

1.3 Формирование случайных чисел с заданным распределением
1.3.1 Основные процедуры формирования
Случайные
числа с заданным распределением, как
правило, формируются в результате
преобразования случайных р.р. чисел
![]() из диапазона от 0 до 1. В настоящее время
известно много процедур, позволяющих
имитировать непрерывные и дискретные
вероятностные распределения – метод
обратных функций, метод исключения,
метод композиции и т.д. Рассмотрим
содержание двух наиболее распространенных
на практике процедур.
из диапазона от 0 до 1. В настоящее время
известно много процедур, позволяющих
имитировать непрерывные и дискретные
вероятностные распределения – метод
обратных функций, метод исключения,
метод композиции и т.д. Рассмотрим
содержание двух наиболее распространенных
на практике процедур.
П р о ц е д у р а 1 (для непрерывных распределений).
Пусть
имитации подлежит непрерывная случайная
величина
![]() ,
которая описывается плотностью
распределения
,
которая описывается плотностью
распределения![]() .
Плотность распределения
.
Плотность распределения![]() связана
с функцией распределения
связана
с функцией распределения![]() соотношением
соотношением
![]() (6)
(6)
Известно, что если случайная величина ξ имеет функцию распределения F(x), то распределение случайной величины y=Fξ(ξ) равномерно в интервале от 0 до 1.
На
этом положении базируется метод обратных
функций, который гласит, что если взять
случайное р. р. число
![]() и найти соответствующее ему число
и найти соответствующее ему число![]() ,
которое определяется уравнением
,
которое определяется уравнением
![]() (7)
(7)
то
полученное случайное число
![]() будет иметь функцию распределения
будет иметь функцию распределения![]() .
.
Для практической реализации метода обратных функций требуется разработать машинный алгоритм. Процесс его разработки состоит в последовательном выполнении следующих операций.
1.
На основе соотношения (6) осуществляется
переход от плотности распределения
![]() к функции распределения
к функции распределения![]() .
.
2. Составляется исходное уравнение (7).
3.
Данное уравнение решается относительно
![]() .
.
В результате решения исходного уравнения получаем искомый машинный алгоритм
![]() (8)
(8)
где
![]() - функция, обратная по отношению к функции
- функция, обратная по отношению к функции![]() .
.
П р о ц е д у р а 2 (для дискретных распределений).
Пусть
имитации подлежит дискретная случайная
величина
![]() ,
которая описывается рядом распределения
,
которая описывается рядом распределения
![]() где
где
![]()
По
сути в основе данной процедуры лежит
метод обратных функций. Для имитации
значения дискретной случайной величины
![]() используется случайное р. р. число
используется случайное р. р. число![]() на интервале [0,1].
на интервале [0,1].
Очевидно, что в этом случае
P(0 ≤ R < p1) = p1;
P(p1≤ R < p1 + p2 ) = p2;
P(p1+ p2 ≤ R < p1 + p2 + p3) = p3;
. . .
P(p1+ p2 + ...+ pn-1 ≤ R < p1+ p2 + ...+ pn ) = pn;
Машинный
алгоритм, имитирующий значение дискретной
случайной величины![]() ,
работает следующим образом. Прежде
всего, берется случайное р. р. число
,
работает следующим образом. Прежде
всего, берется случайное р. р. число![]() .
Затем проверяется логическое условие:
.
Затем проверяется логическое условие:
![]() (9)
(9)
где k принимает целочисленные значения, возрастающие от 1 до n.
При некотором k условие (9) начинает выполняться. Это определяет имитируемое значение xk - дискретной случайной величины X.
1.3.2 Имитация равномерного распределения
Равномерное
распределение непрерывной случайной
величины
![]() описывается плотностью распределения
описывается плотностью распределения

![]()
Математическое
ожидание и дисперсия случайной величины
![]() определяется соотношениями
определяется соотношениями
![]() и
и
![]()
Получим машинный алгоритм для имитации равномерного распределения, используя метод обратных функций:

