

3.2. Результаты тестирования
Тестирование разработанной программной реализации проводилось на компьютере со следующей конфигурацией:
CPU – Intel Core2 Quad Q9550 (4 ядра, частота 2.83 Ггц);
ОЗУ – 4 Гб DDR3;
GPU – NVIDIA GTX275 (240 ядер CUDA, 896 Мб видеопамяти);
ОС – Windows8.1x64.
На рис. 3.2 приведены графики, полученные при решении трехдиагональной системы уравнений в следующих случаях:
синий график – зависимость времени выполнения параллельного алгоритма на графическом ускорителе от размерности системы. Память выделялась под все элементы матрицы A;
оранжевый график ‑ зависимость времени последовательного выполнения на хосте от размерности системы.
На графике, горизонтальная ось ограничена отметкой n=13500. Это связано с тем, что память графического ускорителя ограничена и выделить память под систему, размерностьюn≥14000 не представлялось возможным.
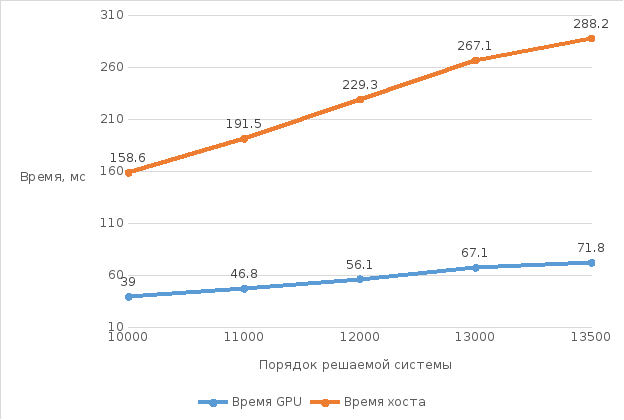
Рисунок 3.2. График зависимости времени выполнения метода блочной прогонки от порядка решаемой системы
Показатели загрузки памяти ускорителя приведены на графике на рис. 3.3.

Рисунок 3.3. График зависимости объёма используемой памяти от порядка решаемой системы
Данные на графике на рис. 3.3 получены утилитой TechPowerUpGPU‑Z, начальный показатель загрузки памяти ускорителя (до начала эксперимента) – 95 Мб, максимальный объём памяти ускорителя – 896 Мб.
В целях экономии памяти ускорителя и сокращения времени, затрачиваемого на передачу данных между хостом и ускорителем, была разработана улучшенная реализация, в которой память выделялась только под элементы на главной, нижней и верхней побочных диагоналей. Результаты тестирования приведены на рис. 3.4:

Рисунок 3.4. График зависимости времени выполнения улучшенной реализации от порядка решаемой системы для разных размеров блоков нитей
Согласно иерархии нитей в CUDA(см. 1.2.3), каждый блок – это массив нитей. Всё блоки, образующие сетку, имеют одинаковый размер. Количество блоков в сетке определяется следующим выражением:

Каждая нить обрабатывает одну полосу матрицы A. На рисунке 3.4:
Синий график – каждый блок состоит 128 нитей;
Оранжевый график – каждый блок состоит из 8 нитей.

Рисунок 3.5. График зависимости времени выполнения улучшенной реализации от порядка решаемой системы для разных размеров полосы матрицы
На рисунке 3.5 показана динамика роста времени решения системы при 128 нитях в каждом блоке для следующих случаев:
Синий график – ширина полосы матрицы составляет 16 строк;
Оранжевый график – ширина полосы матрицы составляет 32 строки;
Серый график – ширина полосы матрицы составляет 64 строки;
Зелёный график – ширина полосы матрицы составляет 128 строк;
Жёлтый график – ширина полосы матрицы составляет 256 строк;
Количество блоков нитей в каждом возможном варианте определяется формулой, описанной выше. Вот некоторые случаи на рисунке 3.5:
Порядок системы n=4014080, ширина полосыm=64, количество нитей в блокеnth=128, количество блоковnbl=4014080/64/128=490;
Порядок системы n=16056320, ширина полосыm=128, количество нитей в блокеnth=128, количество блоковnbl=16056320/128/128=980.
Исходя из данных на рис. 3.5. можно сделать выводы: чем больше ширина полосы (m>32), тем меньше число блоков нитей, тем хуже время решения; значениеm=32 является оптимальным, т.к. при дальнейшем уменьшении ширины полосы (m=16) наблюдается обратный эффект – увеличение времени решения. При размерностиn=2×106увеличение ширины полосыmоказывает слабый эффект на время решения.

Рисунок 3.6. График зависимости ускорения от ширины полосы матрицы для разных порядков решаемой системы
На
рисунке 3.6 представлен график ускорения
( )
при уменьшении ширины полосы. ЗаT1взято время решения при 1 блоке нитей
при минимальном числе нитей в блоке.
)
при уменьшении ширины полосы. ЗаT1взято время решения при 1 блоке нитей
при минимальном числе нитей в блоке.
Исходя из данных на рис. 3.6. можно сделать следующие выводы:
чем меньше ширина (256≤m≤32) полосы матрицы, тем больше число блоков нитей, и тем выше значение ускорения;
чем больше размерность решаемой задачи, тем выше загруженность GPUи тем выше значение ускорения;
существует некоторый оптимальный диапазон ширины полосы матрицы (от 16 до 64), на котором достигается максимальное ускорение для любой размерности системы.
Однако, при ширине полосы меньше 32 наблюдается снижение ускорения. При ширине полосы m=256 происходит неэффективное использование вычислительных ресурсов ускорителя, а приm=32 достигается наибольшее ускорение параллельного решения, особенно для размерностиn=16×106.
Данная реализация позволила добиться существенной экономии ресурсов, результаты измерения показаны на рис. 3.7. Показатель загрузки памяти ускорителя до начала эксперимента – 210 Мб.

Рисунок 3.7. График зависимости объёма используемой памяти от порядка решаемой системы в улучшенной реализации
Была исследована загруженность графического процессора (GPU) во время работы программы. Результаты приведены на рис. 3.8. Показания получены утилитойTechPowerUpGPU‑Z.
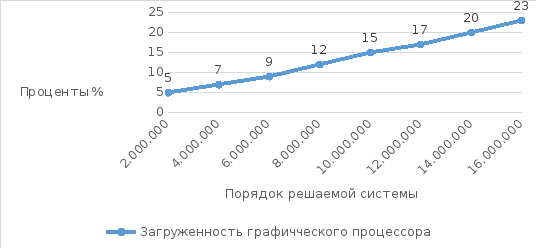
Рисунок 3.8. График зависимости пиковой загруженности графического процессора во время выполнения от порядка решаемой системы