

Базы данных, знаний и экспертные системы Калабухов ЕВ, БГУИР 2007 (Мет пособие)
.pdfметодом последовательного перебора), который имеет большой объем, поиск проще проводить в индексе с использованием метода бинарного поиска. Тогда выборка одной записи данных с помощью индекса состоит из следующих шагов:
•быстрый поиск записи в индексе, которая содержит искомый ключ;
•выборка записи из файла данных по найденному адресу записи.
Сиспользованием индекса возможно также выполнение последовательного доступа к данным, отсортированным по ключу индекса. Например, выбрать всех сотрудников, фамилии которых начинаются на букву «И», в этом случае движение по индексу (перебор соседних записей индекса, которые имеют значения в заданном интервале) позволяет обращаться к записям файла данных в указанном порядке.
Основной недостаток использования индексов – замедление обновления файла данных, т.к. при добавлении новой записи в файл данных требуется обновление индекса, а индекс представляет собой упорядоченный последовательный файл и обновляется медленно.
Индексы можно классифицировать следующим образом: 1) по виду используемых полей записи данных:
•первичный индекс – индекс, построенный на основе поля первичного ключа данных; такой индекс всегда один, значение ключа индекса уникально; введение первичного индекса позволяет хранить данные в неупорядоченном последовательном файле;
•вторичный индекс – индекс, построенный не по первичному ключу, позволяет ускорить операции выборки для запросов, выполняющих фильтрацию не по полям первичного ключа; вторичных индексов может быть несколько (однако следует помнить, что чем больше индексов у файла данных, тем медленнее вставка в него данных – вторичные индексы должны строиться только для самых критичный и часто выполняемых запросов); значения ключей в индексе могут повторяться. 2) по числу используемых полей записи данных:
111
•несоставной – ключ индекса состоит только из одного поля записи;
•составной – ключ индекса состоит из нескольких полей записи, при этом сортировка ключа индекса выполняется в следующем виде: основной порядок сортировки задает первое поле ключа, дополнительный порядок сортировки (сортировка в группе) задает второе поле ключа, и т.п; составной индекс по полям записи (f1,f2,f3,…,fn) может использоваться для поиска по полю f1 либо по комбинациям полей (f1, f2), (f1, f2, f3), (f1, f2, f3, f4), …, (f1,f2,f3,…,fn-1), (f1,f2,f3,…,fn) – т.е. один составной индекс может обслуживать ряд запросов, но поля используемые при этом должны располагаться с начала ключа индекса (т.к. они зададут порядок сортировки записей индекса) и без разрывов; для N полей записи максимальное число индексов определяется как
CNn = |
N! |
|
, |
|
n!*(N − n)! |
||||
|
|
|||
где n – целое число равное N/2 (округление при перевод в целое число производится здесь в большую сторону).
3)по числу ссылок на данные:
•плотный – число индексных записей равно числу записей данных, одна индексная запись ссылается только на одну запись данных;
•неплотный – число индексных записей меньше числа записей данных, индекс указывает либо на первую запись в определенной группе, либо на страницу с определенной группой записей данных, записи данных при этом также должны быть упорядочены по некоторому полю. Например, если список сотрудников упорядочен по фамилии, то можно построить неплотный индекс, которых будет в качестве ключа содержать первую букву фамилии, и этот индекс будет ссылаться на записи данных следующим образом: «А» -> на первую фамилии в списке начинающуюся на «А», «Б» -> на первую фамилии в списке начинающуюся на «Б», и т.п. Поиск конкретного сотрудника по фамилии тогда можно осуществить следующим образом:
112
а) найти букву, на которую начинается фамилия сотрудника; б) выполнить поиск фрагмента файла данных, отвечающего за
размещение фамилий начинающихся на данную букву, с использованием неплотного индекса; в) выполнить поиск в этом фрагменте файла данных (либо
последовательным перебором, либо используя упорядоченность по фамилии для бинарного поиска).
АА
АБ
ААВ
Б …
…БА
ЯББ
…
ЯА
АААААБ
|
ААБ |
|
|
|
ААВ |
|
|
|
|
|
|
|
|
|
ААВ |
|
|
|
АБА |
|
|
|
|
|
|
|
|
…АВА
|
АБА |
|
|
|
ААА |
|
|
|
|
|
|
|
|
|
АББ |
|
|
|
АББ |
|
|
|
|
|
|
|
|
|
АБВ |
|
|
|
АВБ |
|
|
|
|
|
|
|
|
…ЯАА
|
АВА |
|
|
|
БАА |
|
|
|
|
|
|
|
|
|
АВБ |
|
|
|
АБВ |
|
|
|
|
|
|
|
|
|
АВВ |
|
|
|
БАБ |
|
… АВВ
АВВ
|
БАА |
|
|
|
… |
|
|
|
|
|
|
|
|
|
БАБ |
|
|
|
… |
|
|
|
|
|
|
|
|
|
… |
|
|
|
… |
|
|
|
|
|
|
|
|
|
ЯАА |
|
|
|
… |
|
|
|
|
|
|
|
|
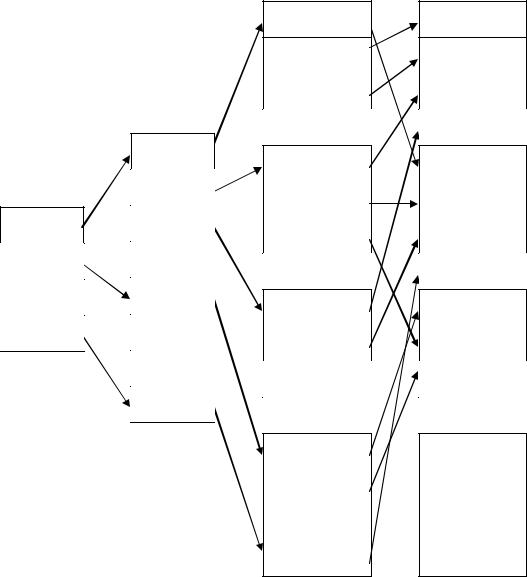
3-ий уровень |
2-ой уровень |
1-ый уровень |
Данные |
Рисунок 22. Многоуровневый индекс.
113
4) по числу уровней индекса;
•одноуровневый – индекс, который непосредственно ссылается на данные, а не на другие индексные структуры;
•многоуровневый – индекс, состоящий из нескольких индексных файлов, при этом только индекс первого уровня ссылается на реальные данные (обычно это плотный индекс), а индексы более высоких уровней ссылаются на предыдущие уровни (эти индексы обязательно неплотные). Структура многоуровневого индекса за счет увеличения объема данных позволяет сократить время поиска записей, т.к. данные уже разбиты на фрагменты, которые бы получались, например, в результате бинарного поиска. Многоуровневый индекс вводится при наличии в файле данных большого числа записей, обычно при условии, что бинарный поиск в одноуровневом плотном индексе проводится за значительное число шагов. Поиск данных в многоуровневом индексе начинается с самого верхнего уровня и продолжается пока не будет достигнута запись данных, поиск ссылки на следующий уровень на текущем уровне проводится методом двоичного поиска в определенном диапазоне. На практике, число уровней многоуровневого индекса обычно не превышает трех.
