

Практична частина.
А. Розробити програму паралельного розрахунку означеного інтеграла для функціїй у межах, що відповідають завданню в нижчеподаній таблиці 1. (варіант вибирається по двох останніх цифрах залікової книжки).
Б. Розробити паралельну програму множення матриць або сортування (варіант вибирається по передостанній цифрі залікової книжки, яку треба поділити на 2 та округлити):
1. Множення квадратної матриці на вектор.
2. Множення квадратної матриці на квадратну матрицю.
3. Сортування методом Шела.
4. Сортування пухирковим методом.
5. Сортування швидким методом.
Таблиця 1 (варіанти завдань)



Для кожної із задач практичної частини курсової роботи:
відповідно до варіанта підготувати постановку задачі, метод рішення;
розробити блок-схему алгоритму;
написати програму;
налагодити програму;
провести експериментальні розрахунки з різними вихідними даними;
привести в тексті розрахунково-пояснювальної записки результати виконання всіх кроків розробки (постановку, метод рішення, блок-схему, вихідні тексти програм, вихідні дані), отримані результати, по яких скласти:
таблицю й графік залежності часу розрахунку від кількості процесів і розмірності матриці (у задачі матричних розрахунків);
таблицю й графік залежності часу розрахунку від кількості процесів і від розмірності сортируємого масиву (у задачі сортування);
таблицю й графік залежності часу розрахунку від кількості процесів і від довжини кожного елементарного відрізка (у випадку розрахунку інтеграла методом прямокутників) і від кількості ітерацій (у випадку розрахунку інтеграла методом Монте-Карло);
побудувати графік функції в заданих межах;
зробити висновок з результатів проведених експериментів.
1 Класифікації та архітектури паралельних та розподілених компютерних систем
Основною класифікацією комп’ютерних систем є класифікація Флінна: комп’ютерні системи SISD, MISD, SIMD, MIMD.
SISD (single instruction stream single data stream) - одиночний потік команд і одиночний потік даних. До цього класу відносяться, перш за все, класичні послідовні машини, або інакше, машини фон-неймановского типу, наприклад, PDP-11 або VAX 11/780. У таких машинах є тільки один потік команд, всі команди обробляються послідовно одна за одною і кожна команда ініціює одну операцію з одним потоком даних. Немає значення той факт, що для збільшення швидкості обробки команд і швидкості виконання арифметичних операцій може застосовуватися конвеєрна обробка – як машина CDC 6600 зі скалярними функціональними пристроями, так і CDC 7600 з конвеєрними потрапляють у цей клас (рисунок 1.1).
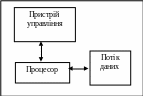
Рисунок 1.1 – Структурна схема класифікації комп’ютерних систем SISD
SIMD (single instruction stream multiple data stream) – одиночний потік команд і множинний потік даних (рисунок 1.2). У архітектурах подібного роду зберігається один потік команд, що включає, на відміну від попереднього класу, векторні команди. Це дозволяє виконувати одну арифметичну операцію відразу над багатьма даними - елементами вектора. Спосіб виконання векторних операцій не обмовляється, тому обробка елементів вектора може вироблятися або процесорною матрицею, як у ILLIAC IV, або за допомогою конвеєра, як, наприклад, у машині CRAY-1.

Рисунок 1.2 – Структурна схема класифікації
комп’ютерних систем SIMD
MISD (multiple instruction stream single data stream) – множинний потік команд і одиночний потік даних. Визначення має на увазі наявність в архітектурі багатьох процесорів, що обробляють один і той же потік даних (рисунок 1.3). Ряд дослідників відносять конвеєрні машини до даного класу, однак це не знайшло остаточного визнання в науковому співтоваристві.
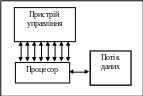
Рисунок 1.3 – Структурна схема класифікації
комп’ютерних систем MISD
MIMD (multiple instruction stream multiple data stream) – множинний потік команд і множинний потік даних (рисунок 1.4). Цей клас припускає, що в обчислювальній системі є кілька пристроїв обробки команд, об'єднаних в єдиний комплекс і працюючих кожний зі своїм потоком команд і даних [1].
