, а значения a, b, c на входы модулей Mult1, Mult2, Mult3 соответственно. Начальное значение x0 передается на входы модулей
Mult1, Mult2, Mult3, CheckCond. Модули Mult1, Mult2, Mult3 перемножают передаваемые им данные и отправляют результаты на входы модуля CheckCond, который в свою очередь вычисляет новое приближение, когда сравнивает его со старым и, в зависимости от результата сравнения, либо передает полученный результат на следующую итерацию, либо результат передается модулю Output. В данном примере модули Mult1, Mult2, Mult3 являются информационно-независимыми и поэтому могут выполняться параллельно.
Описание подпрограмм каждого модуля на языке C:
Модуль GenData: void startup()
{
float data[5];
int place[5] = {1,2,3,4,5}; GenFloat(data[0],100); GenFloat(data[1],100); GenFloat(data[2],100); GenFloat(data[3],10); GenFloat(data[4],0.1); out(1,0,place,data);
}
void GenFloat(float &x,float p)
{
x=(float)rand()/(float)RAND_MAX; x*=p;
}
Модуль Mult1:
void Multiplication1(int tag,float x1,float x2)
{
float data[2]; data[0] = x1;
data[1] = x1*exp(x2);//вычисление а * ех int place[2] = {1,2};
out(1,0,place,data);
}
Модуль Mult2:
void Multiplication2(int tag,float x1,float x2)
{
float data[2]; data[0] = x1;
data[1] = x1*pow(x2,3); //вычисление b * х3 int place[2] = {1,2};
out(1,0,place,data);
}
Модуль Mult3:
void Multiplication3(int tag,float x1,float x2)
{
float data[2]; data[0] = x1;
data[1] = x1*pow(x2,0.5); //вычисление c * √x int place[2] = {1,2};
out(1,0,place,data);
}
Модуль CheckCond:
void Eval(int tag,float x1,float x2,float x3,float x4,float x5)
{
float xnew,data1[2],data2[1];
xnew = x2 + x3 - x4;//вычисление новой итерации int place1[2] = {1,2},place2[1] = {1}; if(fabs(xnew-x1)<x5)//проверяем критерий окончания
{
data1[0] = xnew; data1[1] = x5; out(1,0,place1,data1);
22
}
else
{
data2[0] = xnew; out(2,0,place2,data2);
}
}
void StartEval(int tag,float x1)
{
int place[1] = {1}; float data[1]; data[0] = x1; out(1,0,place,data);
}
Модуль Output:
void PrintRes(int tag,float x1)
{
printf(“Корень уравнения равен %d”,x1)
}
2. Использование параллелизма SIMD – применения одной программы к множеству различных данных
|
Пусть |
требуется |
организовать |
одновременное |
решение |
множества |
уравнений |
|||
x = a |
ex +b x3 |
−c |
|
|
(i=1,..,n) методом простых итераций с |
|
|
|
||
i |
x |
заданной |
точностью ε и |
начальным |
||||||
i |
i |
|
|
|
|
|
|
|
|
|
приближением х0.
Графическое и текстовое представления ГС в данном случае аналогично соответствующим представлениям в примере 1.
Т.к. в данном примере необходимо осуществить одновременное решение множества уравнений, воспользуемся механизмом тегирования данных. Для однозначной идентификации наборов данных будем сопоставлять с каждым набором уникальный тег, который будет «приклеен» к “порождаемым” в процессе вычислений данным. При межмодульном взаимодействии в процессе выполнения ГСПП, тег передается вместе с набором данных, который он идентифицирует.
Рассмотрим, как изменится описание подпрограмм каждого модуля, описываемых на языке C:
Модуль GenData: void startup()
{
float data[5];
int place[5] = {1,2,3,4,5};
//GenFloat – генерирует случайное вещественное число в промежутке от 1 до N GenFloat(data[0],100);
GenFloat(data[1],100);
GenFloat(data[2],100);
GenFloat(data[3],10);
GenFloat(data[4],0.1);
int TAG = GenTag(); //Генерируем новый уникальный тег
out(1,TAG,place,data); //Связываем тег с данными и передаем их на выход КГВых модуля
}
void GenFloat(float &x,float p)
{
x=(float)rand()/(float)RAND_MAX; x*=p;
}
Модуль Mult1:
void Multiplication1(int tag,float x1,float x2)
{
float data[2]; data[0] = x1;
data[1] = x1*exp(x2);//вычисление а * ех int place[2] = {1,2};
out(1,tag,place,data);//Выходные данные передаем с тем же тегом, с которым были получены входные данные
23
}
Модуль Mult2:
void Multiplication2(int tag,float x1,float x2)
{
float data[2]; data[0] = x1;
data[1] = x1*pow(x2,3); //вычисление b * х3 int place[2] = {1,2};
out(1,tag,place,data); //Выходные данные передаем с тем же тегом, с которым были получены входные данные
}
Модуль Mult3:
void Multiplication3(int tag,float x1,float x2)
{
float data[2]; data[0] = x1;
data[1] = x1*pow(x2,0.5); //вычисление c * √x int place[2] = {1,2};
out(1,tag,place,data); //Выходные данные передаем с тем же тегом, с которым были получены входные данные
}
Модуль CheckCond:
void Eval(int tag,float x1,float x2,float x3,float x4,float x5)
{
float xnew,data1[2],data2[1];
xnew = x2 + x3 - x4;//вычисление новой итерации int place1[2] = {1,2},place2[1] = {1}; if(fabs(xnew-x1)<x5)//проверяем критерий окончания
{
data1[0] = xnew; data1[1] = x5;
out(1,tag,place1,data1); //Выходные данные передаем с тем же тегом, с которым были получены входные данные
}
else
{
data2[0] = xnew;
out(2,tag,place2,data2); //Выходные данные передаем с тем же тегом, с которым были получены входные данные
}
}
void StartEval(int tag,float x1)
{
int place[1] = {1}; float data[1]; data[0] = x1;
out(1,tag,place,data); //Выходные данные передаем с тем же тегом, с которым были получены входные данные
}
Модуль Output:
void PrintRes(int tag,float x1)
{
printf(“Корень уравнения равен %d”,x1)
}
3. Использование потокового параллелизма
Следующий пример иллюстрирует использование потокового параллелизма в задаче нахождения
N
скалярного произведения двух N-мерных векторов (т.е. вычисления ∑aibi ). Предполагается, что в модуле i=1
GenN осуществляется задание значения N, которое передается на входы модулей GenA, GenB и Sum. Модули GenA и GenB генерируют значения ai и bi (i=1,..,n) соответственно, которые последовательно (асинхронно) передаются на входы модуля MultAB. Модуль MultAB перемножает поступающие «парные» значения ai и bi и передает результат на вход модуля Sum, который суммирует поступающие на вход значения. Модуль Output выводит результат. Этот пример интересен тем, как в нем посредством использования команды READ в модуле
24