

1.4. Современное положение дел
Со времени выхода GT200 развитиеGPUсделало большой шаг вперед. В 2013 году вышел чипGK11 0, который предложил усовершенствованную архитектуру и увеличенную производительность. В GT200 вместо блоковTPCиSMтеперь появились блоки нового поколения, называемыеSMX(NextGenerationStreamingMultiprocessor). АрхитектураSMXтребует дополнительного внимания (см. рис. 1.4).
Теперь, один SMXблок содержит 192 ядраCUDAконвейерной организации [3] (на рис. 1.4 обозначены зелёным цветом). Так же присутствуют 64 сопроцессораDPUnit(аналогFPU) для операций с числами с плавающей точкой двойной точности, согласно стандартуIEEE754-2008 (на рис. 1.4 обозначены желтым цветом). Как и прежде, присутствуют 32 специальных процессораSFUдля трансцендентных операций. К ним добавилось 32 блока инструкций получения/записи в память (Load/Store,LD/ST).

Рисунок 1.4. Потоковый мультипроцессор нового поколения (SMX)
Помимо этого, в SMXприсутствуют кэш инструкций, четыре планировщика и восемь диспетчеров исполнения команд. Все вычислительные блоки соединяются посредством шиныInterconnectNetworkс общей памятью и кэшемL1, общим объёмом 64Кб (об этом см. ниже), кэшем данных, объёмом 48Кб и текстурными блоками. КаждыйSMXсодержит 65536 32-битотвых регистров (для обозначения всех регистров используется терминRegisterFile).
Как видно, один потоковый мультипроцессор SMXимеет более сложную организацию, чем было вGPUпрошлых поколений, он сдержит гораздо больше ядерCUDAи других функциональных блоков. Поднимаясь на уровень выше, блокиSMXобъединяются на кристаллеGPUв количестве до 15 штук (см. рис. 1.5).

Рисунок 1.5. Устройство GPUGK110
15 потоковых мультипроцессоров дают в сумме 2880 ядер CUDA. Подсистема памятиGK110 включает кэшL2, объёмом 1536Кб, она подробно изображена на рис. 1.6:
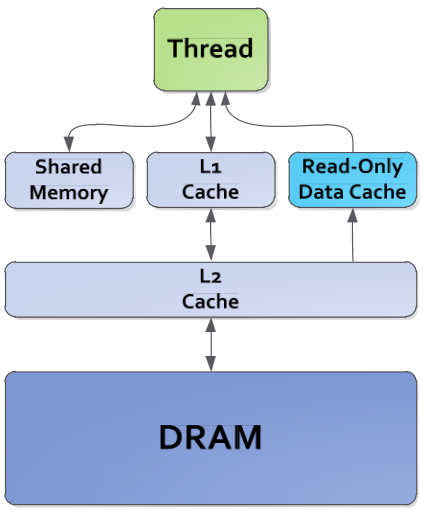
Рисунок 1.6. Подсистема памяти GPUGK110
На рис. 1.6 Threadобозначает одну нить (поток), создаваемую одним ядром;DRAM– память ускорителя (видеопамять). Рассмотрим элементы подсистемы памяти подробнее:
Общая память и кэш L1 (64Кб)
Архитектура GK110 подразумевает, что, как и в прошлом поколенииGPU(GF100), каждый мультипроцессорSMXобладает памятью 64Кб, которая может быть сконфигурирована, как 48Кб под общую память и 16Кб подL1 кэш, или, как 16Кб под общую память и 48Кб подL1 кэш. Новая архитектура обладает дополнительной гибкостью при конфигурировании памяти: по 32Кб под общую память иL1 кэш [3]. Так же увеличена пропускная способность по сравнению с предыдущим поколением.
Кэш данных “read-only” (48Кб)
В дополнение к L1 кэшу в мультипроцессоре имеется кэш, объёмом 48Кб, который доступен только для чтения. В прошлом поколении этот кэш был доступен только для текстурных блоков; это накладывало многие ограничения. ВGK110 в дополнение к увеличенному размеру кэша, он стал непосредственно доступен для мультипроцессораSMX.
Кэш L2 (1536Кб)
В GK110 размера кэшаL2 увеличился в два раза. КэшL2 является основной точкой унификации данных между блокамиSMX, обслуживанием инструкций получения/записи (Load/Store) и запросов текстурных блоков и обеспечением эффективного, высокоскоростного обмена данными по всемуGPU.
Завершая сказанное в этом подразделе, нужно упомянуть, что чип GK110 изготавливается по 28 нм техпроцессу и состоит из 7,1 миллиарда транзисторов, размер кристалла равен 551 мм2. В сравнительной таблице 1.1 собраны всё цифры, приведённые в этоvразделе. Будем рассматривать графический ускорительNVIDIAGTX275 в качестве ускорителя на базеGT200 и графический ускорительNVIDIAGTX780 Ti в качестве ускорителя на базеGK110:
Таблица 1.1.
Сравнение разных поколений графических ускорителей
|
Модель |
GTX 275 |
GTX 780 Ti |
|
GPU |
GT200 |
GK110 |
|
Ядра, шт |
240 |
2880 |
|
Частота ядер, МГц |
633 |
876 |
|
Размер памяти, Мб |
896 |
3072 |
|
Тип памяти |
GDDR3 |
GDDR5 |
|
Техпроцесс, нм |
55 |
28 |
|
Транзисторы, млрд шт |
1,4 |
7,1 |
|
Размер кристалла, мм2 |
470 |
551 |
|
Пиковая производительность для вычислений одинарной точности с плавающей точкой, ТФлопс |
1 |
5 |
|
Год выпуска |
2008 |
2013 |