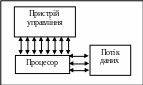
Рисунок 1.4 – Структурна схема класифікації
комп’ютерних систем MIMD
Коли йдеться про багатопроцесорні обчислювальні системи, крім продуктивності, необхідно назвати й інші їхні особливості. Насамперед це незвичайні архітектурні рішення, спрямовані на підвищення продуктивності. Поняття архітектури високопродуктивної системи досить широко, оскільки під архітектурою можна розуміти й спосіб паралельної обробки даних, використовуваний у системі, і організацію пам'яті, і топологію зв'язку між процесорами, і спосіб виконання системою арифметичних операцій.
Мультипроцесорна обробка використовується на суперЕОМ уже більше 30 років. Подібні системи складаються з набору спільно використовуваних запам'ятовувальних пристроїв і декількох центральних процесорів, що працюють під керуванням однієї копії операційної системи (ОС). Сучасні архітектури, як правило, складаються з декількох однорідних мікропроцесорів і масиву загальної пам'яті. Всі процесори в системі мають доступ до будь-якої крапки пам'яті (звичайно через шину й/або комутатор). За розпаралелювання процесів між процесорами відповідає ОС.
Донедавна симетричність в SMP ставилася до ролі процесорів у роботі ОС: малося на увазі, що всі процесори можуть «бачити» всю пам'ять і здатні виконувати будь-яке завдання, що їм призначає ОС. З появою технологій з неоднорідним доступом до пам'яті – NUMA (Non-Uniform Memory Access) виробникам комп'ютерного встаткування треба було провести розходження між системами з підтримкою NUMA і іншими серверними архітектурами. Загалом кажучи, NUMA – це архітектура пам'яті, використовувана в багатопроцесорних системах, де час доступу залежить від місцезнаходження пам'яті. Всі процесори можуть «бачити» всю пам'ять, але конкретний процесор працює із власною локальною пам'яттю набагато швидше, ніж з нелокальної, котра, у свою чергу, буде локальної для іншого процесора або розділяється між декількома процесорами. NUMA, як і SMP, дозволяє об'єднати обчислювальну потужність безлічі процесорів, кожний з яких звертається до загального пула пам'яті. Однак у цьому випадку для зв'язку процесорів один з одним вони організовані в невеликі групи, або вузли. Наприклад, 12-процесорний сервер може містити три вузли по чотирьох процесора. Кожний вузол має власний модуль пам'яті.
Оскільки в традиційних системах час доступу до всіх модулів пам'яті в серверах було однорідним або «симетричним», те такі системи позначалися і як «пам'ять із однорідним доступом» – UMA (Unified Memory Access), і як симетричні мультипроцесорні системи – SMP. Останній варіант одержав більше широке поширення. З погляду ОС, системи NUMA «симетричні», оскільки всі процесори мають рівні права, але з погляду апаратних характеристик їх не можна вважати SMP-системами.
SMP – симетрична багатопроцесорна архітектура. Головною особливістю систем з архітектурою SMP є наявність загальної фізичної пам'яті, що розділяється всіма процесорами.
Ключове поняття багатопроцесорних архітектур – вузол. Він являє собою обчислювальну систему, що складається з одного або декількох процесорів, що має оперативну пам'ять і систему уведення-виводу (рисунок 1.5). Вузол характеризується тим, що на ньому працює єдина копія ОС. Симетричний багатопроцесорний вузол містить два або більше однакових і рівноправних процесори. Всі процесори мають однаковий доступ до обчислювальних ресурсів вузлаЦП – центральний п.