Формула (10) представляет собой искомый машинный алгоритм.
1.3.3 Имитация гауссовского распределения
Гауссовское распределение является одним из наиболее распространенных непрерывных распределений. Гауссовская аппроксимация реального распределения используется обычно в следующих случаях:
1) когда реальное распределение обусловлено теми факторами, которые определяются центральной предельной теоремой теории вероятности;
2) когда реальное распределение известно, однако допускается его гауссовская аппроксимация с целью упрощения решаемой задачи;
3) когда реальное распределение неизвестно, однако нет каких-либо оснований отвергать его гауссовскую аппроксимацию.
Гауссовское
распределение непрерывной случайной
величины
![]() описывается плотностью распределения:
описывается плотностью распределения:

где
![]() и
и![]() - соответственно математическое ожидание
и среднее квадратическое отклонение
гаусовского распределения.
- соответственно математическое ожидание
и среднее квадратическое отклонение
гаусовского распределения.
Машинный алгоритм для имитации гауссовского распределения можно получить, базируясь на центральной предельной теореме. Эта теорема утверждает, что сумма независимых, случайных величин с произвольными распределениями имеет асимптотически гауссовское распределение. Сходимость к гауссовскому распределению осуществляется наиболее быстро, если суммируются величины с одинаковым распределением. В этом случае даже небольшое число слагаемых приводит к гауссовскому распределению.
В
основе машинного алгоритма для имитации
гауссовского распределения лежит
суммирование случайных р.р. чисел![]() .
.
![]()
С
возрастанием
![]() ,
т.е. числа суммируемых случайных р.р.
чисел
,
т.е. числа суммируемых случайных р.р.
чисел![]() ,
повышается точность имитации гауссовского
распределения. Обычно
,
повышается точность имитации гауссовского
распределения. Обычно![]() выбирают в пределах от 6 до 12. При этом
достаточная для многих приложений
точность обеспечивается при использовании
всего шести случайных р.р. чисел
выбирают в пределах от 6 до 12. При этом
достаточная для многих приложений
точность обеспечивается при использовании
всего шести случайных р.р. чисел![]() .
Для случая, когда
.
Для случая, когда![]() = 6,
= 6,
![]()
Формула
(11) представляет собой искомый машинный
алгоритм, который наиболее часто
используется на практике. С помощью
этого алгоритма имитируется гауссовская
случайная величина
![]() с заданным статистическими параметрами
с заданным статистическими параметрами![]() и
и![]() .
.
1.3.4. Имитация экспоненциального распределения
Экспоненциальное
распределение непрерывной случайной
величины
![]() описывается плотностью распределения
описывается плотностью распределения

где
![]() - параметр экспоненциального распределения.
- параметр экспоненциального распределения.
Математическое
ожидание и дисперсия случайной величины
![]() определяются соотношениями
определяются соотношениями
![]() и
и
![]() .
.
Получим машинный алгоритм для имитации экспоненциального распределения, используя метод обратных функций:
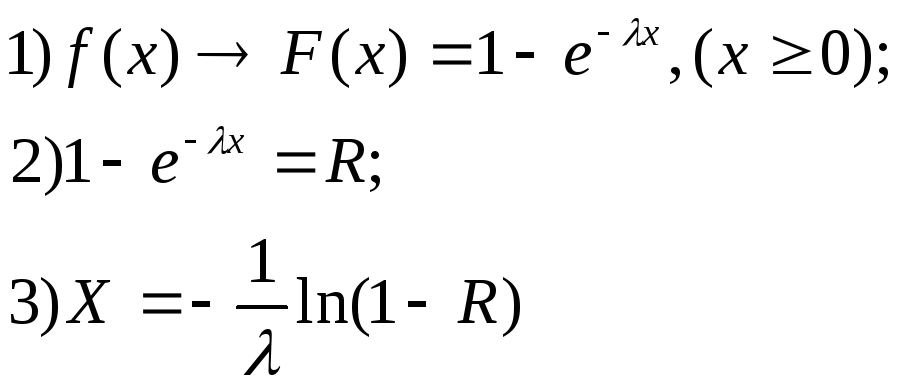
или
![]() (12)
(12)
Формула (12) представляет собой искомый машинный алгоритм.
1.3.5 Имитация гамма-распределения
Гамма-распределение
непрерывной случайной величины
![]() описывается плотностью распределения:
описывается плотностью распределения:

где
![]() и
и![]() - параметры гамма-распределения (η>0,λ>0)).
- параметры гамма-распределения (η>0,λ>0)).
При η, принимающем целочисленные значения, гамма-распределение называется распределением Эрланга.
Математическое
ожидание и дисперсия случайной величины
![]() определяются соотношениями
определяются соотношениями
![]() и
и
![]() .
.
Гамма-распределение
сводится к экспоненциальному распределению,
если положить
![]() .
Случайная величина
.
Случайная величина![]() может быть представлена в виде суммы
независимых случайных величин
может быть представлена в виде суммы
независимых случайных величин![]() i,
имеющих экспоненциальное распределение:
i,
имеющих экспоненциальное распределение:
![]() .
.
Получим машинный алгоритм для имитации гамма-распределения.
![]()
или
![]() (13)
(13)
где
![]() случайные р. р. числа
случайные р. р. числа![]() .
Формула (13) представляет собой искомый
машинный алгоритм.
.
Формула (13) представляет собой искомый
машинный алгоритм.
1.3.6. Имитация треугольного распределения
Треугольное
распределение непрерывной случайной
величины
![]() описывается
плотностями распределения:
описывается
плотностями распределения:
 (14)
(14)
или
 (15)
(15)
Для
имитации треугольного распределения
может быть использован метод исключения,
предложенный И.Нейманом. Сущность метода
исключения выражается следующей
теоремой: если взять два случайных р.
р. числа
![]() и
и![]() ,
и использовать их для получения пары
чисел
,
и использовать их для получения пары
чисел
![]() и
и
![]() ,
то случайное число
,
то случайное число
![]() будет иметь плотность распределения
будет иметь плотность распределения![]() при условии:
при условии:
![]()
Машинные алгоритмы для имитации треугольного распределения разрабатываются на основе изложенной теоремы. Рассмотрим эти алгоритмы.
Машинный алгоритм для имитации треугольного распределения с плотностью (14).
1.
Формируются два случайные р. р. числа
![]() и
и![]() .
.
2.
Проверяется условие
![]() .
Если условие выполняется, то исходное
искомое число
.
Если условие выполняется, то исходное
искомое число
![]() .
.
В
противном случае, пара чисел
![]() отбрасывается и осуществляется переход
к шагу 1.
отбрасывается и осуществляется переход
к шагу 1.
Машинный алгоритм для имитации треугольного распределения с плотностью (15).
1.
Формируются два случайных р. р. числа
![]() и
и![]() .
.
2.
Проверяется условие
![]() .
Если условие выполняется, то находится
искомое число
.
Если условие выполняется, то находится
искомое число
![]() .
.
В
противном случае пара чисел
![]() отбрасывается и осуществляется переход
к шагу 1.
отбрасывается и осуществляется переход
к шагу 1.
Приведенные
алгоритмы имеют существенный недостаток:
часть пар чисел
![]() ,
приходится отбрасывать. Принимая во
внимание независимость случайных р. р.
чисел
,
приходится отбрасывать. Принимая во
внимание независимость случайных р. р.
чисел![]() и
и![]() ,
можно предложить более экономичные
алгоритмы, основанные на использовании
следующих формул:
,
можно предложить более экономичные
алгоритмы, основанные на использовании
следующих формул:
![]() (16)
(16)
![]() (17)
(17)
где
![]() - взятие максимального числа из
совокупности двух случайных р. р. чисел
- взятие максимального числа из
совокупности двух случайных р. р. чисел![]() и
и![]() ;
;
![]() -
взятие минимального числа на совокупности
двух случайных р. р.чисел
-
взятие минимального числа на совокупности
двух случайных р. р.чисел
![]() и
и![]() .
.
Формулы (16) и (17) представляют собой машинные алгоритмы для имитации треугольного распределения с плотностями соответственно (14) и (15).
1.3.7 Имитация распределения Симпсона
Распределение
Симпсона непрерывной случайной величины
![]() описывается плотностью распределения
описывается плотностью распределения


