

Базы данных, знаний и экспертные системы Калабухов ЕВ, БГУИР 2007 (Мет пособие)
.pdfРисунок 31. Выполнение запроса с обобщающими функциями (см. исходные данные на рисунке 29).
Следует заметить, что в списке возвращаемых столбцов таких запросов нельзя одновременно указывать статистическую функцию и обычные имена столбцов, поскольку при этом СУБД не может сформировать таблицу – противоречия в структуре (одно значение и столбец значений).
5.1.3.1.4. Группирующие запросы (секция GROUP BY)
Запрос, включающий в себя предложение GROUP BY, называется запросом с группировкой, поскольку он объединяет строки исходных таблиц в группы и для каждой группы строк генерирует одну строку в таблице результатов запроса. Столбцы, указанные в предложении GROUP BY, называются столбцами группировки (возможно указание нескольких столбцов
– группировка по комбинации значений), поскольку именно они определяют, по какому признаку строки делятся на группы.
Ограничения на синтаксис группирующих запросов и особенности выполнения:
1)Столбцы с группировкой должны представлять собой реальные столбцы таблиц, перечисленных в предложении FROM. Нельзя группировать строки на основании значения вычисляемого выражения.
2)Все имена столбцов, приведенные в описании SELECT должны обязательно присутствовать и в секции GROUP BY. Это означает, что возвращаемым столбцом может быть:
141
•константа;
•статистическая функция, возвращающая одно значение для всех строк, входящих в группу;
•столбец группировки, который по определению имеет одно и то же значение во всех строках группы;
•выражение, включающее в себя перечисленные выше элементы.
3)Если совместно с GROUP BY используется WHERE, то WHERE обрабатывается первым, а группированию подвергаются только те строки, которые удовлетворяют условию фильтра. По ISO, NULL-значения входят в одну группу.
Для фильтрации данных группы по заданным условиям используется подгруппа HAVING, которая в условиях отбора может использовать агрегатные функции (что запрещено делать в секции фильтра WHERE!). Кроме того, в HAVING нельзя записывать просто имена полей, не используемых в GROUP BY, т.к. эти данные будут представлять множество значений и сравнение с ними констант и множеств констант не возможно.
Пример группирующего запроса:
SELECT column2, COUNT(*), COUNT(column3), AVG(column1) FROM t1
WHERE (column1 > 0.4)
GROUP BY column2 HAVING (COUNT(column3) > 1);
На логическом уровне данный запрос выполняется следующим образом:
1)Для всех строк таблицы t1 выполняется фильтрация по предикату
(column1 > 0.4).
2)Данные, прошедшие фильтр WHERE, по столбцу column2 делятся на группы, по одной группе для каждого значения из column2.
3)Для каждой группы вычисляется COUNT(*), COUNT(column3), AVG(column1) по всем строкам, входящим в группу, и генерируется одна итоговая строка результатов. К этой строке будет дописано соответствующее значение из column2.
142
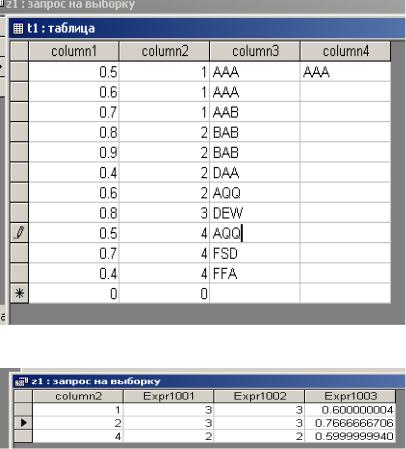
4) Полученные результаты (данные групп) будут профильтрованы по предикату (COUNT(column3) > 1) в секции HAVING.
а) исходные данные
б) результат выполнения запроса Рисунок 32. Выполнение группирующего запроса.
5.1.3.1.5. Секция ORDER BY – сортировка результатов запроса
Секция ORDER BY определяет упорядоченность результатов по столбцам. Первый столбец в списке называется главным ключом и определяет общую упорядоченность строк результирующей таблицы. Последующие столбцы в списке сортировки определяют дополнительное упорядочивание в общей упорядоченности. Порядок сортировки данных столбца задается после имени столбца: ASC – сортировка по возрастанию значений (используется по
143
умолчанию); DESC – сортировка по убыванию значений. По ISO, NULLзначения либо наибольшие, либо наименьшие (на усмотрение разработчиков СУБД).