Особым типом многоуровневых индексов являются древовидные
индексы. Рассмотрим одну из разновидностей древовидных индексов – B+- деревья.
Дерево, как структура индексов, состоит из иерархии узлов, в которой каждый узел за исключением корня, имеет родительский узел, а также этот узел может ссылаться на дочерние узлы. Узел, не имеющий дочерних узлов, называется листом дерева. Глубиной дерева называется максимальное количество уровней между корнем дерева и листьями дерева. Если глубина дерева одинакова для всех листов, то такое дерево называется сбалансированным или B-деревом. Степень или порядок дерева – максимально допустимое количество дочерних узлов для каждого родительского узла (за
114
исключением листьев).
B+-дерево представляет собой сочетание B-дерева (сбалансированного неплотного древовидного индекса) и плотного индекса (листовой уровень, который дополнительно упорядочен). Правила определения B+-дерева:
1)если корень не является листовым узлом, то он должен иметь, по крайней мере, два дочерних узла;
2)в дереве порядка n каждый узел (за исключением корня и листов) должен иметь от n/2 до n указателей и дочерних узлов, если число n/2 не является целым, то оно округляется до ближайшего большего целого числа;
3)в дереве порядка n количество ключевых значений в узле должно находиться в пределах от (n-1)/2 до (n-1), если число (n-1)/2 не является целым, то оно округляется до ближайшего большего целого числа;
4)количество ключевых значений в нелистовом узле на единицу меньше количества указателей;
5)дерево всегда должно быть сбалансированным;
6)листья дерева должны быть связаны в порядке возрастания ключевых значений.
На практике, каждый узел в дереве является страницей (4 Кб), порядок дерева равен 512, число ярусов (уровней) дерева равно трем, тогда:
1-ый уровень (корень дерева) имеет максимум 512 ссылок на дочерние
узлы;
2-ой уровень имеет 262144 (512 узлов * 512 ссылок) ссылок на дочерние
узлы;
3-ий уровень имеет 133955584 (262144 узлов * 511 ссылок) ссылок на страницы данных;
Доступ к одной записи данных в такой структуре осуществляется за четыре обращения к диску (1-ый уровень, 2-ой уровень, 3-ий уровень, непосредственные данные).
Для поддержки сбалансированности дерева применяется специальный алгоритм, который работает при вставке и удалении записей данных.
115
Рассмотрим этот алгоритм с точки зрения изменения индекса (добавления нового ключа) при вставке данных:
1)на самом низком уровне набора индексов нужно найти узел N, с которым будет связано вставляемое значение ключа V; поиск узла N осуществляется также, как поиск записи по известному ключу – двигаясь от корня до листа по ссылкам, для которых выполняется условие «значение текущего ключа в текущем узле меньше или равно значению V»;
2)если узел N содержит свободное пространство для ключа V, то значение V вставляется в него (с учетом упорядоченности значений ключей) и процесс вставки завершается, в противном случае выполняется разделение узла N да два узла N1 и N2 (причем, все упорядоченное множество значений (2n+1 значений) ключей узла N также разделяется на две части – n первых значений этой последовательности будут помещены в N1, n последних – в N2, а среднее между ними значение W будет помещено в родительский элемент P на более высоком уровне (для листьев значение W будет сохранено в узле N1, т.к. листья это плотный индекс)); в дальнейшем, при выполнении поиска значения u и достижения P, поиск будет перенаправлен в сторону N1, если U ≤W , либо в сторону N2, если U > W ;
3)Далее процесс повторяется для вставки значения W в узел P; процесс разделения элементов структуры может идти вплоть до корневого узла (с образованием нового иерархического уровня).
Удаление записи – процесс обратный вставке, может вести к удалению уровня дерева. Изменение данных обычно выполняется как удаление старого значения и вставка нового значения.
Формирование B+-дерева рассмотрим на следующем примере:
Дано: требуется произвести вставку ключей 41, 37, 14, 3, 5, 20 (в указанном порядке) в дерево порядка 3 (узел состоит из трех указателей и двух ключей).
Выполнение по шагам:
1)вставка ключа 41 – формирование первого узла дерева (корня дерева, и
116
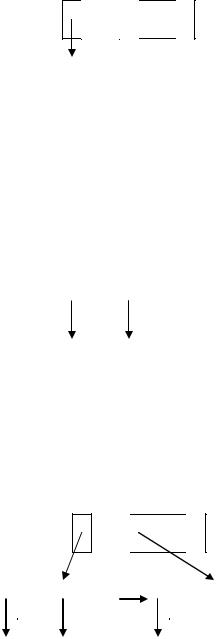
он же одновременно - лист);
41 - 
 -
-
Рисунок 23. Вставка ключа 41.
2) вставка ключа 37 – значения в листе упорядочиваются по возрастанию значений ключей (плотный индекс), перед каждым ключом расположен указатель на страницу с данными;
|
37 |
|
41 |
- |
|
|
|
|
|
Рисунок 24. Вставка ключа 37.
3) вставка ключа 14 – корневой узел заполнен полностью – выполняется разделение узла и формируется новый корень;
37 
 -
-
|
14 |
|
37 |
|
|
|
41 |
- |
|
- |
|
|
|
|
|
|
|
|
|
|
|
Рисунок 25. Вставка ключа 14.
4) вставка ключа 3 – листовой узел заполнен полностью – выполняется разделение узла;
117