Як база для побудови SMP-систем найчастіше використовуються три системних рішення: магістральна шина, масштабоване когерентне з'єднання й комутатор. Пам'ять служить, зокрема, для передачі повідомлень між процесорами, при цьому всі обчислювальні пристрої при зверненні до неї мають рівні має рацію і одну і ту ж адресацію для всіх елементів пам'яті. Тому SMP-архітектура називається симетричною.
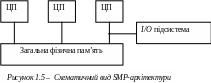
Остання обставина дозволяє дуже ефективно обмінюватися даними з іншими обчислювальними пристроями. SMP-система будується на основі високошвидкісної системної шини, до слотів якої підключаються функціональні блоки типів: процесори (ЦП), підсистема введення/виводу (I/O) і тому подібне. Для під'єднування до модулів I/O використовуються вже повільніші шини. Найбільш відомими SMP-системами є SMP-сервери і робочі станції на базі процесорів Intel.. Вся система працює під управлінням єдиною ОС, яка автоматично (в процесі роботи) розподіляє процеси по процесорах, але можлива і явна прив'язка.
Основні переваги SMP-систем:
простота і універсальність для програмування. Архітектура SMP не накладає обмежень на модель програмування, використовувану при створенні додатку: зазвичай використовується модель паралельних гілок, коли всі процесори працюють незалежно один від одного. Проте можна реалізувати і моделі, що використовують міжпроцесорний обмін. Використання загальної пам'яті збільшує швидкість такого обміну, користувач також має доступ відразу до всього об'єму пам'яті;
простота експлуатації. Як правило, SMP-системи використовують систему кондиціонування, засновану на повітряному охолоджуванні, що полегшує їх технічне обслуговування;
відносно невисока ціна.
Недолік SMP-систем:
системи із загальною пам'яттю погано масштабуються.
Цей істотний недолік SMP-систем не дозволяє вважати їх по-справжньому перспективними. Причиною поганої масштабованості є те, що в даний момент шина здатна обробляти тільки одну транзакцію, унаслідок чого виникають проблеми вирішення конфліктів при одночасному зверненні декількох процесорів до одних і тих же областей загальної фізичної пам'яті. Обчислювальні елементи починають один одному заважати. Коли відбудеться такий конфлікт, залежить від швидкості зв'язку і від кількості обчислювальних елементів. В даний час конфлікти можуть відбуватися за наявності 8-24 процесорів. Крім того, системна шина має обмежену хоч і високу пропускну спроможність і обмежене число слотів. Все це очевидно перешкоджає збільшенню продуктивності при збільшенні числа процесорів і числа користувачів, що підключаються. У реальних системах можна задіювати не більше 32 процесорів.
Для побудови систем, що масштабуються, на базі SMP використовуються кластерні або NUMA-архітектури. При роботі з SMP-системами використовують так звану парадигму програмування з пам'яттю, що розділяється.
MPP-архітектура.
MPP – масивно-паралельна архітектура. Головна особливість такої архітектури полягає в тому, що пам'ять фізично розділена. В цьому випадку система будується з окремих модулів, що містять процесор, локальний банк оперативної пам'яті (ОП), комунікаційні процесори (КП) або мережеві адаптери, іноді – жорсткі диски і/або інші пристрої введення/виводу.
По суті, такими модулями є повнофункціональні комп'ютери (рисунок 1.6). Доступ до банку ОП з даного модуля мають тільки процесори (ЦП) з цього ж модуля. Модулі з'єднуються спеціальними комунікаційними каналами. Користувач може визначити логічний номер процесора, до якого він підключений, і організувати обмін повідомленнями з іншими процесорами. Використовуються два варіанти роботи операційної системи (ОС) на машинах MPP-архітектури. У одному повноцінна операційна система працює тільки на машині, що управляє, на кожному окремому модулі функціонує сильно урізаний варіант ОС, що забезпечує роботу тільки розташованою в нім гілки паралельного застосування. У другому варіанті на кожному модулі працює повноцінна Linux подібна ОС, що встановлюється окремо.