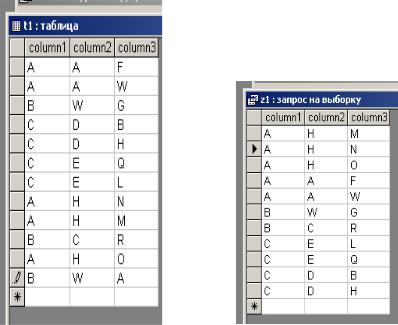
Пример использования сортировки: SELECT *
FROM t1
ORDER BY column1, column2 DESC, column3;
а) исходные данные |
б) результат выполнения запроса |
Рисунок 33. Сортировка данных. |
|
5.1.3.1.6. Подзапросы
Подзапросы – запросы с помощью оператора SELECT, помещенные в секции WHERE и (или) HAVING внешнего оператора SELECT. Подзапрос создает временную таблицу, содержимое которой извлекается и обрабатывается внешним оператором (обычно предикатом внешнего запроса). Текст подзапроса должен быть заключен в круглые скобки и располагается всегда в правой части операции внешнего запроса. В подзапросах не должна
144
использоваться секция ORDER BY.
Подзапрос играет важную роль в SQL по трем следующим причинам:
•инструкция SQL с подзапросом зачастую является самым естественным способом выражения запроса, так как она лучше всего соответствует словесному описанию запроса.
•подзапросы облегчают написание инструкции SELECT, поскольку они позволяют разбивать запрос на части (на основной запрос и подзапросы).
•существуют запросы, которые нельзя сформулировать на SQL иначе как с помощью подзапросов.
Подзапрос может вернуть следующее число значений:
•ничего,
•одно значение (ячейка),
•столбец значений (множество),
•таблицу значений (несколько столбцов). Обработка данных вариантов обычно следующая:
1)При возврате одного значения обычно используются операторы сравнения (но для большей устойчивости запросов желательно '=' заменять на 'IN' (соответственно, ‘<>’ на NOT IN), т.к. запрос может не вернуть ни одного значения; кроме того, в подзапросах желательно использовать обобщающие функции, которые всегда возвращают одно значение). Например:
SELECT * FROM t1
WHERE number > (SELECT AVG(rating) FROM t2);
2)При возврате множества значений (одного столбца) используется сравнение на принадлежность к множеству ('IN'), а также операторы ANY и ALL, которые используются как кванторы совместно с операторами сравнения. Для ANY(SOME) условие верно тогда, когда хоть одно значение, которое вернул подзапрос, удовлетворяет условию. Для ALL – условие верно только тогда, когда все значения, которые вернул подзапрос, удовлетворяют условию. Например:
SELECT * FROM t1
145
WHERE number IN (SELECT number FROM t2);
SELECT * FROM t1
WHERE number <= ANY (SELECT number FROM t2);
SELECT * FROM t1
WHERE number > ALL (SELECT number FROM t2);
Со всеми указанными конструкциями можно использовать логическое отрицание - NOT.
3) При возврате подзапросом таблицы (множество столбцов) можно проверить только факт наличия данных с помощью оператора EXISTS (если подзапрос ничего не возвращает, то результат EXISTS - ложь). Например:
SELECT * FROM t1
WHERE EXISTS (SELECT * FROM t2);
Нет смысла использовать EXISTS, если подзапрос построен с помощью обобщающей функции, которая всегда возвращает значение. Можно изменить логику проверки EXISTS и использовать форму NOT EXISTS.
Обычно внешний и внутренний подзапросы ничем не связаны, однако есть случаи, когда подзапрос должен использовать данные из внешнего запроса, такие подзапросы называются соотнесенными. Например, найти данные о фирмах, которые имеют филиалы в городе ‘Minsk’ (при этом БД состоит из отношений t1 {firm, boss, about} и t2 {firm, city, branch_address}):
SELECT * FROM t1 A
WHERE ‘Minsk’ IN (SELECT city FROM t2 B WHERE A.firm = B.firm);
Данный запрос работает следующим образом:
1)берется строка таблицы для внешнего запроса (строка-кандидат);
2)подзапрос выполняется, используя данные из строки-кандидата;
3)производится оценка условия для внешнего запроса
146
4) переход к следующей строке таблицы.
Большинство запросов являются "двухуровневыми" и состоят из главного запроса и подзапроса. Однако, как внутри главного запроса может находиться подзапрос, то внутри подзапроса может находиться еще один подзапрос, называемый в таком случае вложенным. Стандарт ANSI/ISO не определяет максимальное число уровней вложенности, но на практике с ростом их числа очень быстро увеличивается время выполнения запроса. Когда запрос имеет более двух уровней вложенности, он становится трудным для чтения и понимания. Во многих СУБД количество уровней вложенности запросов ограничено относительно небольшим числом.
