

Классификация нелинейных функций.
различают два класса нелинейных регрессий:
регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам. Примером этого класса моделей могут служить полиномы разных степеней у = а + вх + сх2; у = а + вх + сх2+ dх3, а также равносторонняя гипербола
у = в + а/х.
нелинейные регрессии по оцениваемым параметрам:
степенная у = а хв
показательная у = а вх
экспоненциальная у = е а+ вх.
Первый класс моделей (нелинейных по переменным) не таит каких-либо сложностей в оценке ее параметров. Она определяется, как и в линейной регрессии, методом наименьших квадратов (МНК), ибо эти функции линейны по параметрам. Так, в параболе у = а + вх + сх2 , заменяя переменные х1=х, а х2=х2 , получаем двухфакторное уравнение линейной регрессии у = а + вх1 + сх2. Соответственно для полинома третьего порядка получим трехфакторную модель линейной регрессии и так далее. Следовательно, полином любого порядка сводится к линейной регрессии с ее методами оценивания параметров. Среди нелинейной полиномиальной регрессии чаще всего используется парабола второй степени, в отдельных случаях – полином третьего порядка. Ограничения в использовании полиномов более высоких степеней связаны с требованием однородности совокупности: чем выше порядок полинома, тем больше изгибов имеет кривая и, соответственно, тем менее однородна совокупность по результативному признаку.
Для равносторонней гиперболы мы можем заменить 1/х на z и получим линейное уравнение регрессии, оценка параметров которого может быть дана МНК.
Иначе обстоит дело со вторым классом моделей, то есть с регрессией, нелинейной по оцениваемым параметрам. Данный класс нелинейных моделей можно разделить на два типа: а) нелинейные модели внутренне линейные и б) нелинейные модели внутренне нелинейные.
Если модель внутренне линейна, то она с помощью соответствующих преобразований может быть приведена к линейному виду. Пример – степенная функция у = а хв. Данная модель нелинейна относительно оцениваемых параметров, так как включает параметры а и в неаддитивно. Однако ее можно считать внутренне линейной, ибо логарифмирование данного уравнения приводит его к линейному виду. Соответственно оценки параметров а и в могут быть найдены МНК.
Внутренне нелинейной будет модель вида у = а + вхс, так как ее невозможно превратить в линейный вид никакими преобразованиями переменных.
Как и в парной зависимости, возможны разные виды уравнений множественной регрессии: линейные и нелинейные. Ввиду четкой интерпретации параметров уравнения наиболее широко используются линейные и степенные функции. Линейная модель в форме является аддитивной. Это означает, что в основе модели лежит гипотеза о том, что каждый фактор что-то добавляет или отнимает от значения результативного признака. Например, если у – это урожайность сельскохозяйственной культуры, а х1, х2 и х3 – агротехнические факторы: дозы удобрений, число прополок, поливов и т.п., то каждый из этих факторов либо повышает, либо понижает величину урожайности, причем последняя могла бы существовать и без этих факторов.
Однако аддитивная модель пригодна не для любых связей в экономике. Если, например, изучается зависимость объема продукции предприятия от занимаемых площадей, числа работников, стоимости основных фондов (или всего капитала), то каждый из факторов является необходимым для существования результата, а не добавлением к нему. В таких ситуациях нужно исходить из гипотезы о мультипликативной форме модели:

Такая модель по ее первым создателям получила название модель Кобба-Дугласа. Это степенная функция и, как мы уже знаем, показатели степени при факторах являются коэффициентами эластичности. Они показывают, на сколько процентов изменяется в среднем результат с изменением соответствующего фактора на 1 процент при неизменности других факторов. Решение степенной функции методом наименьших квадратов требует предварительной ее линеаризации. Как было рассмотрено ранее (лекция 4), линеаризация степенных функций проводится с помощью логарифмирования ее переменных.
Степенные множественные функции часто используются как производственные функции, где результатом выступают объемы производства, а факторами – используемые ресурсы (трудовые ресурсы, основные производственные фонды, машины, текущие затраты и т.п.). Экономический смысл здесь имеют не только коэффициенты эластичности по каждому фактору, но и их сумма
B = b1+b2
Эта величина фиксирует обобщенную характеристику эластичности производства (показывает, на сколько процентов в среднем увеличиваются объемы производства при увеличении всех факторов на 1%).
Возможны и другие линеаризуемые функции для построения уравнения множественной регрессии. Например,
экспонента

или
гипербола

Стандартные компьютерные программы обработки регрессионного анализа позволяют перебирать различные функции и выбирать ту из них, для которой остаточная дисперсия и ошибка аппроксимации минимальные. Однако следует помнить, что чем сложнее сама функция, тем менее интерпретируемы ее параметры. При сложных полиномиальных функциях необходимо соблюдать соотношение между числом объясняющих переменных и объемом совокупности. Так, полином второй степени с двумя факторами
y = a + b1x1 + b2x2 +b11x12+ b22 x2 2+ b12x1x2
требует не менее 40-50 наблюдений.
Уравнение нелинейной регрессии, так же как и в линейной зависимости, дополняется показателем тесноты связи, а именно – индексом корреляции R
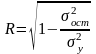 (4.18)
(4.18)
где
 -общая дисперсия результативного
признака;
-общая дисперсия результативного
признака;
 -
остаточная дисперсия.
-
остаточная дисперсия.
Учитывая связь дисперсии с объемом вариации, можно легко доказать, что индекс корреляции через объемы вариации определяется следующим образом:

Индекс детерминации используется для проверки существенности уравнения нелинейной регрессии в целом по F-критерию Фишера
F
=
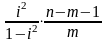 (4.20)
(4.20)
где п – число наблюдений;
т – число параметров при переменных х.
9. Эконометрическое моделирование одномерных и многомерных временных рядов
Временной ряд – это совокупность значений какого-либо показателя за несколько последовательных моментов (периодов) времени. Реальные данные временного ряда могут складываться при одновременном влиянии трех перечисленных компонент, факторы уровней временного ряда по характеру воздействия можно условно разбить на три группы:
факторы, формирующие тенденцию ряда (Т);
факторы, формирующие циклические колебания ряда (S);
случайные факторы (E).
В большинстве случаев фактический уровень временного ряда можно представить как сумму или произведение трендовой, циклической и случайной компонент. Модель, в которой временной ряд представлен как сумма компонент, называется аддитивной. Модель, в которой временной ряд представлен как произведение перечисленных компонент, называется мультипликативной. Основная задача эконометрического исследования отдельного временного ряда – выявление и придание количественного выражения каждой из перечисленных выше компонент, с тем чтобы использовать полученную информацию для прогнозирования будущих значений ряда.
Процесс построения модели включает в себя следующие шаги:
1. Выравнивание исходного ряда методом скользящей средней
2. Расчет значений сезонной компоненты
3. Устранение сезонной компоненты из исходных уровней ряда и получение выравненных данных (Т+Е) в аддитивной модели или (Т*Е) в мультипликативной модели.
4. Аналитическое выравнивание уровней (Т+Е) или (Т*Е) и расчет значений Т с использованием поученного уравнения тренда.
5. Расчет полученных по модели значений (Т+S) или (Т*S)
6. Расчет абсолютных и/или относительных ошибок. Если полученные значения ошибок не содержат автокорреляции, ими можно заменить исходные уровни ряда и в дальнейшем использовать временной ряд ошибок E для анализа взаимосвязи ряда и других временных рядов.
Выбор между аддитивной моделью и мультипликативной осуществляется на основе анализа изменения амплитуды колебаний (если в динамике амплитуда колебаний увеличивается или уменьшается, то мультипликативная модель).
Прогнозное значение уровня временного ряда в аддитивной модели - это сумма трендовой и сезонной компонент (по тренду, подставив в уравнение tn , определяем значение T и складываем с соответствующим этому tn значением сезонной компоненты S).
Прогнозное значение временного ряда в мультипликативной модели – это произведение трендовой и сезонной компонент. Для определения T используем уравнение тренда и умножаем на соответствующее прогнозируемому периоду значение сезонной компоненты S.
Изучение взаимосвязи экономических переменных по данным временных рядов осложнено тем, что в этих рядах может быть тенденция. Если в ряду динамики переменной у и в ряду динамики х есть компонента «Т», то в результате мы получим тесную связь между у и х. Однако из этого факта еще нельзя делать вывод о том, что изменение х есть причина изменения у, то есть что между этими изменениями есть причинно-следственная связь.
Чтобы выявить причинно-следственную зависимость между переменными, необходимо устранить ложную корреляцию между ними, вызванную наличием тенденции.
Существует
несколько способов исключения тенденции
в рядах динамики. Первый способ называется
метод отклонений от тренда. Пусть имеется
уt=
Т + е и хt=
Т + е. Проводится аналитическое выравнивание
каждого ряда:
 и
и
 ,
где Ту
и Тх
– это оценки трендовых компонент. Затем
определяется остаток в каждом наблюдении
,
где Ту
и Тх
– это оценки трендовых компонент. Затем
определяется остаток в каждом наблюдении
 и
и
 ,
так
как остаточная компонента не содержит
тенденции. Далее изучается зависимость
между самими остатками еу=f(ех).
Если между переменными есть связь, то
она проявится в согласованном изменении
остатков. Недостатком данного способа
является то, что содержательная
интерпретация параметров такой модели
затруднительна. Однако модель может
быть использована для прогнозов и, кроме
того, коэффициент парной корреляции
между остатками отразит связь переменных.
,
так
как остаточная компонента не содержит
тенденции. Далее изучается зависимость
между самими остатками еу=f(ех).
Если между переменными есть связь, то
она проявится в согласованном изменении
остатков. Недостатком данного способа
является то, что содержательная
интерпретация параметров такой модели
затруднительна. Однако модель может
быть использована для прогнозов и, кроме
того, коэффициент парной корреляции
между остатками отразит связь переменных.
Второй
способ преодоления тенденции в рядах
динамики – это метод последовательных
разностей. Если временной ряд содержит
ярко выраженную линейную тенденцию, то
для ее устранения можно заменить исходные
уровни разностями первого порядка, то
есть цепными абсолютными приростами:
 и
и
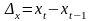 .
Далее прирост у рассматривается как
функция прироста х:
.
Далее прирост у рассматривается как
функция прироста х:
 .
.
Третьим способом является включение в модель регрессии фактора времени: yt= a+b1x1+ b2 t. В данном случае коэффициенты чистой регрессии легко интерпретируются, имеют естественные единицы измерения. Коэффициент b1 покажет на сколько единиц изменится результат при единичном изменении фактора при условии существования неизменной тенденции; коэффициент b2 отразит влияние всех прочих факторов, формирующих тенденцию, кроме x1. Однако данный способ построения регрессионной модели требует большего объема наблюдений, так как в модели появляется еще один параметр.