Головною перевагою систем з роздільною пам'яттю є хороша масштабованість: на відміну від SMP-систем, в машинах з роздільною пам'яттю кожен процесор має доступ тільки до своєї локальної пам'яті, у зв'язку з чим не виникає необхідності в потактової синхронізації процесорів.
Практично всі рекорди по продуктивності на сьогодні встановлюються на машинах саме такої архітектури.
Н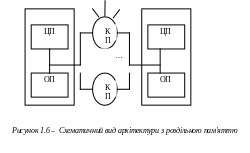 едоліки:
едоліки:
відсутність загальної пам'яті помітно знижує швидкість міжпроцесорного обміну, оскільки немає загального середовища для зберігання даних, призначених для обміну між процесорами. Потрібна спеціальна техніка програмування для реалізації обміну повідомленнями між процесорами;
кожен процесор може використовувати тільки обмежений об'єм локального банку пам'яті;
внаслідок вказаних архітектурних недоліків потрібні значні зусилля для того, щоб максимально використовувати системні ресурси. Саме цим визначається висока ціна програмного забезпечення для масивно-паралельних систем з роздільною пам'яттю.
Гібридна архітектура NUMA.
Головна особливість гібридної архітектури NUMA – неоднорідний доступ до пам'яті. Гібридна архітектура поєднує достоїнства систем із загальною пам'яттю і відносну дешевизну систем з роздільною пам'яттю. Суть цієї архітектури – в особливій організації пам'яті, а саме: пам'ять фізично розподілена по різних частинах системи, але логічно вона є загальною, так що користувач бачить єдиний адресний простір. Система побудована з однорідних базових модулів (плат), що складаються з невеликого числа процесорів і блоку пам'яті. Модулі об'єднані за допомогою високошвидкісного комутатора (рисунок 1.7).
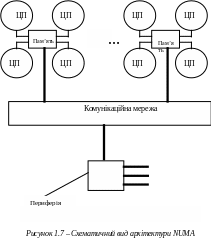
Підтримується єдиний адресний простір, апаратний підтримується доступ до видаленої пам'яті, тобто до пам'яті інших модулів. При цьому доступ до локальної пам'яті здійснюється у декілька разів швидше, ніж до видаленої. По суті, архітектура NUMA є MPP (масивно-паралельною) архітектурою, де як окремі обчислювальні елементи беруться SMP (симетрична багатопроцесорна архітектура) вузли. Доступ до пам'яті і обмін даними усередині одного SMP-вузла здійснюється через локальну пам'ять вузла і відбувається дуже швидко, а до процесорів іншого SMP-вузла теж є доступ, але повільніший і через складнішу систему адресації.
Структурна схема комп'ютера з гібридною мережею: чотири процесори зв'язуються між собою за допомогою кросбара в рамках одного SMP-вузла.
Організація когерентності багаторівневої ієрархічної пам'яті.
Поняття когерентності кеш-пам'яті описує той факт, що всі центральні процесори отримують однакові значення одних і тих же змінних у будь-який момент часу. Дійсно, оскільки кеш-пам'ять належить окремому комп'ютеру, а не всій багатопроцесорній системі в цілому, дані, що потрапляють в кеш одного комп'ютера, можуть бути недоступні іншому. Щоб цього уникнути, слід провести синхронізацію інформації, що зберігається в кеш-пам'яті процесорів.
Для забезпечення когерентності кешів існує декілька можливостей:
використовувати механізм відстежування шинних запитів, в якому кеші відстежують змінні, що передаються до будь-якого з центральних процесорів і при необхідності модифікують власні копії таких змінних;
виділяти спеціальну частину пам'яті, що відповідає за відстежування достовірності всіх використовуваних копій змінних.
Зазвичай вся система працює під управлінням єдиної ОС, як в SMP. Можливі також варіанти динамічного «підрозділу» системи, коли окремі «розділи» системи працюють під управлінням різних ОС. При роботі з NUMA-системами, так само, як з SMP, використовують так звану парадигму програмування із загальною пам'яттю.