5.1.3.1.7. Многотабличные запросы
Для выборки значений из нескольких таблиц БД используются многотабличные запросы. В многотабличных запросах используются операции соединения таблиц и, соответственно, в основе всех многотабличных запросов лежит операция декартово произведение.
Процедура выполнения многотабличного запроса состоит в следующем:
1)выполняется секция FROM (формируется декартово произведение таблиц и выполняется соответствующее соединение (если это задано синтаксисом секции FROM));
2)выполняется секция WHERE;
3)выполняется секция GROUP BY … HAVING;
4)выполняется секция SELECT (формируются результирующие строки);
5)выполняется секция ORDER BY.
Виды соединений таблиц (соответствуют видам соединений из реляционной алгебры):
1) Декартово произведение двух таблиц: SELECT t1.*, t2.*
147
FROM t1, t2;
2)Тета-соединение таблиц (используются знаки сравнения, на практике используется редко, так как трудно найти смысл соединения):
SELECT * FROM t1, t2
WHERE (t1.number > t2.number);
3)Экви-соединение таблиц (выполняется по равенству значений общего атрибута, например значений первичного и внешнего ключа):
SELECT t1.*, t2.* FROM t1, t2
WHERE (t1.number = t2.number);
или эквивалентный вариант соединения (inner или natural join): SELECT t1.*, t2.*
FROM t1 INNER JOIN t2 ON (t1.number = t2.number);
4)Внешние соединения таблиц (левое, правое и полное, соответственно): SELECT t1.*, t2.*
FROM t1 LEFT JOIN t2 ON t1.number = t2.number;
SELECT t1.*, t2.*
FROM t1 RIGHT JOIN t2 ON t1.number = t2.number;
SELECT t1.*, t2.*
FROM t1 FULL JOIN t2 ON t1.number = t2.number;
Кроме приведенных выше соединений, есть различные нестандартные применения многотабличных запросов, например найти все пары студентов имеющих один и тот же рейтинг (запрос формируется для одной таблицы t1):
148
SELECT A.name, B.name, A.rating FROM t1 A, t1 B
WHERE A.rating = B.rating;
Здесь псевдоним существует только на время выполнения SELECT.
C увеличением количества таблиц в запросе резко возрастает объем работы, необходимой для выполнения запроса. Хотя ограничений на количество объединяемых таблиц нет, на практике высокие затраты на обработку многотабличных запросов во многих приложениях накладывают серьёзные ограничения на использование многотабличных запросов. В запросах, для которых время выполнения критично, число используемых таблиц обычно не превышает трех.
5.1.3.2. Операторы UNION, INTERSECT и EXCEPT
Операции UNION (объединение), INTERSECT (пересечение) и EXCEPT (разность) представляют собой операции над множествами элементов, которые рассмотрены в реляционной алгебре. Данные операции позволяют комбинировать результаты двух и более запросов в единую результирующую таблицу.
Формат записи операторов следующий: (SELECT …)
operator [ALL] [CORRESPONDING [BY {column1 [, …]}]] (SELECT …)
Здесь:
•(SELECT …) – подзапросы, возвращающие данные для выполнения оператора; таблицы сформированные этими подзапросами длжны быть совместимы по соединению – т.е. они должны иметь одну и ту же структуру (смысл данных должен поддерживаться пользователем);
•operator – один из поддерживаемых (UNION, INTERSECT, EXCEPT
149
(MINUS));
•ALL – при указании в результирующей таблице будут оставлены дубликаты строк (по умолчанию дубликаты строк удаляются);
•CORRESPONDING – операция выполняется для общих столбцов таблиц (если указан список столбцов, то операция выполняется для указанных столбцов); Например:
(SELECT * FROM student1) UNION CORRESPONDING name (SELECT * FROM student2);
5.1.3.3.Операторы изменения содержимого БД
Коператорам модификации данных относятся операторы INSERT (вставка), UPDATE (изменение) и DELETE (удаление).
5.1.3.3.1. Добавление (вставка) новых данных в таблицу
Наименьшей единицей информации, которую можно добавить в реляционную базу данных, является одна строка. Новые данные можно добавлять только в одну таблицу.
ВРСУБД существует два способа добавления новых строк в базу данных:
1)Однострочная инструкция INSERT позволяет добавить в таблицу одну новую строку. Этот вариант широко используется в повседневных приложениях, например в программах ввода данных, и имеет формат:
INSERT INTO table_name [(column_list)] VALUES (data_value_list)
Здесь, table_name – имя таблицы или обновляемого представления.
150