Распределение
Симпсона имеет случайная величина
![]() ,
которая представляет собой следующую
сумму:
,
которая представляет собой следующую
сумму:
X = y+z , (18)
где
![]() и
и![]() - независимые случайные величины,
распределенные равномерно на интервале
- независимые случайные величины,
распределенные равномерно на интервале![]() .
Следовательно, распределение Симпмсона
можно рассматривать как композицию
двух одинаковых законов равномерного
распределения.
.
Следовательно, распределение Симпмсона
можно рассматривать как композицию
двух одинаковых законов равномерного
распределения.
Машинный
алгоритм для имитации распределения
Симпсона базируется на применении
формулы (18). Согласно этой формуле
необходимо получить два случайных числа
![]() и
и![]() ,
распределенных равномерно на интервале
,
распределенных равномерно на интервале![]() ,
и просуммировать их. Найденное таким
образом число
,
и просуммировать их. Найденное таким
образом число![]() будет иметь распределение Симпсона.
будет иметь распределение Симпсона.
1.4. Оценка вероятностных характеристик
Процесс решения задачи методом статистического моделирования включает следующие операции:
1) получение реализации случайного явления;
2) получение массива реализаций случайного явления;
3) получение оценок вероятностных характеристик случайного явления.
Получение оценок связано с обработкой массива реализаций, который формируется в результате монтекарловских испытаний. В большей части практических случаев выполняется построение либо гистограммы распределения (для непрерывных распределений), либо статистического ряда (для дискретных распределений). Рассмотрим соответствующие алгоритмы.
Построение гистограммы распределения состоит в последовательном выполнении следующих этапов.
1.
Находится минимальное
![]() и максимальное
и максимальное![]() значения массива реализаций.
значения массива реализаций.
2. Определяется размах варьирования
![]()
3. Определяется длина интервала
![]()
где
![]() - число интервалов в пределах размаха
варьирования
- число интервалов в пределах размаха
варьирования![]()
![]()
4.
Определяются граничные значения для
каждого
![]() -го
интервала
-го
интервала
![]()
5.
Фиксируется количество попаданий
![]() в каждый
в каждый![]() -й
интервал
-й
интервал
![]()
6. Вычисляются ординаты гистограммы распределения
![]()
где
![]() - число выполненных испытаний (объем
массива реализаций).
- число выполненных испытаний (объем
массива реализаций).
Построение статистического ряда состоит в последовательном выполнении следующих этапов [3].
1.
Находится минимальное значение
![]() массива реализаций,
массива реализаций,
2.
Определяется количество появлений
![]() этого значения в массиве реализаций.
этого значения в массиве реализаций.
3.
Все значения
![]() удаляются из массива реализаций.
удаляются из массива реализаций.
4. Выполняется переход к шагу 1,
5. Работа алгоритма заканчивается, если в массиве реализаций нет ни одного числа.
6. Вычисляются частоты статистического ряда
![]()
где
![]() - число разрядов статистического ряда
(число различных значений
- число разрядов статистического ряда
(число различных значений![]() );
);
![]() -
суммарное количество появлений случайной
величины.
-
суммарное количество появлений случайной
величины.
Ответим
на следующие вопросы: к каким ошибкам
может привести замена параметра a
его точечной оценкой
![]() ,
с какой степенью уверенности можно
ожидать, что эти ошибки не выйдут за
известные пределы.
,
с какой степенью уверенности можно
ожидать, что эти ошибки не выйдут за
известные пределы.
Пусть
для параметра а
из опыта получена несмещенная оценка
![]() .
Назначим достаточно большую вероятность
.
Назначим достаточно большую вероятность![]() и найдем такое значение
и найдем такое значение![]() ,
для которого
,
для которого
![]() ; (1)
; (1)
Тогда
диапазон возможных значений ошибки при
замене
![]() на
на![]() будет
будет![]() .
Большие по абсолютной величине ошибки
будут появляться только с малой
вероятностью
.
Большие по абсолютной величине ошибки
будут появляться только с малой
вероятностью![]() ;
выражение (1) можно представить в виде,
более соответствующем самому механизму
испытания.
;
выражение (1) можно представить в виде,
более соответствующем самому механизму
испытания.
![]() (2)
(2)
Фактически
имеет место либо точка
![]() (случайная, но полученная в результате
опыта), и оценивается вероятность того,
что отрезок
(случайная, но полученная в результате
опыта), и оценивается вероятность того,
что отрезок![]() покроет точку
покроет точку![]() ,не
являющуюся случайной.
,не
являющуюся случайной.
Вероятность
![]() называется доверительной вероятностью,
интервал
называется доверительной вероятностью,
интервал![]() - доверительным интервалом,
- доверительным интервалом,![]() - доверительными границами.
- доверительными границами.