14 
 37
37
|
3 |
|
14 |
|
|
|
37 |
- |
|
|
|
|
41 |
- |
|
- |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рисунок 26. Вставка ключа 3.
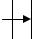
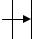
5) вставка ключа 5 – листовой узел заполнен полностью – выполняется разделение узла и формирование нового родительского уровня, т.к. корневой уровень тоже заполнен;
14 
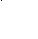
 -
-
|
5 |
|
|
- |
|
|
37 |
|
|
- |
|
|
|
|
|
|
|
|
|
|
|
3 
 5
5 

 14 -
14 - 

 37 -
37 - 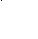

 41 -
41 - 
 -
-
Рисунок 27. Вставка ключа 5.
6) вставка ключа 20 – поиск места дает свободное место - не требуется расширения;
|
|
14 |
|
5 |
- |
37 |
- |
3 
 5
5 
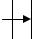
 14 -
14 - 

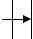
 20
20 
 37
37 
 41 -
41 - 
 -
-
Рисунок 28. Вставка ключа 20.
118
Процесс вставки ключей закончен, получено сбалансированное дерево, состоящее из трех уровней.
119
5. ЯЗЫКИ БАЗ ДАННЫХ
5.1. SQL
5.1.1. Общие сведения
SQL (Structured Query Language) – язык реляционных баз данных,
который в настоящее время имеет очень широкое распространение.
В1974 г. Д.Чамберлин (работал вместе с Е.Ф.Коддом в лаборатории IBM
вСан-Хосе, США) опубликовал определение языка SEQUEL (Structured English Query Language). В 1976 г. вышла переработанная версия языка – SEQUEL/2, в последствии из юридических соображений это название было изменено на SQL, поэтому в ходу остались два варианта произношения «си-кью-эл» и «эс-кью- эл».
Тестовая версия SQL входила в состав экспериментальной реляционной СУБД «System R». В 1981 г. IBM объявила о своем первом, основанном на SQL программном продукте – SQL/DS. Чуть позже к ней присоединились ORACLE
идругие производители РСУБД.
В1982 г. ANSI (американский национальный институт стандартов) начал работу над языком RDL (Relation Database Language). В работе над этим языком были использованы разработки языка SQL корпорации IBM. В 1983 г. К разработке языка подключился ISO (международный комитет по стандартизации). В процессе разработки название языка было заменено на SQL, первый стандарт которого вышел в 1987 г. Этот вариант языка был подвергнут критике со стороны разработчиков реляционной модели данных (отсутствие ссылочной целостности, недостаточное число операторов, чрезмерная избыточность языка), но стандарт был принят для развития основы языков реляционных БД. В 1992 г. вышла обновленная версия языка - SQL-92 или
120