Рассмотрим
задачу нахождения доверительного
интервала для математического ожидания.
Пусть произведено
![]() - независимых опытов над случайной
величиной
- независимых опытов над случайной
величиной![]() ,
характеристики которой
,
характеристики которой![]() и
и![]() - неизвестны. Для этих параметров получены
оценки
- неизвестны. Для этих параметров получены
оценки

 (3)
(3)
Воспользуемся
центральной, предельной теоремой,
согласно которой при
![]() закон распределения суммы одинаково
распределенных случайных величин близок
к нормальному. Характеристики этого
закона для величины
закон распределения суммы одинаково
распределенных случайных величин близок
к нормальному. Характеристики этого
закона для величины![]() равны
равны![]() -мат. ожидание и
-мат. ожидание и![]() -дисперсия.
-дисперсия.
Предположим,
что величина
![]() исходной последовательности нам
известна. Тогда
исходной последовательности нам
известна. Тогда
![]()
можно записать в виде
![]() (4)
(4)
где
![]()
интеграл
вероятностей, соответствующий функции
нормального распределения при
![]() и
и![]() .
.
В формуле (4)
![]() -
среднее квадратическое отклонение
оценки
-
среднее квадратическое отклонение
оценки
![]()
Из
уравнения
![]() находим значение
находим значение![]() :
:
![]() (5)
(5)
Так
как мы не знаем действительного значения
дисперсии
![]() и соответственно величины
и соответственно величины
![]()
![]() ,
то в качестве приближенного значения
используем оценку
,
то в качестве приближенного значения
используем оценку
![]() (3).
(3).
Чтобы избежать вычислений по (5), составим таблицы функций
![]() (6)
(6)
![]() для
нормального закона дает числа
для
нормального закона дает числа
![]() ,которые
нужно отклонить вправо и влево от
,которые
нужно отклонить вправо и влево от![]() ,
чтобы вероятность попадания в полученный
участок была
,
чтобы вероятность попадания в полученный
участок была![]() .Через
.Через![]() доверительный интервал вычисляется
так:
доверительный интервал вычисляется
так:
![]()
Этот
интервал накрывает точку
![]() с вероятностью
с вероятностью![]() в результате обработки
в результате обработки![]() - сигналов.
- сигналов.
Таблица
функции
![]() :
:
Таблица 2
|
|
0,80 |
0,81 |
0,82 |
0,83 |
0,84 |
0,85 |
0,86 |
0,87 |
0,88 |
0,89 |
0,90 |
|
|
1,282 |
1,310 |
1,340 |
1,371 |
1,404 |
1,439 |
1,475 |
1,513 |
1,554 |
1,597 |
1,643 |
|
|
0,91 |
0,92 |
0,93 |
0,94 |
0,95 |
0,96 |
0,97 |
0,98 |
0,99 |
0,9973 |
0,999 |
|
|
1,694 |
1,750 |
1,810 |
1,880 |
1,960 |
2,053 |
2,169 |
2,325 |
2,576 |
3,000 |
3,290 |
Аналогичным образом может быть построен доверительный интервал для дисперсии. Вернемся к оценкам
 и
и

Величина
![]() - представляет собой сумму
- представляет собой сумму![]() - слагаемых и при увеличении
- слагаемых и при увеличении![]() ее распределение также стремится к
нормальному. Так как оценка
ее распределение также стремится к
нормальному. Так как оценка![]() несмещенная, то
несмещенная, то
![]()
Вычисление дисперсии достаточно сложно, поэтому приведем сразу конечную формулу:
![]() ,
,
![]() ,
,
где
![]() ,
-четвертый центральный момент величины
,
-четвертый центральный момент величины![]() .Его можно заменить оценкой
.Его можно заменить оценкой

![]() -
можно заменить его оценкой
-
можно заменить его оценкой
![]() .
.
В
случае, когда можно предположить, что
распределение
![]() нормально или близко к нормальному, для
вычисления
нормально или близко к нормальному, для
вычисления![]() можно использовать формулу
можно использовать формулу

Доверительный интервал вычисляется по формуле
![]()